



TurboDiffusion将视频生成从漫长的渲染等待变成了实时的所见即所得。
清华、生数科技与伯克利联手解开了视频扩散模型的速度枷锁。

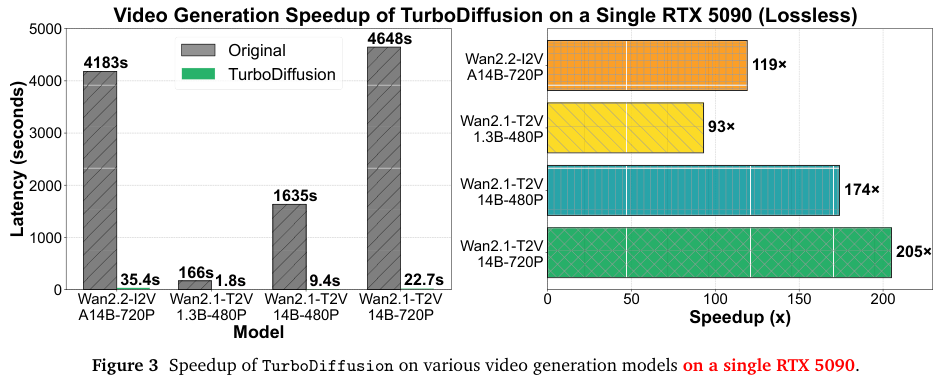
加速后的Wan2.1-T2V-1.3B-480P,单显卡1.8秒生成5秒视频,加速约93倍。

Wan2.2-I2V-A14B-720P,5秒视频加速约119倍。

Wan2.1-T2V-14B-720P,5秒视频加速约205倍。

视频生成一直以来始终像一个沉重的巨人,它拥有惊人的创造力,却步履蹒跚。
这种延迟并非算力不够强大,而是现有视频扩散模型的计算复杂度天然地构筑了一道高墙。
TurboDiffusion通过一套精密的组合拳,在保持视频质量几乎无损的前提下,将推理速度提升了100到205倍。
稀疏、蒸馏与全链路量化
视频生成之所以慢,本质上是一个计算量爆炸的数学问题。
与图像生成不同,视频不仅仅是二维像素的堆叠,它还增加了一个时间维度。
当你要求模型生成一段视频时,它不仅要处理每一帧画面的空间细节,还要计算帧与帧之间的时间连贯性。
目前的视频扩散模型,大多基于Transformer架构。
在标准的注意力机制中,计算复杂度是呈二次方增长的。如果视频的分辨率提高一倍,或者帧数增加一倍,计算量并不是简单的翻倍,而是呈指数级暴涨。
TurboDiffusion解决速度问题的第一个切入点,是对Transformer中注意力机制(Attention)进行了改造。
研究团队引入了两种核心技术:SageAttention和可训练的稀疏线性注意力(Sparse-Linear Attention, SLA)。
在传统的计算中,神经网络的参数和激活值通常使用16位浮点数(FP16)甚至32位浮点数(FP32)来存储和计算。SageAttention及其变体SageAttention2++,采用了一种极为激进但精准的量化策略,将注意力计算中的关键矩阵操作压低到了8位甚至更低的精度。
稀疏线性注意力(SLA)则改变计算的路径,引入了一种可训练的稀疏机制,它让模型学会只看重点。
通过将全量注意力替换为稀疏线性注意力,计算复杂度降低到了线性。
由于稀疏计算与低位Tensor Core(张量核心)加速正交,因此可以在SageAttention的基础上构建SLA,以在推理过程中获得额外的几倍加速。
TurboDiffusion引入了步数蒸馏(Step Distillation)技术,具体采用了随机一致性模型(Randomized Consistency Models, rCM)。这是一种当前最先进的蒸馏方法,它教会模型如何“跳着走楼梯”。
传统的扩散模型在每一步去噪时,只能预测出一小步的变化。而经过rCM蒸馏后的模型,具备了更强的预测能力,它可以在一步之内跨越原本需要十几步才能完成的去噪路径。
TurboDiffusion采用了W8A8量化策略。
W8A8指的是Weight(权重)和Activation(激活值)都使用8位整数(INT8)进行表示。这比常见的FP16格式节省了一半的显存空间,同时也减少了一半的显存访问量。
为了保证模型在如此低精度下依然聪明,TurboDiffusion采用了块级(Block-wise)量化策略,粒度细化到128x128。
训练与推理的极致效率
训练:
给定一个预训练的视频生成模型,TurboDiffusion采用如下训练流程。
首先将模型中的全注意力(Full Attention)替换为稀疏线性注意力SLA,并对模型进行少量步数的微调(finetuning)。与此同时,使用rCM将预训练模型蒸馏为一个采样步数更少的生成过程。
然后将SLA微调与rCM训练所产生的参数更新合并,得到一个统一的模型。
更多训练细节,团队表示将在下一版技术报告中提供。
推理:
上述训练得到的视频生成模型,在推理阶段采用了如下加速策略。
将SLA的原始API替换为SageSLA,这是一个基于SageAttention的SLA CUDA实现。
将扩散模型的采样步数进一步减少到一个很小的数值,例如 4 步或 3 步。
以128 × 128的块级粒度将线性层(Linear layer)的参数量化为INT8。
在推理过程中,也以相同的块级粒度将线性层的激活值量化为INT8,并使用INT8 Tensor Cores来执行线性层计算。 通过这种方式,模型大小被压缩约一半,同时显著加速了线性层计算。
团队还用Triton或CUDA重新实现了若干算子(例如LayerNorm和RMSNorm),以获得更高的运行效率。
实验数据验证
研究团队在Wan2.2-14B、Wan2.1-1.3B、Wan2.1-14B等多个版本的模型上进行了严苛的测试,涵盖了480P和720P等不同分辨率。
测试的基准是Wan模型的官方原版本以及目前市面上流行的加速框架FastVideo。

在Wan2.1-T2V-1.3B-480P模型上,生成5秒视频,原始版本需要166秒,而TurboDiffusion仅需1.8秒。这是一个近乎瞬间的体验,用户几乎感觉不到延迟。相比之下,FastVideo虽然也很快,但也需要4.7秒。
我们通过下表可以直观地对比不同模型的加速效果:

从生成的样片来看,无论是光影的流转、物体的纹理,还是动作的流畅度,TurboDiffusion生成的视频与原始模型几乎肉眼难以区分。
最重要的是,TurboDiffusion加速,并没有以牺牲画质为代价。
参考资料:
https://github.com/thu-ml/TurboDiffusion
https://jt-zhang.github.io/files/TurboDiffusion_Technical_Report.pdf

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









