



加州大学默塞德分校(UC Merced)、字节跳动Seed团队、武汉大学、北京大学的一群研究人员,把LLaVA和SAM-2两个的AI大脑缝合在了一起。
前不久Meta的一篇论文:万字硬核解读SAM 3:不止分割一切,它开始理解世界了,投到顶会ICLR 2026,现在还在匿名评审。
没想到这就被字节用LLaVA + SAM-2直接落地实现了。
现在,它既能理解电影里的画面、氛围和对话,也能在你发出指令后,精准地在视频里圈出任何一个你想要追踪的角色或物体。
两个大脑被缝合到了一起
LLaVA是先进的开源视觉语言模型框架,你给它一段视频,它能精准理解视频内容。它就像个影评人,擅长宏观叙事和抽象理解。它的强项在于“聊”,但你要是让它在屏幕上指出“穿黄裙子的那个女孩”,它就只会动嘴,不会动手。它知道她在哪,但它指不出来。
SAM(Segment Anything Model,分割一切模型)则是天生的视觉解剖专家,它能把图像、视频里的东西,精确地给你勾勒出来。它能“看见”,也能“分割”和“跟踪”,但它听不懂人话。你对它说“把戴墨镜的那个男人找出来”,它一脸茫然,因为它不理解“戴墨镜的男人”这个复杂的语言概念。它只能识别像素,不懂语义。
一个会聊不会指,一个会指不会聊。为了将两者结合,Sa2VA诞生了。
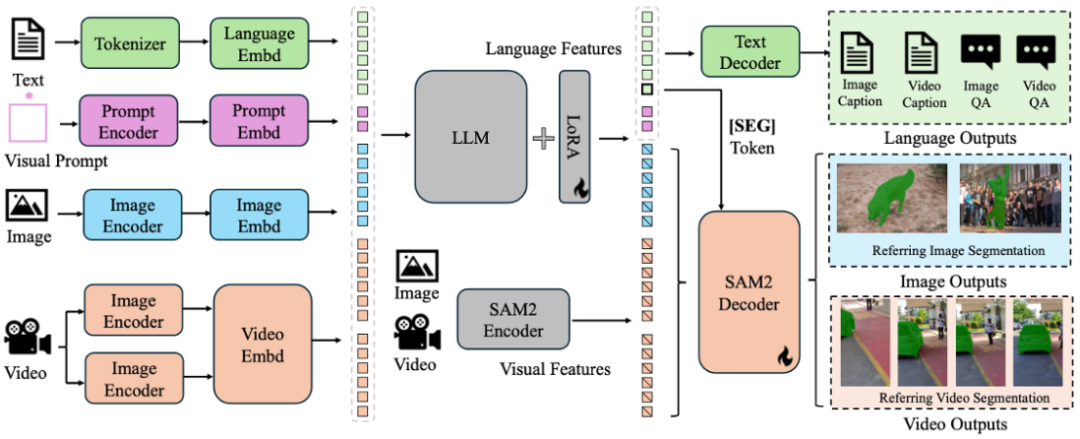
Sa2VA的思路简单又异常巧妙。它没有选择从零开始造一个全新的模型,而是直接把两个宇宙最顶尖的大脑拿了过来:一个是负责视频分割与跟踪的SAM-2,另一个是负责语言理解与对话的LLaVA。
这个新模型的架构,可以想象成一个拥有双核处理器的大脑。
其中一个核心是LLaVA模块。它负责处理所有输入进来的信息,不管是你打的字,还是上传的图片和视频。它内部有一个视觉编码器,像眼睛一样,先把图像和视频转化成计算机能理解的视觉特征。然后,一个投影层把这些视觉特征“翻译”成语言模型能读懂的token。最后用基于强大的如Qwen2.5或InternLM2.5大语言模型,开始思考和生成回应。
另一个核心是SAM-2模块。它静静地待命,随时准备接收来自语言核心的指令。
两者之间的沟通,靠的是一个特殊的“暗号”,一个叫做“[SEG]”的指令token。
当语言核心理解了你的指令,比如“请分割那个穿黄色连衣裙的女孩”,它不会自己动手去画框,而是生成一段包含这个特殊暗号“[SEG]”的指令,然后把它传递给SAM-2模块。SAM-2看到这个暗号,立刻启动它的编码器和解码器,调动它的时序跟踪记忆模块,在视频里找到那个女孩,并输出一层像素级精准的分割掩码(mask)。
这个设计最妙的地方在于“解耦”。两个模块各司其职,通过一个简单的暗号连接。语言大脑不用操心像素级的苦力活,视觉大脑也不用费神去理解人类语言的弯弯绕绕。同时,这个连接机制还支持梯度的反向传播,也就是说,当视觉大脑的工作结果不够理想时,这个“反馈”可以传回给语言大脑,帮助它学习如何下达更精准的指令。这就形成了一个闭环,让整个系统在训练中不断进化。
为了让这个新大脑能熟练掌握各项技能,研究团队为它设计了一套“多任务联合训练”的课程。它们同时在指代表达分割(Referring Expression Segmentation, RES)、视频指代表达分割(Referring Video Object Segmentation, Ref-VOS)、视觉问答(VQA)以及有定位的对话生成(Grounded Conversation Generation, GCG)等多个项目上进行训练。
训练后的Sa2VA强的离谱!
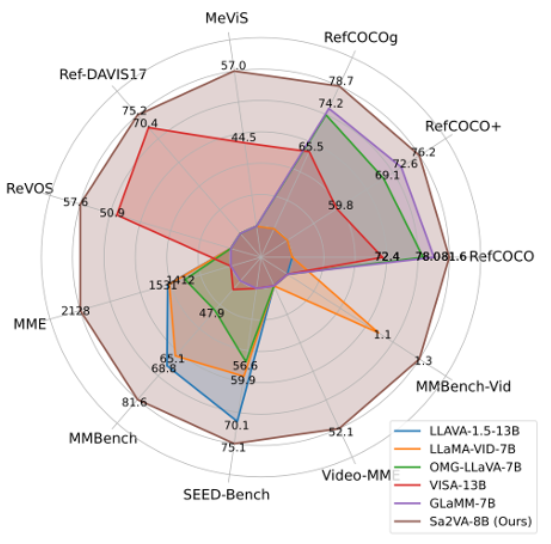
性能数据分析
Sa2VA在一系列公开的图像与视频基准测试中,交出了一份相当亮眼的成绩单,尤其是在视频指代表达分割(Ref-VOS)这个核心任务上。
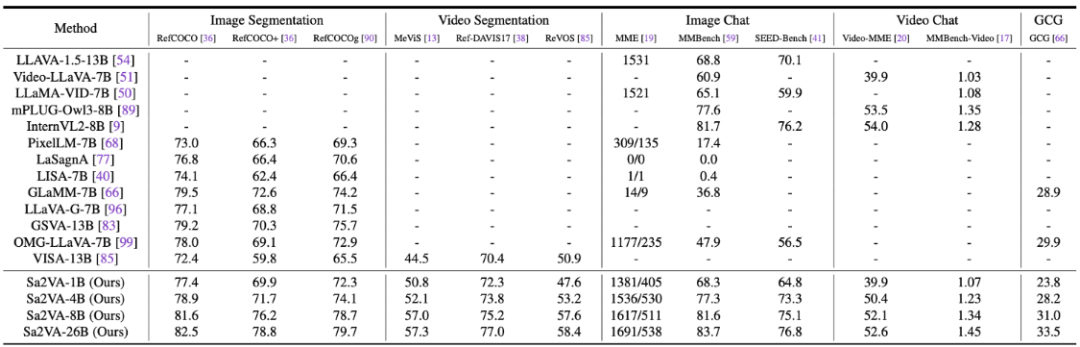
MME和MMBench可以看作是AI的“看图说话”综合能力测试,分数越高,说明它对图像内容的理解和问答能力越强。
RefCOCO系列是图像领域的“你画我猜”高级版。测试者给出一句描述,比如“图片左边那个正在跳舞的女孩”,AI需要准确地把这个女孩圈出来。指标是交并比(IoU),可以理解为AI圈出的范围和标准答案范围的重合度,越高越好。
MeVIS和DAVIS则是视频领域的“动态你画我猜”,难度更高。因为目标物体在视频里会移动、被遮挡,AI不仅要找得准,还得跟得住,保持时序上的一致性。
从表格里可以看到,Sa2VA随着参数量的增加,各项能力稳步提升。
它的对话能力也没有因为增强了视觉定位而瘸腿。在MME、MMBench等测试中,Sa2VA-8B同样取得了高分,证明了它是一个没有明显短板的“六边形战士”。
为了让它在复杂的真实世界视频中也能表现出色,团队还专门发布了一个名为Ref-SAV的数据集。这个数据集包含了超过七万个复杂视频场景中的物体表达,其中两千个视频物体经过了人工的精细验证,专门用来评测模型在恶劣环境下的性能。
开源
字节跳动和合作院校,把它完全开放出来。
Sa2VA整个系列的模型,从10亿参数的轻量版到260亿参数的重量级版本,全部开源。它们基于InternVL或QwenVL等优秀的底层模型构建,提供了丰富的选择,满足从学术研究到商业应用的不同需求。
以下是官方开源的模型列表:
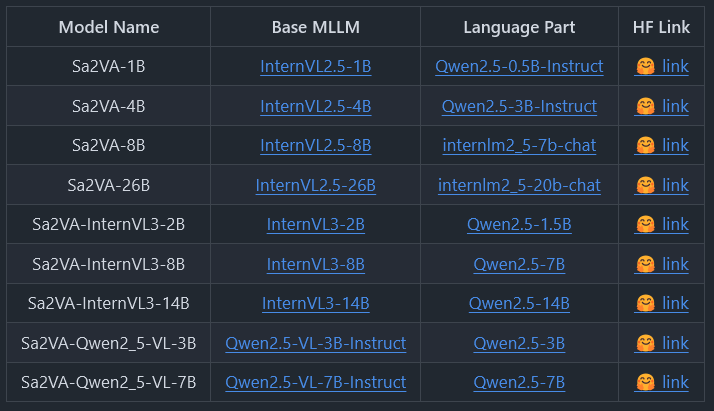
开源的内容不止模型本身,还包括了训练和评估的全套工具链。从训练数据集(Ref-SAV)、评估代码、训练与推理脚本,到可以直接运行的Demo代码,应有尽有。任何一个有条件的开发者,都可以复现、验证甚至改进Sa2VA。
官方发布的Demo展示了Sa2VA在真实场景中的应用能力。
比如,在一段电影《爱乐之城》(La La Land)的片段中,你输入指令,“请分割穿黄色连衣裙的女孩”。Sa2VA会立刻在视频上生成一个紧贴女主角身体轮廓的动态掩码,无论她如何移动、跳舞,掩码都能精准跟随。
又比如,在一段经典电影《教父》(The Godfather)的片段中,你问它,“这个场景的氛围是怎样的?”。它会回答,“这个场景有一种黑暗而神秘的氛围,男人们穿着西装打着领带,房间光线昏暗。”。它不仅看到了画面内容,还理解了导演想要传达的“氛围”。
这就是Sa2VA的核心价值:它不再是一个只能执行单一任务的工具,而是一个能够与你在视觉层面进行深度交互的助手。
Sa2VA通过一次巧妙的“缝合手术”,创造了一个统一的模型,解决了长期以来多模态AI领域的一个核心矛盾。它让AI不仅能“看懂”,还能“指给你看”。
这种图文、视频、语言和定位的统一理解能力,为视频剪辑、智能监控、人机交互等领域打开了新的想象空间。
参考资料:
https://arxiv.org/abs/2501.04001
https://github.com/bytedance/Sa2VA
https://lxtgh.github.io/project/sa2va/
https://huggingface.co/collections/ByteDance/sa2va-model-zoo-677e3084d71b5f108d00e093
END

















 2160
2160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









