



家人们,炸裂消息!那个我们熟悉的“小破站”哔哩哔哩(B站)的语音技术团队,把自家研发的新一代零样本语音合成模型IndexTTS2给开源了!

整个技术圈直接“嗡”地一下就炸了。为啥反应这么大?因为这玩意儿,可能真要让影视配音这个行业,彻底换个活法了。
IndexTTS2解决了一个困扰行业已久的终极难题:怎么让AI说话不但感情充沛,还能帮助精准对上口型。这波操作,直接把AI配音从“机器人腔”,推向了千人千面,应景而生的“真人腔”。
AI配音,终于能对上口型了
聊到语音合成,也就是TTS (文本转语音) 技术,大家可能不陌生,手机里的语音助手就是这玩意儿。这些年技术一路狂飙,从早期一个字一个字拼接的“机器人腔”,进化到了用神经网络生成的、听起来还挺顺耳的声音。但你让它去给电影电视剧配音试试?
影视配音那可是个精细活儿,声音和画面得严丝合缝,演员嘴巴和情绪,跟声音的抑扬顿挫得契合,差一丁点儿感觉就全错了。这就把之前的AI给难住了。当时的江湖主要有两大门派:一派是自回归(Autoregressive, AR)模型,这位选手音色优美,情感自然,但天生随性,说话说到哪儿算哪儿,你让它精准控制每句话说多长时间,它表示“臣妾做不到啊!”。另一派是非自回归(Non-Autoregressive, NAR)模型,这位选手是个守时标兵,你说让它说三秒,它绝不说三点零一秒,但代价是声音听起来有点干巴,感情不到位。
B站语音团队的这帮技术大神们,搞出了一套名叫“通用且兼容自回归架构的语音时长控制方法”的独门绝技。说白了,他们成功地在声音最好听的AR模型身上,加装了一个“时间控制器”,实现了毫秒级的精准控制。
这个“时间控制器”用起来也巧妙得不行。技术上说,他们在训练序列里塞进去一个特殊的嵌入向量,通过调整输出的语义token数量,就能像拧水龙头一样,精确控制语音的长短。用户想生成一段特定时长的语音,只需要告诉模型目标token数量,模型就能指哪打哪;如果不定时长,模型也能自动模仿你给的参考音频的节奏,保证说话的自然感。
官方给的数据是,在指定真实语音时长的情况下,token数量的误差率低于0.02%。就算是在0.75倍慢放或者1.25倍快进这种极端场景下,误差率也稳稳地保持在0.07%以内。近乎完美!这种能力,对于电影、动画、广告这些对音画同步要求堪称变态的领域来说,简直就是天降福音。
不光会说话,它还懂“人话”
如果说时长控制解决了“啥时候说”和“说多久”的问题,那接下来这个功能,就解决了“怎么表达”这个更要命的难题。IndexTTS2最让人拍案叫绝的另一个骚操作,是实现了情感和说话人身份的“解耦”。啥意思?就是它可以把一个人的“音色”和他的“情绪”分开处理。你可以指定用A的音色,去表达B的情绪。甚至,你可以把好几个不同说话人的情感特征,嫁接到同一个目标音色上。
在实际应用里,这意味着你只需要给AI听一段3到10秒的参考音频,它就能把这段音频里的情感,比如愤怒、悲伤、喜悦给“克隆”下来,然后你可以把这种“情感包”随心所欲地应用到任何其他音色上。更绝的是,IndexTTS2还支持用大白话来控制情绪。你不用去调那些复杂的参数,直接在输入框里打字告诉它,比如“巨巨巨难过”、“带点委-屈”,模型就能秒懂你的意思,然后生成相应情感的语音。这AI,算是真正开始“懂人话”了。
这种神奇的情感控制能力,源于IndexTTS2独特的两阶段训练策略。第一阶段,团队用一个基于Conformer架构的情感感知调节器,专门训练模型识别和理解情感。同时,他们用了一个叫“梯度反转层”的黑科技,把情感信息和说话人本身的口音、语速这些属性彻底分开,互不干扰。第二阶段,再把模型放到海量的中性语音数据里去微调,但这时候第一阶段训练好的情感调节器是锁定的。为了实现用自然语言控制情感,团队还定义了七种标准情感,并对Qwen3大语言模型进行了微调,硬是给咱们说的大白话和AI能理解的情感向量之间,搭了一座桥。
拆开这个“黑科技”,看看里面都有啥
IndexTTS2这么牛,它的内部构造肯定不简单。整个模型就像一个高度协同的精密工厂,由三大核心模块组成:Text-to-Semantic(T2S (文本到语义))、Semantic-to-Mel(S2M (语义到梅尔频谱))以及BigVGANv2声码器。这哥仨儿各司其职,流水线作业,最终把冷冰冰的文字变成有血有肉的声音。
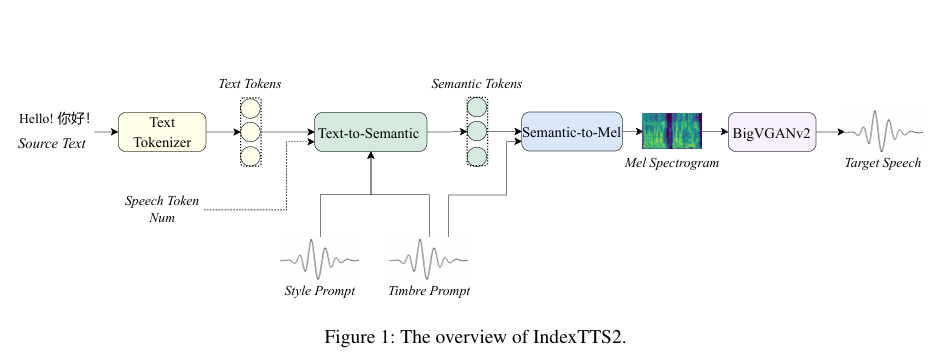
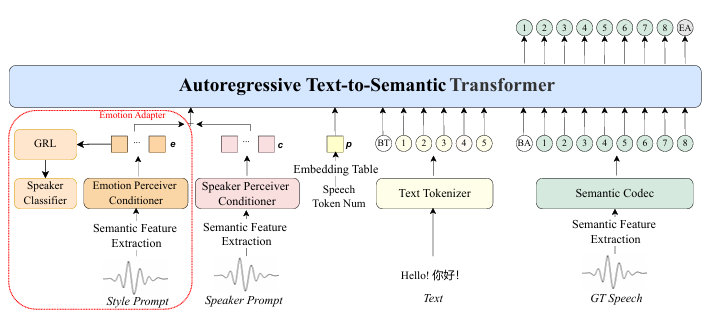
T2S模块,是整个系统的大脑和指挥中心。它负责把输入的文字转换成一种叫“语义token”的中间代码。但它又不是一个普通的自回归大语言模型,B站的工程师给它加了两个独门“插件”:时长控制和情感控制。
时长控制的秘密,在于它共享了语义位置嵌入表Wsem和时长嵌入表Wnum的参数,实现了对输出token数量的精细调节。团队在训练时还发现了一个小窍门:对输入的真实语音和说话人提示音频进行随机的速度调整,能大大提高时长控制的准度。同时,为了让模型既能“定时说”又能“随心说”,他们在训练时有30%的概率会把时长嵌入设成零向量,让模型学会两种模式。情感控制则依赖那个内置的情感感知调节器,它能从风格提示里“品”出情感,再通过梯度反转层把情感和说话人特征剥离开。
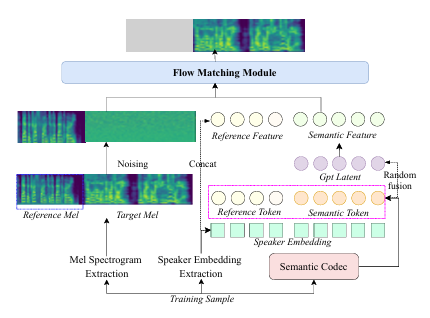
S2M模块,可以理解为一位才华横溢的作曲家。它采用了一种基于流匹配(Flow Matching)的非回归生成框架,任务是把T2S大脑输出的语义token“翻译”成梅尔频谱图(你可以把它想象成一种非常精细的声波乐谱)。这里用到了条件流匹配(CFM (条件流匹配))技术,学习一个常微分方程(ODE (常微分方程)),这个方程能引导样本从一堆随机噪声,一步步“进化”成目标梅尔频谱图。为了解决在表现深度情感时声音可能变糊的问题,S2M模块还加了两个“外挂”:一是利用从BERT模型里提取的文本表示作为辅助输入;二是把T2S模块的GPT潜在特征也拿来当补充信息。这个操作,让最终生成的声学特征发音更准、语义更流畅。
最后登场的是BigVGANv2声码器,它是一位顶级的录音师和混音师。它的工作是把S2M模块生成的梅尔频谱图,最终转换成我们耳朵能听到的高质量语音波形。BigVGANv2本身就是一个经过大规模训练的通用神经声码器,专门负责生成自然、清晰的声音,为整个系统的输出品质提供了最后一道坚实保障。
基准测试表现
说了这么多,IndexTTS2到底有多强?不吹不黑,直接上数据。B站团队在好几个公开的基准测试集上,把它和当前市面上最顶尖的几个零样本TTS系统拉到一块儿。结果?IndexTTS2几乎是全方位碾压。
表1:不同系统在不同数据集上的零样本性能比较
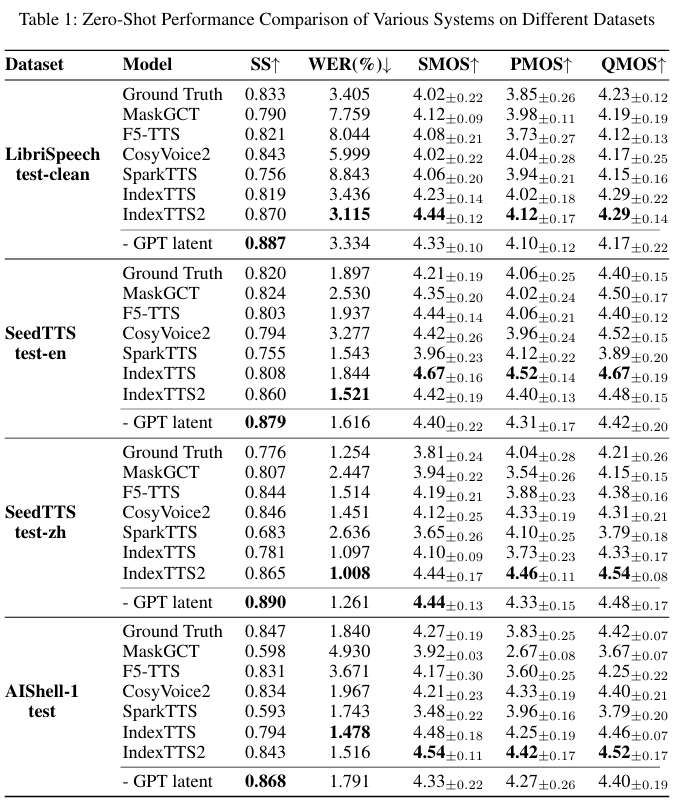
表2:情绪测试数据集上各种系统的性能比较
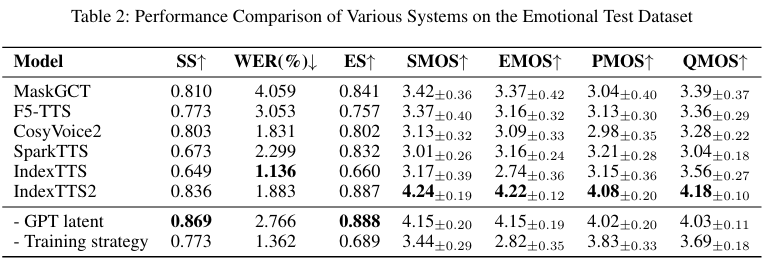
表3:基于自然语言的情绪控制与CosyVoice2的比较
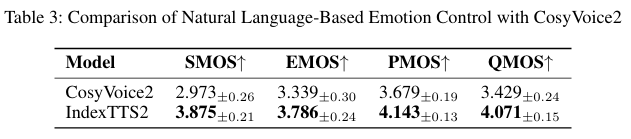
表4:不同设置下持续时间控制的token数错误率(%)
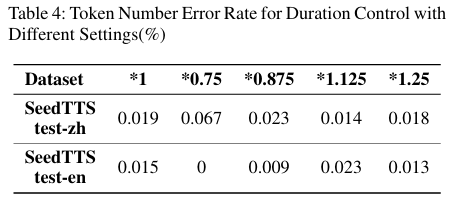
表5:持续时间控制下不同模型的MOS得分
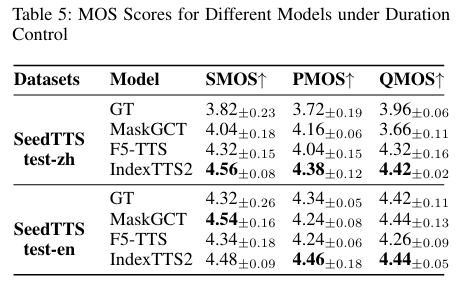
为了证明模型里的每个零件都有用,团队还做了消融实验。简单说,就是故意拿掉模型的一些部件,看看会发生什么。结果发现,如果拿掉GPT潜在特征,模型的各项指标立马下降,尤其是在声音清晰度上;如果把S2M模块换成MaskGCT的S2A模块,说话人相似度和词错误率会变得很糟。这充分证明了IndexTTS2的每一部分设计都是经过深思熟虑且不可或缺的。
当然,数据再好看,不如耳朵听着震撼。
原声音:
2
克隆生成声音:
情绪提示词 “巨巨巨巨巨巨巨巨难过”
这对于影视剧出海、打破语言壁垒来说,意义太重大了。过去一部剧要出口,得花大价钱请国外的配音团队,效果还不一定好。现在有了IndexTTS2,只需要5秒参考音频,就能高精度复刻任何人声(相似度超过85%),成本和效率,那都不是一个数量级的了。
开源,让魔法属于每个人
为了炼成这个“大杀器”,B站团队也是下了血本。他们用了总计55000小时的中英双语语音数据,外加135小时的情感数据来喂养这个模型。这些数据来源广泛,保证了模型的多样性。
结果B站选择将如此尖端的技术完全开源:“为进一步推动语音合成技术的开放创新与行业应用落地,我们已将IndexTTS2的相关研究成果整理为论文,并开源了推理代码与模型权重,诚邀各位开发者、研究者、内容创作者共同探索语音合成的无限可能。”
太良心了!
这种“技术民主化”的举动,意味着顶尖的语音合成技术不再是科技巨头的专利。小到个人开发者,大到影视制作公司、游戏开发商,都可以基于IndexTTS2去构建自己的配-音解决方案,去创造更多前所未有的应用。
可以预见,围绕IndexTTS2,一个繁荣的开源生态正在形成。未来,会有更多基于它的优化工具、行业解决方案和创意应用涌现出来。
GitHub项目仓库:https://github.com/index-tts/index-tts
Hugging Face:https://huggingface.co/IndexTeam
Modelscope:https://modelscope.cn/models/IndexTeam/IndexTTS-2
免费试玩:https://huggingface.co/spaces/IndexTeam/IndexTTS-2-Demo
参考资料:
https://arxiv.org/abs/2506.21619
https://index-tts.github.io/index-tts2.github.io
END


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









