### Vision Transformer (ViT) 的代码实现与复现教程
Vision Transformer (ViT)[^4] 是一种基于Transformer架构的模型,用于处理计算机视觉任务。它通过将输入图像分割成固定大小的小块(patches),并将这些小块线性嵌入到高维向量中来工作。随后,这些向量被送入标准的Transformer编码器层进行特征提取。
以下是 ViT 的基本实现框架:
#### 数据预处理
在 ViT 中,图像首先会被划分为多个不重叠的小块(patches)。每个 patch 被展平并映射到一个 d 维度的空间中。为了保持位置信息,在嵌入之前会加入可学习的位置编码。
```python
import torch
from einops import rearrange, repeat
from torch.nn import Linear, LayerNorm, Dropout, Sequential, ModuleList, MultiheadAttention, ReLU
class PatchEmbedding(torch.nn.Module):
def __init__(self, image_size=224, patch_size=16, embed_dim=768):
super().__init__()
self.patch_embed = torch.nn.Conv2d(3, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.patch_embed(x) # B, C, H, W -> B, D, H', W'
x = rearrange(x, 'b c h w -> b (h w) c') # Flatten patches into sequence
return x
```
#### 多头自注意力机制
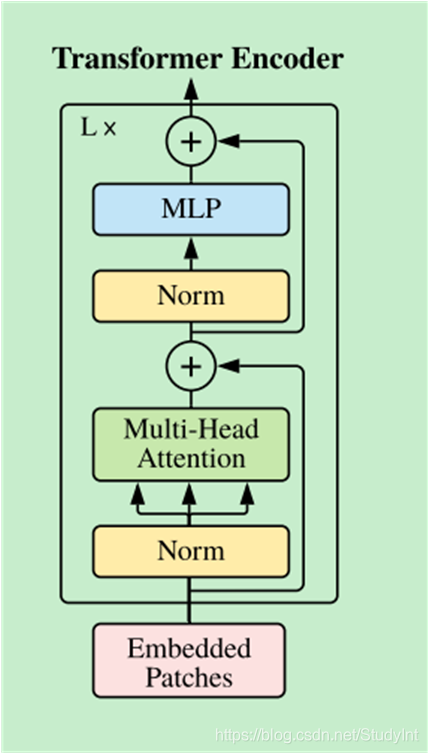
多头自注意力模块允许网络关注不同部分的信息,并从中捕获全局依赖关系。这是 Transformer 架构的核心组件之一。
```python
class AttentionBlock(torch.nn.Module):
def __init__(self, dim, num_heads=12, dropout_rate=0.1):
super().__init__()
self.attn = MultiheadAttention(dim, num_heads=num_heads)
self.ln_1 = LayerNorm(dim)
self.mlp = Sequential(
Linear(dim, dim * 4),
ReLU(),
Linear(dim * 4, dim),
Dropout(dropout_rate)
)
self.ln_2 = LayerNorm(dim)
def forward(self, x):
attn_output, _ = self.attn(x, x, x)
x = x + attn_output
x = self.ln_1(x)
mlp_output = self.mlp(x)
x = x + mlp_output
return self.ln_2(x)
```
#### 完整的 ViT 实现
完整的 ViT 结构由上述两个主要部分组成——Patch Embedding 和一系列堆叠的 Transformer 编码器层。
```python
class VisionTransformer(torch.nn.Module):
def __init__(self, image_size=224, patch_size=16, embed_dim=768, depth=12, num_heads=12, classes=1000):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size=image_size, patch_size=patch_size, embed_dim=embed_dim)
num_patches = (image_size // patch_size)**2
self.cls_token = torch.nn.Parameter(torch.zeros(1, 1, embed_dim))
self.positional_encoding = torch.nn.Parameter(torch.randn(num_patches + 1, embed_dim))
self.transformer_blocks = ModuleList([
AttentionBlock(embed_dim, num_heads=num_heads) for _ in range(depth)])
self.norm = LayerNorm(embed_dim)
self.head = Linear(embed_dim, classes)
def forward(self, x):
batch_size = x.shape[0]
x = self.patch_embedding(x)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=batch_size)
x = torch.cat((cls_tokens, x), dim=1)
x += self.positional_encoding
for block in self.transformer_blocks:
x = block(x)
x = self.norm(x[:, 0]) # Take the class token output only
out = self.head(x)
return out
```
以上是一个简单的 ViT 模型实现示例。实际应用中可能还需要考虑更多的优化细节以及数据增强策略等。
---
### 关于 VAE 和 CLIP 的补充说明
虽然本问题聚焦于 ViT 的实现,但可以注意到 VAE[^3] 主要涉及图像生成过程中的编码和解码操作,而 CLIP[^2] 则专注于跨模态表示的学习。这三者分别代表了当前深度学习领域内的三个重要方向:纯视觉建模、生成对抗网络/变分自动编码器以及多模态联合训练技术。
---





 Python中Transformer块数量设置
Python中Transformer块数量设置
 博客围绕Python中Transformer块数量展开,提到Transformer块数量用depth表示,如depth = 8意味着设置了8层transformer encoder,涉及到Transformer相关信息技术内容。
博客围绕Python中Transformer块数量展开,提到Transformer块数量用depth表示,如depth = 8意味着设置了8层transformer encoder,涉及到Transformer相关信息技术内容。

 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























