




 本文详细介绍了PyTorch中LSTM和ConvLSTM的实现原理与应用,包括LSTM单元的参数解析、输入输出形状、内部变量说明以及ConvLSTM的代码实现。通过实例演示了如何在PyTorch中使用LSTM和ConvLSTM进行序列预测。
本文详细介绍了PyTorch中LSTM和ConvLSTM的实现原理与应用,包括LSTM单元的参数解析、输入输出形状、内部变量说明以及ConvLSTM的代码实现。通过实例演示了如何在PyTorch中使用LSTM和ConvLSTM进行序列预测。
pytorch 实现convLSTM的更新版见:pytorch convLSTM实现,更新版更为通用,使用更为方便
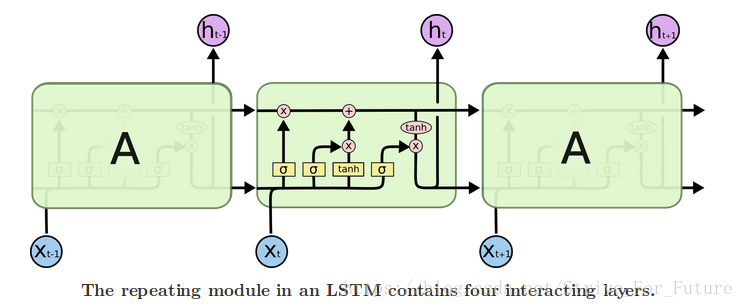
LSTM 原理图(图来源)
LSTM原理解析(更多细节参考: LSTM详细介绍):
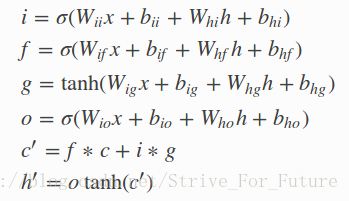
class torch.nn.LSTMCell(input_size, hidden_size, num_of_layers,bias=True)
在torch 中,定义一个LSTM单元,只需要给出两个参数: input_size和 hidden_size
参数解析: input_size:输入的特征的维度
hidden_size:隐层状态的维度(hidden_state,cell_state具有相同的维度)
num_of_layers: LSTM的层数
bias:默认为True,在输入过程和隐层生成的过程中,有偏置项,否则则没有
应用:
输入:input,(h_0,c_0)
input: shape=[batch_size,input_size],是一个包含输入特征的张量
h_0: shape=[batch_size,hidden_size],是一个张量,包含最初始的隐藏状态,对batch中的每个元素都有意个对应的隐藏状态
c_0: shape=[batch_size,hidden_size],是一个张量,包含最初始的cell状态,对batch中的每个元素都有意个对应的cell状态
备注:如果(h_0,c_0)在应用中没有给出,则默认其初始值为0
输出: h_1,c_1
h_1:shape=[batch_size,hidden_size],是一个张量,包含最初始的隐藏状态,对batch中的每个元素都有意个对应的隐藏状态
c_1: shape=[batch_size,hidden_size],是一个张量,包含最初始的cell状态,对batch中的每个元素都有意个对应的cell状态
LSTM的内部隐含的变量:
weight_ih: 从input-->hidden 的权重,shape=[4*hidden_size x input_size]
bias_ih:从input-->hidden 的偏置,shape=[4*hidden_size ]
weight_hh:从hidden-->hidden 的权重,shape=[4*hidden_size x hidden_size]
bias_hh:从hidden-->hidden 的偏置,shape=[4*hidden_size ]
示例:
>>> rnn = nn.LSTMCell(10, 20)
>>> input = torch.randn(6, 3, 10)
>>> hx = torch.randn(3, 20)
>>> cx = torch.randn(3, 20)
>>> output = []
>>> for i in range(6):
hx, cx = rnn(input[i], (hx, cx))
output.append(hx)
示例解析:
input_size=10
hidden_size=20
batch_size=3
batch_num = 6
在应用LSTM对象rnn的时候输入了(hx, cx),给定了(h_0,c_0)的初始值,在实际情况中,不给出也行,主要看需求
疑问: c_1 与 h_1 的区别
回答:参考上面的公式的第五条和第六条,cell是用来传递信息的,并不真正输出,hidden_state是对cell_state处理激活后的结果,是输出的有用的信息. 即: LSTM会对 hidden_state 及 cell_state 都有输出,但 hidden_state 才是我们应用需要的.,最终要用的.
下图为个人笔记:
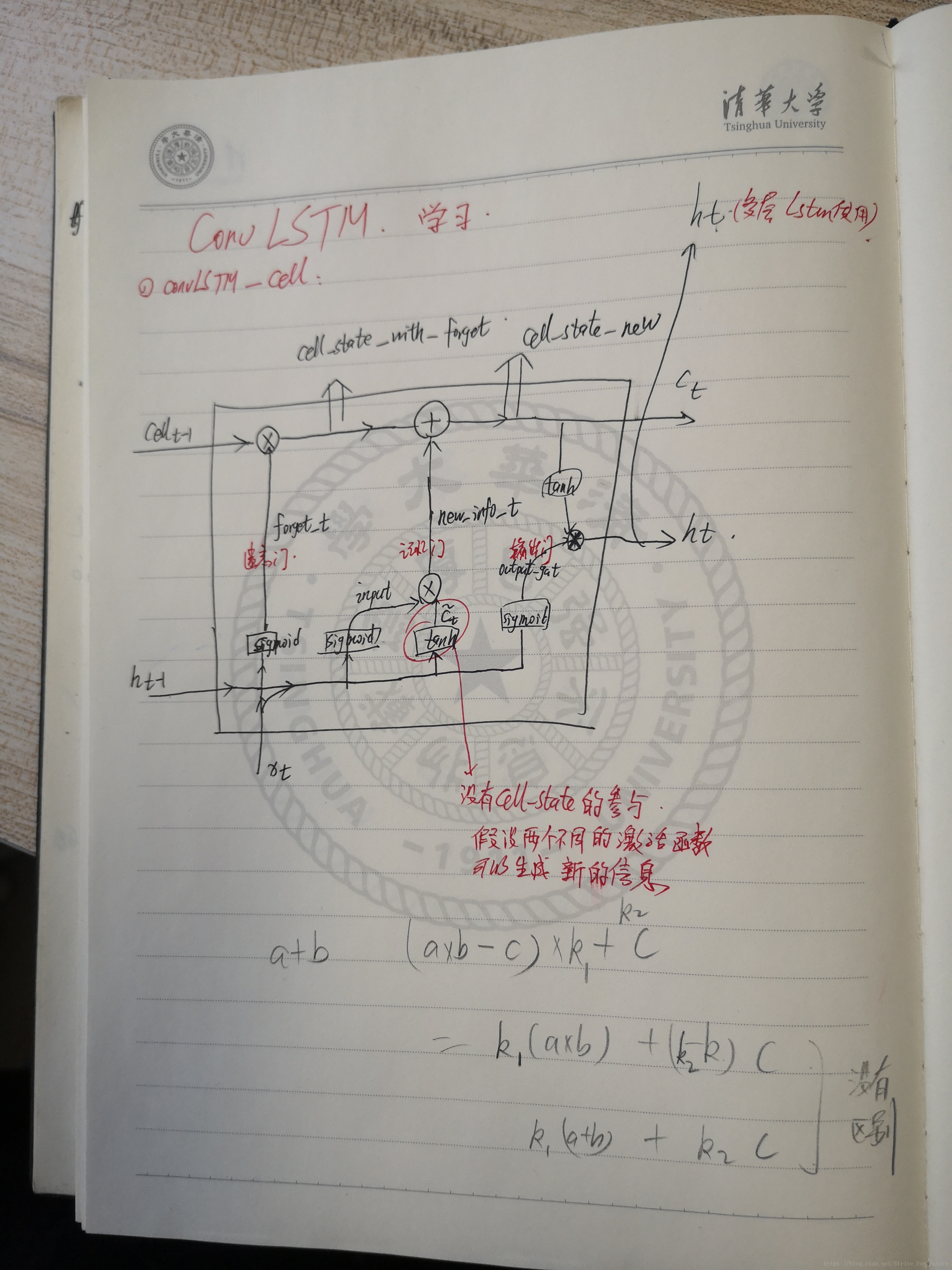
convLSTM代码:
#-*-coding:utf-8-*-
import torch
import torch.nn as nn
from torch.autograd import Variable
class ConvLSTMCell(nn.Module):
def __init__(self, input_channels, hidden_channels, kernel_size, bias=True):
super(ConvLSTMCell, self).__init__()
assert hidden_channels % 2 == 0
self.input_channels = input_channels
self.hidden_channels = hidden_channels
self.bias = bias
self.kernel_size = kernel_size
self.num_features = 4
self.padding = int((kernel_size - 1) / 2)
# 输入变换
self.Wxi = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whi = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
# 遗忘门
self.Wxf = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whf = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
# 记忆门
self.Wxc = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Whc = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
# 输出门
self.Wxo = nn.Conv2d(self.input_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=True)
self.Who = nn.Conv2d(self.hidden_channels, self.hidden_channels, self.kernel_size, 1, self.padding, bias=False)
self.Wci = None
self.Wcf = None
self.Wco = None
def forward(self, x, h, c):
## LSTMcell_input_1 = sigmoid(Wii*x + Whi * h)
## (包含三个部分,新的样本输入 x,上一个 LSTMcell 的输出 h,上一个 LSTMcell 的 cell_state c)
## 默认 cell_state c的权值为 0
ci = torch.sigmoid(self.Wxi(x) + self.Whi(h) + c * self.Wci)
##LSTMcell_forget = sigmoid(Wif*x + Whf * h)
cf = torch.sigmoid(self.Wxf(x) + self.Whf(h) + c * self.Wcf) ## LSTMcell_forget
## LSTMcell_new_cell_state = last_cell_state * LSTMcell_forget + LSTMcell_input_1 *torch.tanh(self.Wxc(x) + self.Whc(h))
#
cc = cf * c + ci * torch.tanh(self.Wxc(x) + self.Whc(h))
## LSTMcell_new_cell_state
co = torch.sigmoid(self.Wxo(x) + self.Who(h) + cc * self.Wco) # co : 输出门的输入(cell部分)
ch = co * torch.tanh(cc) # ch : 输出门的输出
return ch, cc
def init_hidden(self, batch_size, hidden, shape):
self.Wci = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()
self.Wcf = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()
self.Wco = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda()
return (Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda(),
Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda())
class ConvLSTM(nn.Module):
# input_channels corresponds to the first input feature map
# hidden state is a list of succeeding lstm layers.
def __init__(self, input_channels, hidden_channels, kernel_size, step=1, effective_step=[1], bias=True):
super(ConvLSTM, self).__init__()
self.input_channels = [input_channels] + hidden_channels
self.hidden_channels = hidden_channels
self.kernel_size = kernel_size
self.num_layers = len(hidden_channels)
self.step = step
self.bias = bias
self.effective_step = effective_step
self._all_layers = []
for i in range(self.num_layers):
name = 'cell{}'.format(i)
cell = ConvLSTMCell(self.input_channels[i], self.hidden_channels[i], self.kernel_size, self.bias)
setattr(self, name, cell)
self._all_layers.append(cell)
def forward(self, input):
internal_state = []
outputs = []
for step in range(self.step):
x = input
for i in range(self.num_layers):
# all cells are initialized in the first step
name = 'cell{}'.format(i)
if step == 0:
bsize, _, height, width = x.size()
(h, c) = getattr(self, name).init_hidden(batch_size=bsize, hidden=self.hidden_channels[i], shape=(height, width))
internal_state.append((h, c))
# do forward
(h, c) = internal_state[i]
x, new_c = getattr(self, name)(x, h, c)
internal_state[i] = (x, new_c)
# only record effective steps
if step in self.effective_step:
outputs.append(x)
return outputs, (x, new_c)
if __name__ == '__main__':
# gradient check
convlstm = ConvLSTM(input_channels=512, hidden_channels=[128, 64, 64, 32, 32], kernel_size=3, step=5, effective_step=[4]).cuda()
loss_fn = torch.nn.MSELoss()
input = Variable(torch.randn(1, 512, 64, 32)).cuda()
target = Variable(torch.randn(1, 32, 64, 32)).double().cuda()
output = convlstm(input)
output = output[0][0].double()
res = torch.autograd.gradcheck(loss_fn, (output, target), eps=1e-6, raise_exception=True)
print(res)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









