







YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程
YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总
《Reciprocal Attention Mixing Transformer for Lightweight Image Restoration》
一、 模块介绍
论文链接:https://arxiv.org/pdf/2305.11474
代码链接:https://github.com/rami0205/RAMiT/tree/main
论文速览:
尽管近期许多研究在图像修复(IR)领域取得了进展,但它们往往存在参数过多的问题。另一个问题是,大多数基于 Transformer 的图像修复方法仅关注局部或全局特征,导致感受野受限或参数不足。为了解决这些问题,我们提出了一种轻量级网络——互反注意力混合 Transformer(RAMiT)。它采用了我们提出的维度互反注意力混合 Transformer(D-RAMiT)块,该块并行计算不同多头数量的二维自注意力。二维注意力相互补充对方的不足之处,然后进行混合。此外,我们引入了分层互反注意力混合(H-RAMi)层,以补偿像素级信息损失,并利用语义信息,同时保持高效的分层结构。此外,我们重新审视并修改了 MobileNet V2,以将高效卷积附加到我们提出的组件上。
总结:本文介绍其中Downsizing模块的使用方法。
⭐⭐本文二创模块仅更新于付费群中,往期免费教程可看下方链接⭐⭐
二、二创融合模块
2.1 相关代码
# https://blog.youkuaiyun.com/StopAndGoyyy?spm=1011.2124.3001.5343
# Reciprocal Attention Mixing Transformer for Lightweight Image Restoration
class MobiVari1(nn.Module): # MobileNet v1 Variants
def __init__(self, dim, kernel_size, stride, act=nn.LeakyReLU, out_dim=None):
super(MobiVari1, self).__init__()
self.dim = dim
self.kernel_size = kernel_size
self.out_dim = out_dim or dim
self.dw_conv = nn.Conv2d(dim, dim, kernel_size, stride, kernel_size // 2, groups=dim)
self.pw_conv = nn.Conv2d(dim, self.out_dim, 1, 1, 0)
self.act = act()
def forward(self, x):
out = self.act(self.pw_conv(self.act(self.dw_conv(x)) + x))
return out + x if self.dim == self.out_dim else out
def flops(self, resolutions):
H, W = resolutions
flops = H * W * self.kernel_size * self.kernel_size * self.dim + H * W * 1 * 1 * self.dim * self.out_dim # self.dw_conv + self.pw_conv
return flops
class MobiVari2(MobiVari1): # MobileNet v2 Variants
def __init__(self, dim, kernel_size, stride, act=nn.LeakyReLU, out_dim=None, exp_factor=1.2, expand_groups=4):
super(MobiVari2, self).__init__(dim, kernel_size, stride, act, out_dim)
self.expand_groups = expand_groups
expand_dim = int(dim * exp_factor)
expand_dim = expand_dim + (expand_groups - expand_dim % expand_groups)
self.expand_dim = expand_dim
self.exp_conv = nn.Conv2d(dim, self.expand_dim, 1, 1, 0, groups=expand_groups)
self.dw_conv = nn.Conv2d(expand_dim, expand_dim, kernel_size, stride, kernel_size // 2, groups=expand_dim)
self.pw_conv = nn.Conv2d(expand_dim, self.out_dim, 1, 1, 0)
def forward(self, x):
x1 = self.act(self.exp_conv(x))
out = self.pw_conv(self.act(self.dw_conv(x1) + x1))
return out + x if self.dim == self.out_dim else out
def flops(self, resolutions):
H, W = resolutions
flops = H * W * 1 * 1 * (self.dim // self.expand_groups) * self.expand_dim # self.exp_conv
flops += H * W * self.kernel_size * self.kernel_size * self.expand_dim # self.dw_conv
flops += H * W * 1 * 1 * self.expand_dim * self.out_dim # self.pw_conv
return flops
class ReshapeLayerNorm(nn.Module):
def __init__(self, dim, norm_layer=nn.LayerNorm):
super(ReshapeLayerNorm, self).__init__()
self.dim = dim
self.norm = norm_layer(dim)
def forward(self, x):
B, C, H, W = x.size()
x = rearrange(x, 'b c h w -> b (h w) c')
x = self.norm(x)
x = rearrange(x, 'b (h w) c -> b c h w', h=H)
return x
def flops(self, resolutions):
H, W = resolutions
flops = 0
flops += H * W * self.dim
return flops
class Downsizing(nn.Module):
""" Patch Merging Layer.
Args:
dim (int): Number of input dimension (channels).
downsample_dim (int, optional): Number of output dimension (channels) (dim if not set). Default: None
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, downsample_dim=None, norm_layer=ReshapeLayerNorm, mv_ver=1, mv_act=nn.LeakyReLU,
exp_factor=1.2, expand_groups=4):
super(Downsizing, self).__init__()
self.dim = dim
self.downsample_dim = downsample_dim or dim
self.norm = norm_layer(4 * dim)
if mv_ver == 1:
self.reduction = MobiVari1(4 * dim, 3, 1, act=mv_act, out_dim=self.downsample_dim)
elif mv_ver == 2:
self.reduction = MobiVari2(4 * dim, 3, 1, act=mv_act, out_dim=self.downsample_dim, exp_factor=exp_factor,
expand_groups=expand_groups)
def forward(self, x):
# B, C, H, W = x.size()
# Concat 2x2
x0 = x[:, :, 0::2, 0::2] # [B, C, H/2, W/2], top-left
x1 = x[:, :, 0::2, 1::2] # [B, C, H/2, W/2], top-right
x2 = x[:, :, 1::2, 0::2] # [B, C, H/2, W/2], bottom-left
x3 = x[:, :, 1::2, 1::2] # [B, C, H/2, W/2], bottom-right
x = torch.cat([x0, x1, x2, x3], dim=1) # [B, 4C, H/2, W/2]
return self.reduction(self.norm(x)) # [B, C, H/2, W/2]
def flops(self, resolutions):
H, W = resolutions
flops = self.norm.flops((H // 2, W // 2)) + self.reduction.flops((H // 2, W // 2))
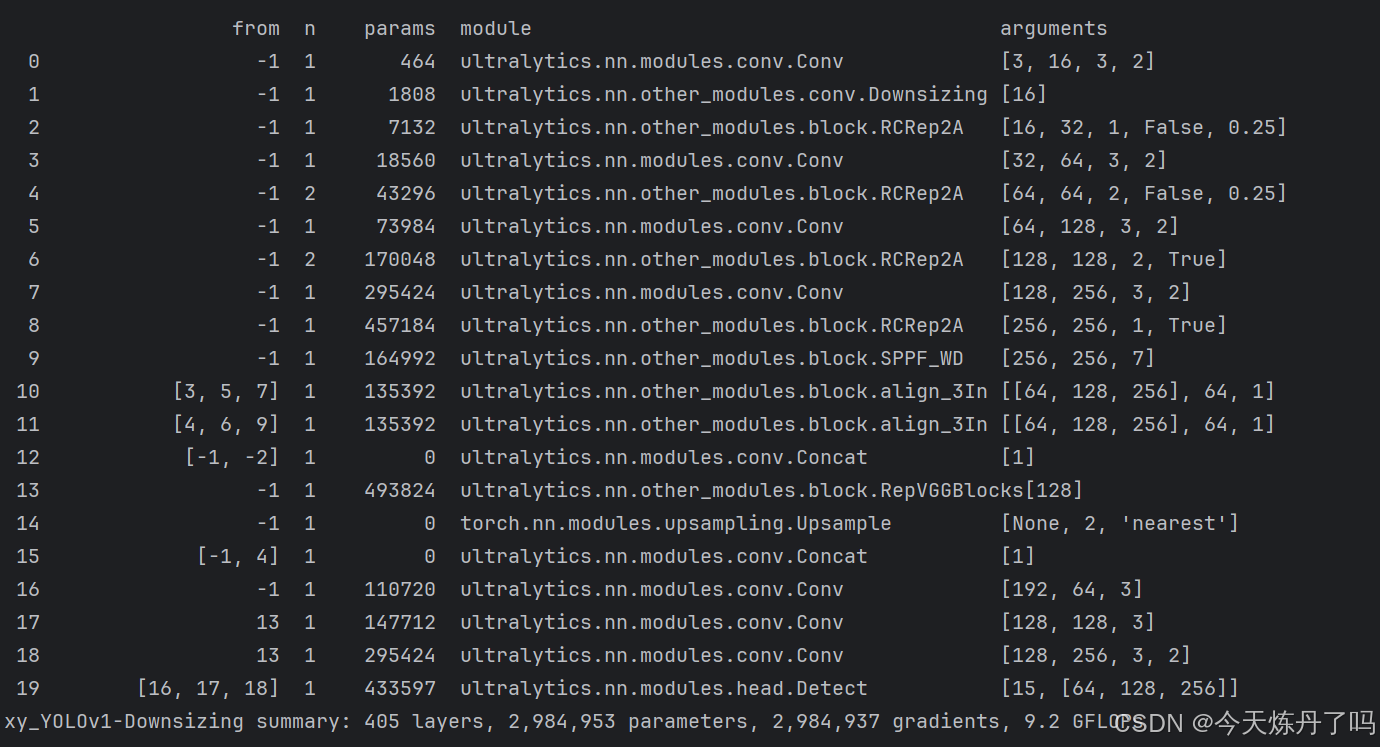
return flops2.2更改yaml文件 (以自研模型为例)
打开更改ultralytics/cfg/models/11路径下的YOLOv11.yaml文件,替换原有模块。

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# ⭐⭐Powered by https://blog.youkuaiyun.com/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 377 layers, 2,249,525 parameters, 2,249,509 gradients, 8.7 GFLOPs/258 layers, 2,219,405 parameters, 0 gradients, 8.5 GFLOPs
s: [0.50, 0.50, 1024] # summary: 377 layers, 8,082,389 parameters, 8,082,373 gradients, 29.8 GFLOPs/258 layers, 7,972,885 parameters, 0 gradients, 29.2 GFLOPs
m: [0.50, 1.00, 512] # summary: 377 layers, 20,370,221 parameters, 20,370,205 gradients, 103.0 GFLOPs/258 layers, 20,153,773 parameters, 0 gradients, 101.2 GFLOPs
l: [1.00, 1.00, 512] # summary: 521 layers, 23,648,717 parameters, 23,648,701 gradients, 124.5 GFLOPs/330 layers, 23,226,989 parameters, 0 gradients, 121.2 GFLOPs
x: [1.00, 1.50, 512] # summary: 521 layers, 53,125,237 parameters, 53,125,221 gradients, 278.9 GFLOPs/330 layers, 52,191,589 parameters, 0 gradients, 272.1 GFLOPs
# n: [0.33, 0.25, 1024]
# s: [0.50, 0.50, 1024]
# m: [0.67, 0.75, 768]
# l: [1.00, 1.00, 512]
# x: [1.00, 1.25, 512]
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Downsizing, []] # 1-P2/4
- [-1, 2, RCRep2A, [128, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 4, RCRep2A, [256, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, RCRep2A, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, RCRep2A, [1024, True]]
- [-1, 1, SPPF_WD, [1024, 7]] # 9
# YOLO11n head
head:
- [[3, 5, 7], 1, align_3In, [256, 1]] # 10
- [[4, 6, 9], 1, align_3In, [256, 1]] # 11
- [[-1, -2], 1, Concat, [1]] #12 cat
- [-1, 1, RepVGGBlocks, []] #13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #14
- [[-1, 4], 1, Concat, [1]] #15 cat
- [-1, 1, Conv, [256, 3]] # 16
- [13, 1, Conv, [512, 3]] #17
- [13, 1, Conv, [1024, 3, 2]] #18
- [[16, 17, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)
# ⭐⭐Powered by https://blog.youkuaiyun.com/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
2.3 修改train.py文件
创建Train脚本用于训练。
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
if __name__ == '__main__':
model = YOLO(model='ultralytics/cfg/models/xy_YOLO/xy_yolov1.yaml')
# model = YOLO(model='ultralytics/cfg/models/11/yolo11l.yaml')
model.train(data='./datasets/data.yaml', epochs=1, batch=1, device='0', imgsz=320, workers=1, cache=False,
amp=True, mosaic=False, project='run/train', name='exp',)

在train.py脚本中填入修改好的yaml路径,运行即可训练,数据集创建教程见下方链接。

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









