




文章目录
一、 Native Sparse Attention(NSA)实现原理与分析

核心思想:
NSA 是一种硬件对齐、可原生训练的稀疏注意力机制,通过动态分层稀疏策略(粗粒度压缩 + 细粒度选择 + 滑动窗口)平衡全局上下文和局部精度,同时优化硬件效率。
关键技术点:
-
分层稀疏策略:
-
压缩分支(CMP):将序列分块聚合为粗粒度表示,降低计算量。
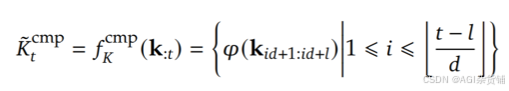
-
选择分支(SLC):基于块级重要性评分动态保留关键细粒度token。
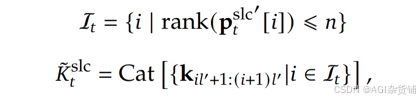
-
滑动窗口(WIN):保留局部上下文,防止其他分支被局部模式主导。
-
-
硬件优化:
- 针对现代 GPU 的 Tensor Core 设计块状内存访问,优化算术强度平衡。
- 使用 Triton 实现高效内核,支持 GQA/MQA 架构的 KV 共享。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3113
3113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









