




本项目获得了上海图书馆第七届开放数据竞赛算法类优胜奖。
比赛官网:上海图书馆开放数据竞赛 (library.sh.cn)
优胜队伍:第七届上海图书馆开放数据竞赛算法类获奖名单公布 · 新闻公告 · 开放数据竞赛 - 上海图书馆 (library.sh.cn)(队伍名:未名博雅)
算法目标:
根据图书信息和读者借阅信息,给读者推荐合适的书籍。具体数据有读者何时借阅了哪本书籍,以及每本书籍有一些介绍性字符串。输出是向每位读者推荐三十本书。
结果示例:
读者id 推荐书例1 推荐书例2 推荐书例3 推荐书例4 推荐书例5
781 《外汇交易圣经》 《技术分析与股市盈利预测》 《交易心理训练》 《股票魔法师》 《期货程序化交易实战入门与技巧》
51534 《首席医官》 《武动乾坤》 《斗罗大陆》 《魔兽战神》 《星辰变》
测试结果:
流行度 协同过滤 流行度+协同过滤 流行度+协同过滤+内容相似性分析
推荐成功率 0.4 0.8 0.81 0.88
本算法综合考虑书籍的流行度、用户间关系、内容相似度三项指标,对用户进行图书推荐。
书籍流行度指标:
在record字典中存储了每本书被借阅的次数。在推荐时,越流行的图书得分越高。在评分时有时间贬值率,暂定为0.9/月,也就是近期流行的书评分较高。
相似用户推荐指标(协同过滤):
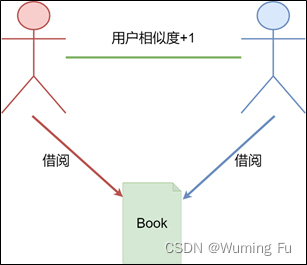
本算法使用协同过滤的方法考察用户间关系。当两位用户借阅了同一本书,这两位用户之间的“相似程度”将会加一。
推荐池的构成:
原始的推荐池构成:根据流行度指标提名45本书,根据协同过滤算法中的相似用户的喜好再提名45本书。
内容相似性指标:
在为一名用户作推荐时,会考虑这名用户阅读的内容和被推荐书籍内容的相似度。具体过程为:
1.提取该用户阅读过的书籍所有字段的文字信息
2.构建统计文字信息的所有两字组合的计数数据结构A,比如“你好啊”包含的两字组合为“你好”和“好啊”
3.提取被推荐书籍所有字段的文字信息
4.构建统计被推荐书籍文字信息的所有两字组合的计数数据结构B
5.将两个计数数据结构进行比对,量化相似性,具体为:
a.如果某个两字组合在A中出现次数大于等于5且在B中出现次数大于等于3,则加3分
b.如果某个两字组合在A中出现次数大于等于3且在B中出现次数大于等于2,则加2分
c.如果某个两字组合在A中出现次数大于等于2且在B中出现次数大于等于2,则加1.5分
d.如果某个两字组合在A中出现次数大于等于1且在B中出现次数大于等于1,则加1分
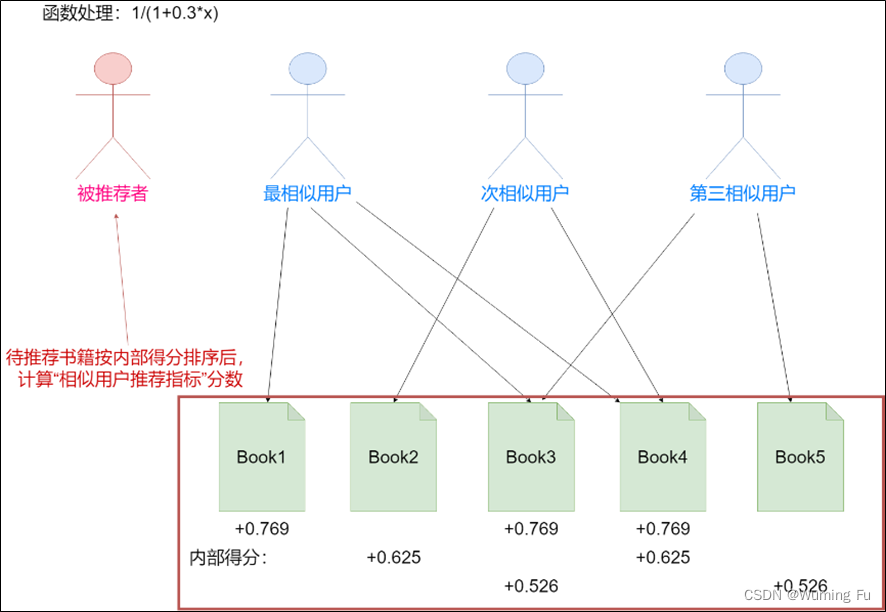
函数处理与具体操作:
三个指标均使用以序数为自变量的函数进行量化,使用函数1/(1+0.3*x) 。
在统计完书籍流行度(考虑折现因子)后,对书籍按流行度排序,第一名在“书籍流行度指标”上得分1/(1+0.3*1),第二名得分1/(1+0.3*2),...以此类推。
在统计完用户之间的相似度后,最相似的人看过的书将被加上1/(1+0.3*1)分,第二相似的人看过的书将被加上1/(1+0.3*2),...以此类推(可以累加)。然后得分最高的书在“相似用户推荐指标”上得分1/(1+0.3*1)分,第二名在该指标上得分1/(1+0.3*2),...以此类推。
在内容相似性指标上,与用户看过的内容相似度最高的书在“内容相似度指标”上得分1/(1+0.3*1)分,第二相似的书在该指标得分1/(1+0.3*2)分,...以此类推。
最终推荐的30本书是在三个领域内得分相加后分数最高的30本书。
实例程序:
1.制作最终结果:
a.生成结果文件result.xlsx
prepare(test=False,1,1,13,1)// 准备推荐所需要的信息,使用2019.1.1-2019.12.31的信息
make_pickle('1_1_13_1')//保存以便日后使用
load_pickle(‘1_1_13_1’)//加载推荐所需要的信息,使用2019.1.1-2019.12.31的信息
predict_result()//推荐并生成结果文件result.xlsx
b.生成包括题目名称的结果文件
enhanced_xlsx_maker()//在result.xlsx已经生成后再运行,结果保存在enhanced_result.xlsx中
2.对单一用户进行推荐
recommend(None, 35471, 1,1,1)//对id号为35471的用户进行推荐,使用全部三项指标
recommend(None, 35471, 1,1,0)//对id号为35471的用户进行推荐,不使用内容相似性指标
3.测试
用前8个月的数据作为训练集,用后4个月的数据作为测试集,根据用户在前8个月的借书数据预测其在后4个月内的行为。
a.简单推荐30本最流行的书
prepare(test=False,1,1,9,1)// 准备推荐所需要的信息,使用2019.1.1-2019.8.31的信息
make_pickle('1_1_9_1')//保存以便日后使用
load_pickle(‘1_1_9_1’)//加载推荐所需要的信息,使用2019.1.1-2019.8.31的信息
more_advanced_eval(num=100, popularity_weight=1, context_weight=0, friend_weight=0)//进行测试
结果:测试分数0.4。即平均每位用户推荐成功0.4本书。
b.仅仅使用协同过滤法
load_pickle(‘1_1_9_1’)//加载推荐所需要的信息,使用2019.1.1-2019.9.1的信息
more_advanced_eval(num=100, popularity_weight=0, context_weight=0, friend_weight=1)//进行测试
结果:测试分数0.8。即平均每位用户推荐成功0.8本书。
c.流行度+协同过滤
load_pickle(‘1_1_9_1’)//加载推荐所需要的信息,使用2019.1.1-2019.9.1的信息
more_advanced_eval(num=100, popularity_weight=0.8, context_weight=0, friend_weight=1)//进行测试
结果:测试分数0.81。即平均每位用户推荐成功0.81本书。
d.流行度+协同过滤+内容相似性分析
load_pickle(‘1_1_9_1’)//加载推荐所需要的信息,使用2019.1.1-2019.9.1的信息
more_advanced_eval(num=100, popularity_weight=1, context_weight=1, friend_weight=1)//进行测试
结果:测试分数0.88。即平均每位用户推荐成功0.88本书。
测试结果:
流行度 协同过滤 流行度+协同过滤 流行度+协同过滤+内容相似性分析
推荐成功率 0.4 0.8 0.81 0.88
结果举例:
读者id 推荐书例1 推荐书例2 推荐书例3 推荐书例4 推荐书例5
781 《外汇交易圣经》 《技术分析与股市盈利预测》 《交易心理训练》 《股票魔法师》 《期货程序化交易实战入门与技巧》
51534 《首席医官》 《武动乾坤》 《斗罗大陆》 《魔兽战神》 《星辰变》
显然,id号为781的读者很可能是一名交易员,而id号为51534的读者可能非常喜欢阅读网络文学。这表明,算法可以根据读者的喜好有针对性地进行图书推荐。
存在问题:
数据接口上由于目前联编书库数据无法和流通记录中书本id对应,没有办法在联编书库中使用协同过滤算法。考虑到推荐算法的有效性和完整性,我们最终决定保留协同过滤算法,但在结果文件只能给出推荐书目的id号,isbn号和索书号可能需要通过某种方式手动转换。以及“上海图书馆外借期刊”在数据集中缺失了其进一步的详细信息,有可能该类别的书和普通书籍的分类方式有所不同,可能需要特殊处理。
总结:
经过测试,协同过滤模型是推荐效果提升中的主要部分,同时使用内容相似性分析也可以带来明显的提升,流行度分析能带来一定的提升。通过将三个模型进行有机融合所产生的多模态模型比起任意单一模型效果都产生了显著的提升。但是,内容相似性分析需要消耗大量计算资源,在对计算时间敏感的情况下可能需要进行有效的近似处理。

















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









