




 本文探讨了Hadoop分布式文件系统的工作原理及其存在的问题,并介绍了两种实现存算分离的解决方案,包括Hadoop兼容的文件系统和云原生的Hadoop文件系统DataSimba。
本文探讨了Hadoop分布式文件系统的工作原理及其存在的问题,并介绍了两种实现存算分离的解决方案,包括Hadoop兼容的文件系统和云原生的Hadoop文件系统DataSimba。
传统的 Apache Hadoop架构存储和计算是耦合在一起的, HDFS作为其分布式文件系统也存在诸多不足。那么,如何实现Hadoop的存算分离,以规避HDFS的问题、降低成本、提升性能?
在「数智·云原生」系列直播课的第三讲,奇点云数据平台后端架构专家纯粹带来了《云原生数据存储管理》,回顾Hadoop分布式文件系统的工作原理,解析存在的问题,并探讨Hadoop存算分离如何在DataSimba上实现。
纯粹,奇点云数据平台后端架构专家。数据中台云原生后端研发负责人,曾在多家互联网科技公司担任PaaS骨干。

(*正文为直播精选,点击文末「阅读原文」即可收看完整回放)
01、Hadoop分布式文件系统
在探讨如何实现存算分离来优化数据存储之前,我们先通过一张图来回顾Hadoop分布式文件系统的架构。从图中我们可以发现3个角色,分别是Namenode,Client,以及Datanodes。
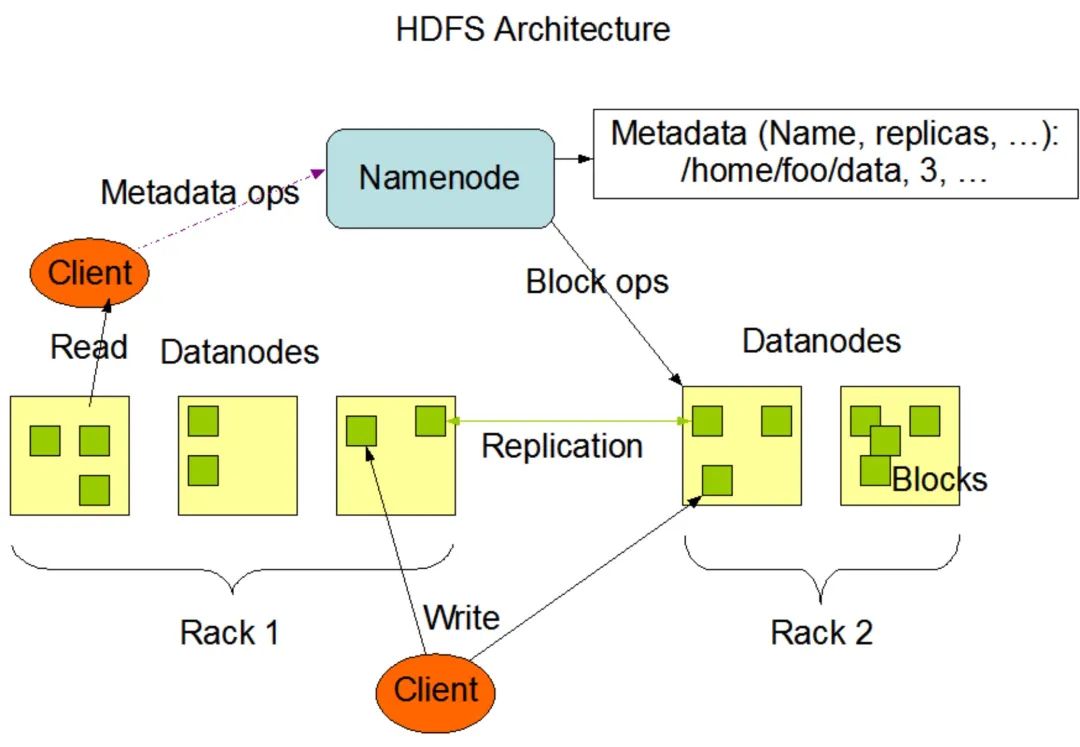
其中,Client是用户操作HDFS文件系统进行创建、删除、移动或重命名操作的客户端。Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)和客户端对文件的访问。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件或目录。同时,Namenode也负责确定数据块到具体Datanode节
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1263
1263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









