




 本文探讨了Hadoop传统架构的问题,并介绍了实现存算分离的两种方案。通过引入云存储和自研文件缓存层,有效解决了计算与存储资源不匹配的问题,提升了系统性能。
本文探讨了Hadoop传统架构的问题,并介绍了实现存算分离的两种方案。通过引入云存储和自研文件缓存层,有效解决了计算与存储资源不匹配的问题,提升了系统性能。
写在前面
这是奇点云全新技术专栏「StartDT Tech Lab」的第3期。
在这里,我们聚焦数据技术,分享方法论与实战。一线的项目经历,丰富的实践经验,真实的总结体会…我们畅想未来大趋势,也关注日常小细节。
本篇由奇点云数据平台后端架构专家「纯粹」带来:

作者:纯粹
阅读时间:约10分钟
众所周知传统的Apache Hadoop的架构存储和计算是耦合在一起的,HDFS(Hadoop Distributed File System)作为其分布式文件系统也面临一些问题。如:存储空间或者计算资源不足时,两者只能同时扩容、扩容效率低、额外增加成本、灵活性差等。
本文会和大家回顾Hadoop的传统架构来分析上述问题,介绍Hadoop实现存算分离的方案,并分享我们DataSimba对于Hadoop存算分离的最佳实践。
Hadoop分布式文件系统
(HDFS)的架构和问题
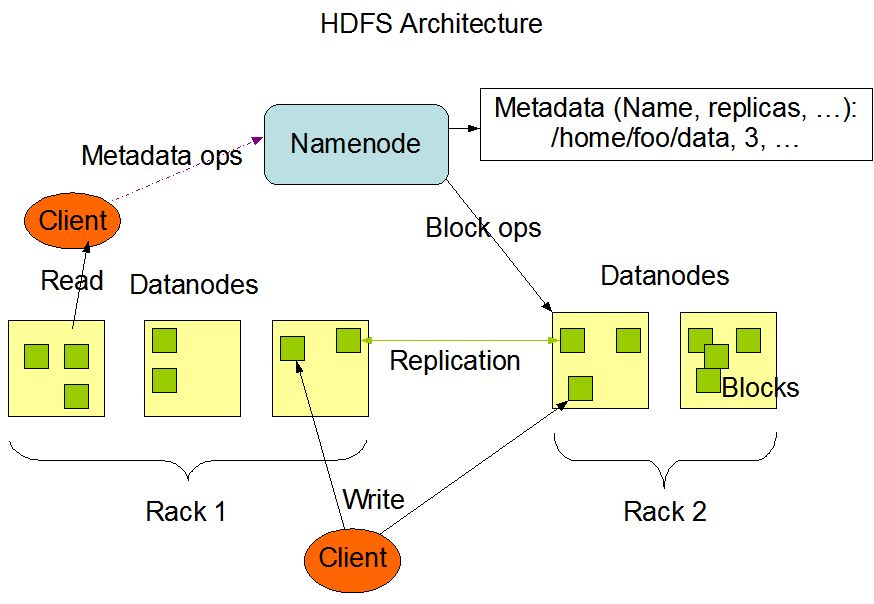
HDFS的架构(图源:Hadoop)
上图是Hadoop官方对于HDFS的架构图,我们重新回顾一下,一个HDFS集群由一个Namenode和一定数目的Datanode组成。Namenode是中心服务器,负责整个文件系统的namespace和客户端的访问,比如打开、关闭、重命名文件或目录,同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









