



官网:https://www.ccopyright.com.cn/
一、 注册账号
1、点击右上角注册

也有可能出现以下页面,点击个人用户,再点击注册

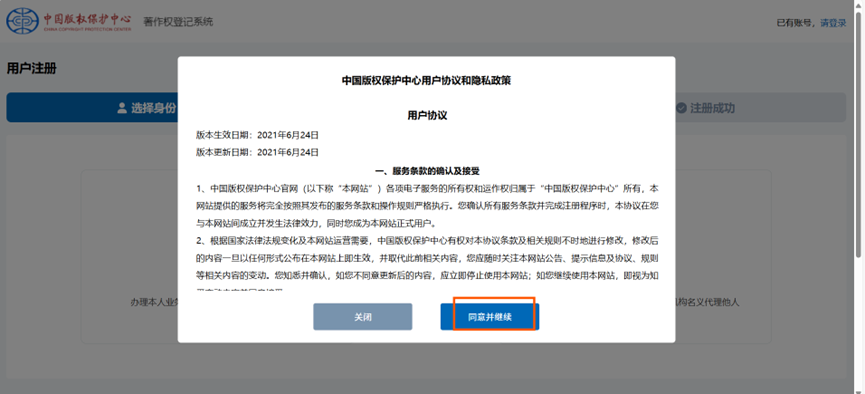
2、点击同意并继续
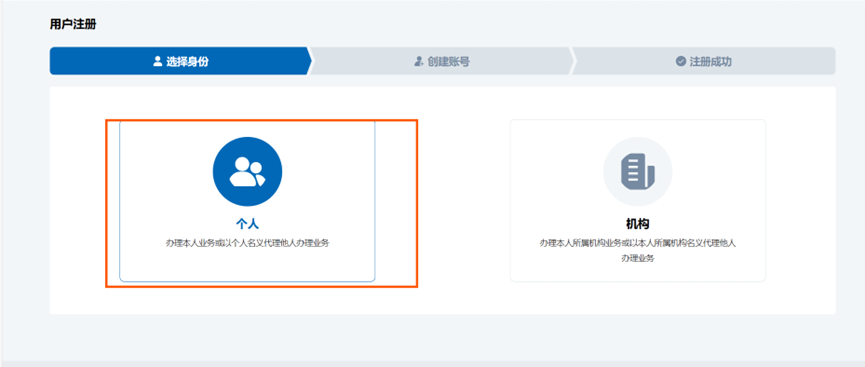
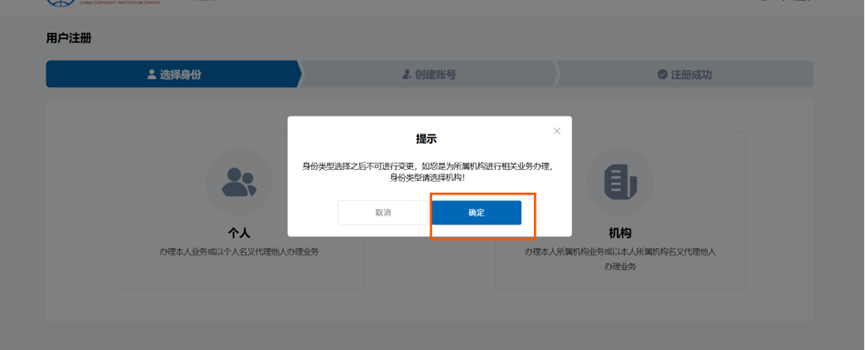
3、点个人
4、正确填写信息
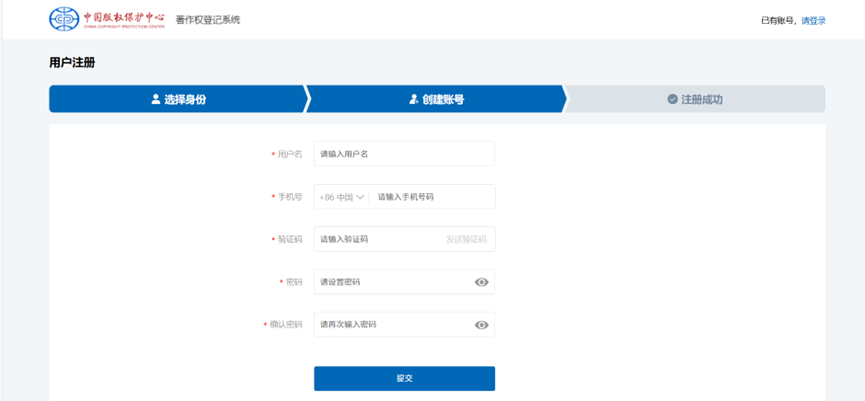
(这里的用户名相当于昵称,不需要写真名)
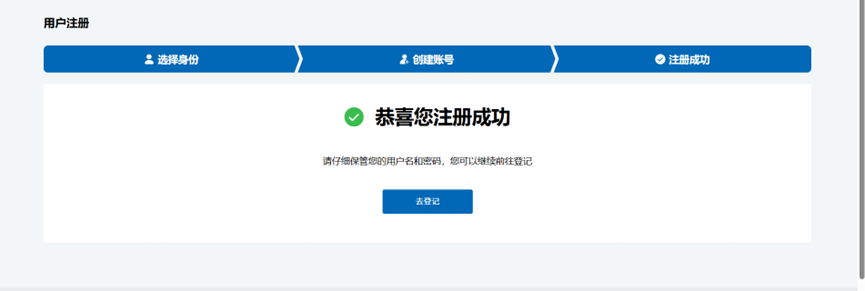
设置好了之后,会有提示,根据提示点击(去登记)
二、 实名认证
1、 点击第一个

如果你当前的页面是用户中心,你可以点击版权登记就可以返回到前一个页面了

2、点击第一个
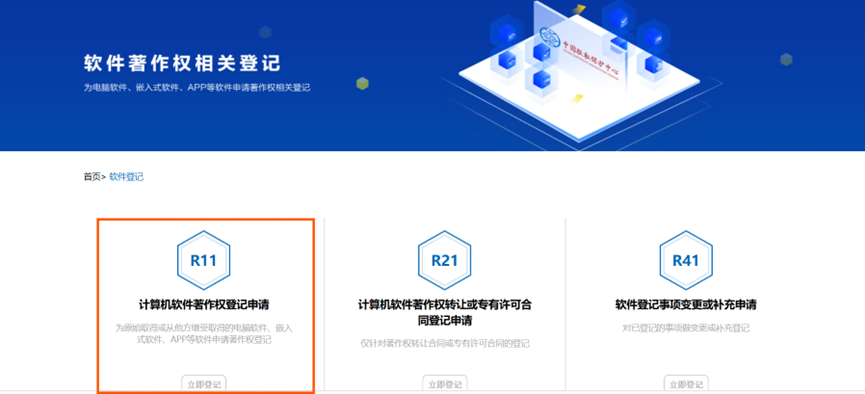
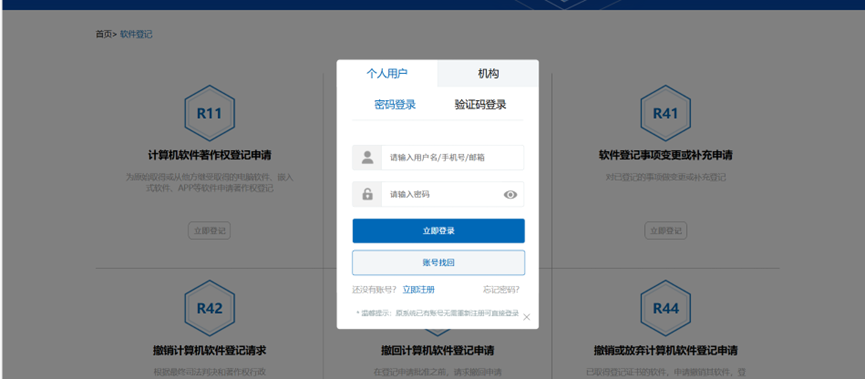
3、重新登录
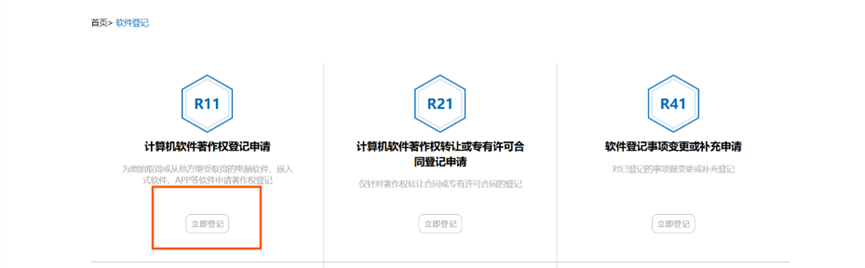
4、再次点击第一个
5、前往实名认证

6、输入邮箱,可以用QQ邮箱
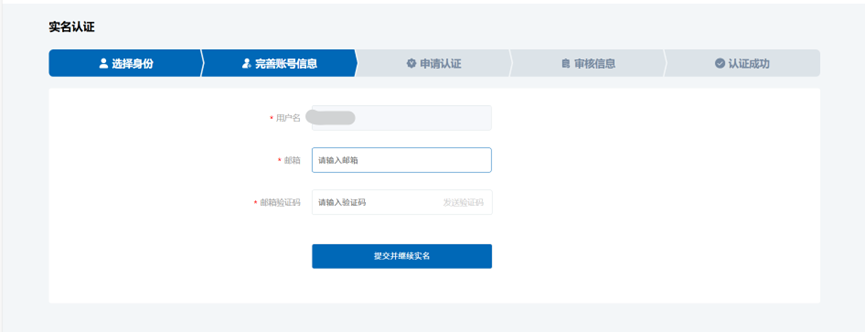
7、填写个人实名信息,并确认
8、提交后,等待审核通知,需要1-3个工作日。审核通过后就可以开始申请软著了
通常失败的原因:
1、手持身份证:必须他拍,不能自拍;不能镜子反向,不能手指遮挡,手持身份证边缘,身份证信息可以看清楚,身份证放于胸前。
2、信息按照身份证上的填写,城市省份必须写认证的身份证上的。
看实名是否通过:
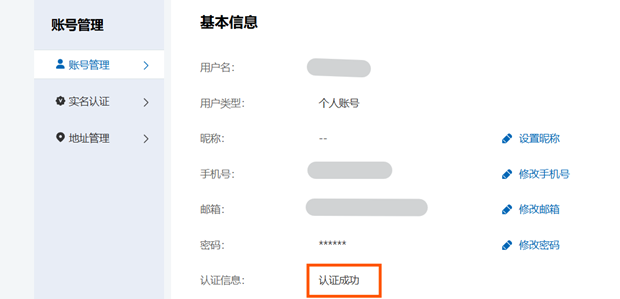
点右上角有个用户中心,找账号管理,点进去。会显示认证成功或者失败,失败则需按照提示重新认证。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









