




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
📘📚 所属专栏:传知代码论文复现
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
本文选自ICLR2022的论文"Entroformer: A Transformer-based Entropy Model for Learned Image Compression",源码可在附件中查看
总体介绍
本文介绍了Entroformer,一种基于Transformer的熵模型,用于深度学习图像压缩。与传统的基于卷积神经网络的熵模型不同,Entroformer利用Transformer的自注意力机制有效捕捉全局依赖性,并在图像压缩中实现了高效的概率分布估计。此外,本文提出了一个并行双向上下文模型,加速了解码过程。实验表明,Entroformer在图像压缩任务中表现优异,同时具有较高的时间效率。
背景
图像压缩是计算机视觉中的基础研究领域,随着深度学习的发展,学习方法在这一任务中取得了多项突破。当前最先进的深度图像压缩模型建立在自编码器框架上,使用熵模型估计潜在表示的条件概率分布。本文旨在提高熵模型的预测能力,从而在不增加失真的情况下提高压缩率。
提出方法
超先验与上下文模型的压缩
熵模型有多种类型,如超先验模型、上下文模型和组合方法。超先验方法通常利用量化潜在表示的附加信息,而上下文模型则通过自回归先验结合潜在的因果上下文进行预测。Entroformer结合了基于超先验和上下文模型的方法,提高了压缩效率。

图1 (b)即为(a)中熵模型使用Transformer的改进
Transformer-based 熵模型
Transformer架构
Entroformer采用Transformer的编码器-解码器结构,使用自注意力机制关联不同位置的潜在表示,捕捉图像的空间和内容依赖性。此外,本文提出了多头注意力和top-k选择机制,以提取精确的概率分布依赖关系。
位置编码
为了在图像压缩中提供更好的空间表示,Entroformer设计了一种基于相对位置编码的单位,该编码采用菱形边界,嵌入了图像压缩中的距离先验知识。

图2 相对位置编码
Top-k 自注意力机制
在自注意力机制中,Entroformer选择top-k最相似的关键点来计算注意力矩阵,从而减少不相关信息的干扰,稳定训练过程。
并行双向上下文模型
通过双向上下文模型,Entroformer在保持性能的同时,加速了解码过程。与传统的单向上下文模型相比,双向模型引入了未来上下文,提高了预测的准确性。
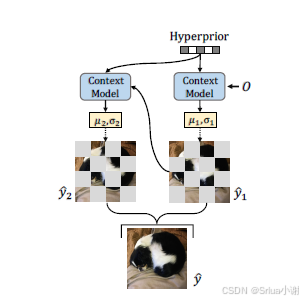
图3 双向上下文模型
实验结果
实验通过计算率-失真性能(RD)评估了Entroformer的效果。结果表明,Entroformer在低比特率下比最先进的卷积神经网络方法提高了5.2%,比标准编解码器BPG提高了20.5%。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









