




✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。
我是Srlua小谢,在这里我会分享我的知识和经验。🎥
希望在这里,我们能一起探索IT世界的奥妙,提升我们的技能。🔮
记得先点赞👍后阅读哦~ 👏👏
欢迎访问我的主页:Srlua小谢 获取更多信息和资源。✨✨🌙🌙



目录
本文所有资源均可在该地址处获取。
概述
本文复现论文 Wide Residual Networks[1] 提出的深度神经网络模型。
为了解决深度神经网络梯度消失的问题,深度残差网络(Residual Network[2])被提出。然而,仅为了提高千分之一的准确率,也要将网络的层数翻倍,这使得网络的训练变得非常缓慢。为了解决这些问题,该论文对ResNet基本块的架构进行了改进并提出了一种新颖的架构——宽度残差网络(Wide Residual Network),其减少了深度并增加了残差网络的宽度。
我基于Pytorch复现了该网络并在CIFAR-10[3]、CIFAR-100[3]和SVHN[4]数据集上进行试验。此外,我提供了一个基于SVHN数据集训练的数字识别系统用于体验。
模型结构
宽度残差网络共包含四组结构。其中,第一组固定为一个卷积神经网络,第二、三、四组都包含 nn 个基本残差块。
基本残差块的结构如图所示:
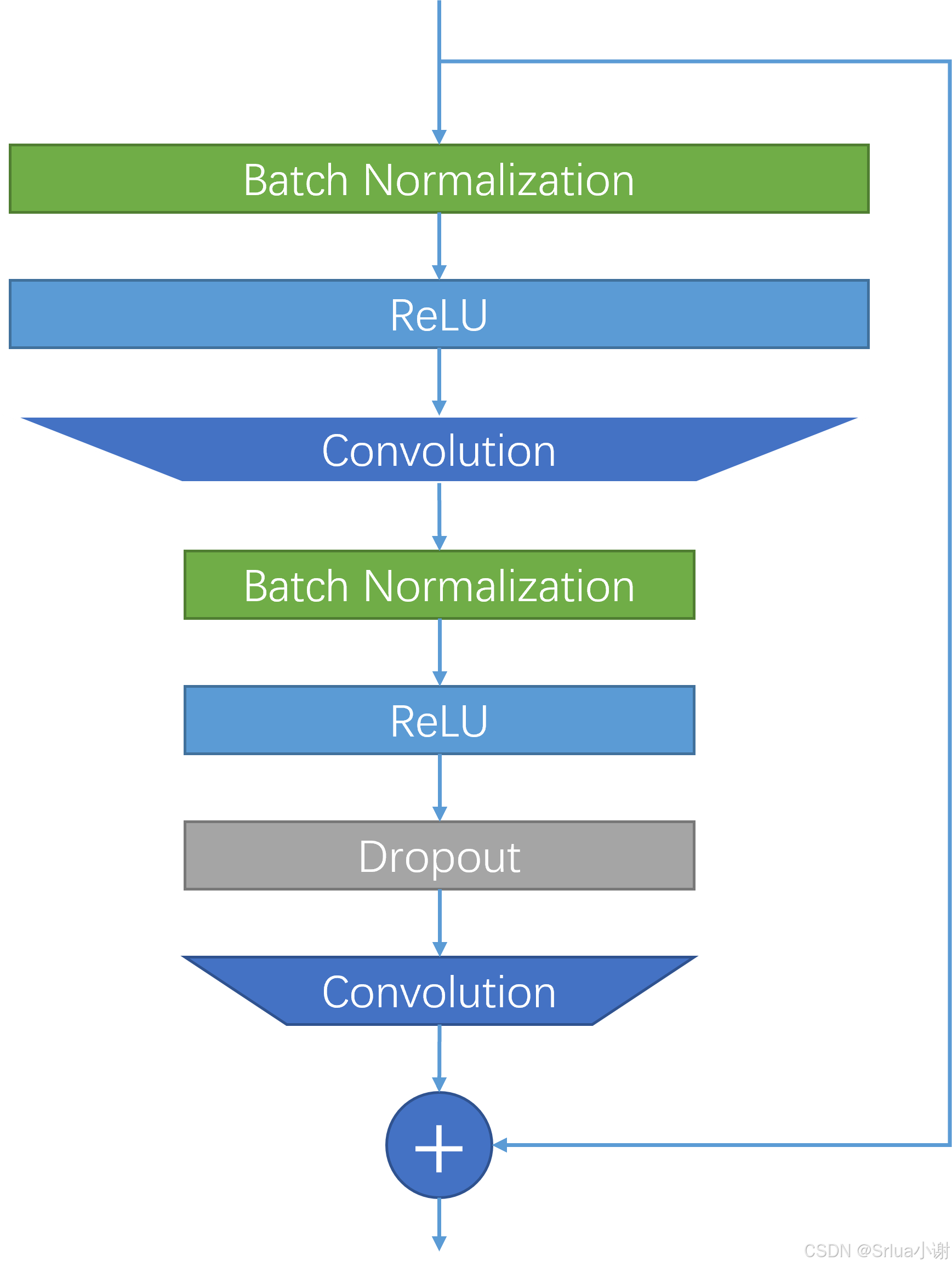
与普通的残差块不同的地方在于,普通残差块中的批归一化层和激活层都放在卷积层之后,而该论文将批归一化层和激活层都放在卷积层之前,该做法一方面加快了计算,另一方面使得该网络可以不需要用于特征池化的瓶颈层。此外,宽度残差网络成倍地增加了普通残差网络的特征通道数。
宽度残差网络在第三、四组的第一个卷积层进行下采样,即设置卷积步长为2。
核心逻辑
Wide Residual Network 的模型代码如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
class WideBasicBlock(nn.Module):
"""Wide Residual Network的基本单元"""
def __init__(self, in_channels, out_channels, stride, dropout):
super(WideBasicBlock, self).__init__()
self.stride = stride
# 批归一化层、激活层、卷积层、Dropout层
self.layers = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inpla 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









