







 本文介绍了衡量分类问题准确度的关键指标,包括Precision、Recall及F1Score,详细解析了这些指标的计算方式及其在多分类器场景下的应用,强调了F1Score作为综合评估指标的重要性。
本文介绍了衡量分类问题准确度的关键指标,包括Precision、Recall及F1Score,详细解析了这些指标的计算方式及其在多分类器场景下的应用,强调了F1Score作为综合评估指标的重要性。
以下指标可以作为衡量分类问题的准确度的标准
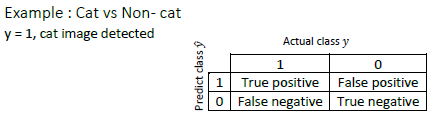
Precision
Precision(%)=True positivenumber of predicted positive∗100=True positiveTrue positive+False Positive∗100\frac{True \ positive}{number\ of \ predicted \ positive}*100=\frac{True \ positive}{True \ positive + False \ Positive}*100number of predicted positiveTrue positive∗100=True positive+False PositiveTrue positive∗100
Recall
Recall(%)=True positivenumber of actually positive∗100=True positiveTrue positive+False Negative∗100\frac{True \ positive}{number\ of \ actually \ positive}*100=\frac{True \ positive}{True \ positive + False \ Negative}*100number of actually positiveTrue positive∗100=True positive+False NegativeTrue positive∗100
说明
当你有多个Classifiers时,每一个Classifier的Precision和Recall可能都不一样,而且Precision和Recall之间是存在取舍关系的。因此以Precision和Recall作为衡量指标是不太可行的,你无法一眼看出哪个Classifier表现得更好。
直观而言,你会想到以(Precision+Recall)/2(Precision+Recall)/2(Precision+Recall)/2作为一个单一的度量指标,但直接求平均数并不太科学,我们有更好的求平均的方法F1 Score,称作调和平均(Harmonic)。
F1 Score
F1Score=2PR1P+1RF_1Score=\frac{2PR}{\frac{1}{P}+\frac{1}{R}}F1Score=P1+R12PR
你可以简单理解F1 Score为P和R的“平均”。
百度百科里有全面的解释:

使用Dev Set和单一的评估标准能够加速你学习的迭代过程。

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









