




 本文探讨深度学习模型评估中的关键指标,如精度、混淆矩阵,以及为何精度并非最佳评价标准。通过实例解析Precision、Recall和F1分数的含义,以及如何通过ROC曲线理解模型性能。重点在于理解这些指标在实际应用中的权衡和选择。
本文探讨深度学习模型评估中的关键指标,如精度、混淆矩阵,以及为何精度并非最佳评价标准。通过实例解析Precision、Recall和F1分数的含义,以及如何通过ROC曲线理解模型性能。重点在于理解这些指标在实际应用中的权衡和选择。
深度学习之模型评估Evaluation Metric
精度Accuracy
精度是指测试正确的与全部测试样例的比值。
A
c
c
u
r
a
c
y
=
N
u
m
b
e
r
o
f
c
o
r
r
e
c
t
p
r
e
d
i
c
t
i
o
n
s
T
o
t
a
l
n
u
m
b
e
r
o
f
p
r
e
d
i
c
t
i
o
n
s
m
a
d
e
Accuracy = \frac{Number of correct predictions}{Total number of predictions made}
Accuracy=TotalnumberofpredictionsmadeNumberofcorrectpredictions
但是精度有误导性。比如说我们有100个测试样本,我们正确预测了98个,有两个预测失败,但是我们不知道是哪两个!
混淆矩阵
| 真实|预测 | Positive | Negative |
|---|---|---|
| Positive | True Positive(TP) | False Positive(FP) |
| Negative | False Negateive(FN) | True Negative(TN) |
为了更加方便的表示预测结果与真实结果之间的差距,我们可以利用混淆矩阵来表示。
TP表示真阳,实际阳性,预测阳性
FP表示假阳,实际阴性,预测阳性
TN表示真阴,实际阴性,预测阴性
FN表示假阴,实际阳性,预测阴性
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
F
P
+
T
N
+
F
N
Accuracy = \frac{TP+TN}{TP+FP+TN+FN}
Accuracy=TP+FP+TN+FNTP+TN
Accuracy表示预测到正确的(包括阳性和阴性)与全部预测样本的比值。
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
Precision = \frac{TP}{TP + FP}
Precision=TP+FPTP
Prcision表示真阳与预测结果中阳性(真阳和假阳)的比值。
R
e
c
a
l
l
=
T
P
T
P
+
F
N
Recall = \frac{TP}{TP+FN}
Recall=TP+FNTP
Recall表示真阳与实际阳性(真阳和假阴)的比值。
一个好的模型Precision和Recall都要高。
例如:
1、有100个样本,实际50个阳性,50个阴性。成功预测了一个为真阳,其他的全部预测为阴性。这种情况下:TP = 1, FP = 0, FN = 49, TN = 50。Precison = 100%(预测一个为阳性,并且是真阳)但是Recall = 2%!!!这样显然是不行的。
2、有100个样本,实际50个阳性,50个阴性。全部预测为阳性。这种情况下TP = 50,FP = 50,FN = 0, TN = 0。Precision = 50%,Recall = 100%。
这样显然也是不行的。所以要结合这两个,这就引入出下面的F1值。
小记:TP,FP都是预测为P,TN,FN都是预测为N。带P的都是预测为P,带N的都是预测为N。带T的都是真的,带N的都是反的。T和F指的是实际值,P与N是预测值
F
1
=
2
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F1 = \frac{2*Precision*Recall}{Precision + Recall}
F1=Precision+Recall2∗Precision∗Recall
T
P
R
=
T
P
T
P
+
F
N
TPR = \frac{TP}{TP + FN}
TPR=TP+FNTP
TPR 与 Recall一样,都是真阳在实际阳性中的比例
F
P
R
=
F
P
F
P
+
T
N
FPR = \frac{FP}{FP + TN}
FPR=FP+TNFP
FPR是假阳在实际阴性中的比例
ROC曲线如下图:
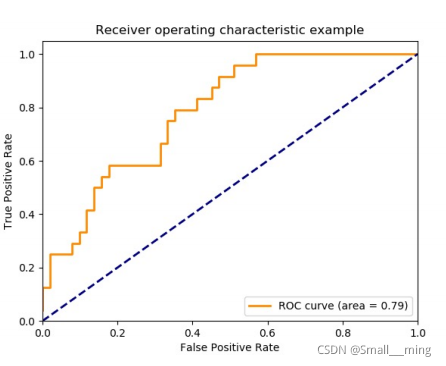
总结
TP,FP都是预测为P,TN,FN都是预测为N。带P的都是预测为P,带N的都是预测为N。带T的都是真的,带N的都是反的。T和F指的是实际值,P与N是预测值



















 28
28

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









