



ollvm
收集信息
无壳,elf文件,64位
拖入ida64,一看先是被吓了一跳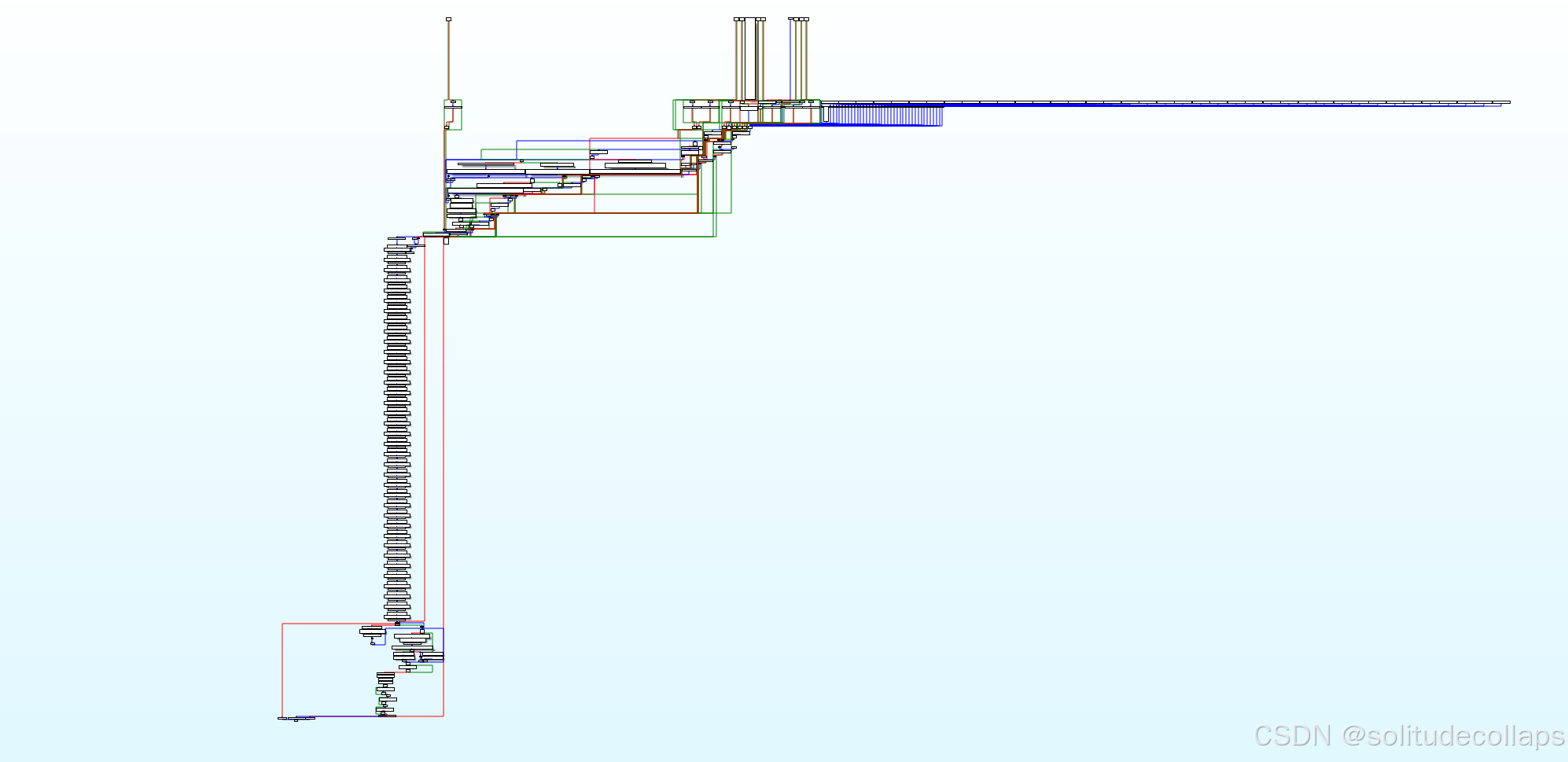
这么多流程,结合题目名字,我一开始认为这道题是ollvm平坦化混淆,第一反应是去olllvm平坦化
ollvm去平坦化
argc符号执行
Miasm符号执行
代码直接分析
v124 = 0;
v123 = argc;
v122 = argv;
if ( argc == 2 )
{
if ( strlen(v122[1]) == 38 )
{
i = 0;
j = 0;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v119, 1LL);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v118);
v22 = v116;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v22);
v22 += 16;
}
while ( v22 != v117 );
v115 = 0;
for ( i = 0; ; ++i )
{
v21 = i;
if ( v21 >= strlen(v122[1]) )
break;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(v119, 1LL);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(v118, (unsigned int)(v122[1][i] - v115));
for ( j = 0; j < 5; ++j )
{
v114[0] = operator*<__mpz_struct [1],__mpz_struct [1],__mpz_struct [1],__mpz_struct [1]>(v119, v118);
v114[1] = v3;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,__gmp_binary_multiplies>>(
v119,
v114);
}
v113[0] = operator%<__mpz_struct [1],__mpz_struct [1]>(v119, 323LL);
v113[1] = v4;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,long,__gmp_binary_modulus>>(
&v116[i],
v113);
}
v20 = (__int64 *)v111;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v20);
v20 += 2;
}
while ( v20 != &v112 );
v109[0] = operator-<__mpz_struct [1],__mpz_struct [1]>(v116, 0LL);
v109[1] = v5;
v6 = strlen(v122[1]);
v110[0] = operator+<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,long,__gmp_binary_minus>>(
v109,
v6);
v110[1] = v7;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,long,__gmp_binary_minus>>,unsigned long,__gmp_binary_plus>>(
v111,
v110);
for ( i = 1; ; ++i )
{
v19 = i;
if ( v19 >= strlen(v122[1]) )
break;
v108[0] = operator+<__mpz_struct [1],__mpz_struct [1],__mpz_struct [1],__mpz_struct [1]>(&v116[i], &v116[i - 1]);
v108[1] = v8;
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=<__mpz_struct [1],__gmp_binary_expr<__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,__gmp_expr<__mpz_struct [1],__mpz_struct [1]>,__gmp_binary_plus>>(
&v111[i],
v108);
}
v18 = (__int64 *)v107;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v18);
v18 += 2;
}
while ( v18 != v108 );
std::allocator<char>::allocator(v105);
std::string::basic_string(
1. 输入验证
if (argc == 2) {
if (strlen(INPUT[1]) == 38) {
...
}
}
-
要求程序的参数数量为 2,并且输入的字符串长度为 38。
-
如果不满足条件,程序将不会继续执行。
2. 初始化
oo2::MemsetQuantum_Test((oo2 *)v119, (const unsigned __int8 *)1); __gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr((__int64)v118);
-
使用
GMP大数库,初始化变量v119和v118。 -
oo2::MemsetQuantum_Test可能是某种自定义初始化函数,给定默认值1。
3. 核心循环
for (i = 0; i < strlen(INPUT[1]); ++i) {
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(v119, 1LL);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(v118, (unsigned int)(INPUT[1][i] - v115));
for (j = 0; j < 5; ++j) {
v114[0] = operator*<...>(v119, (size_t)v118); // v119 = v119 * v118
rcs::analytics::Event::operator=(v119, v114);
}
v113[0] = operator%<...>(v119, 323LL); // v113[0] = v119 % 323
__gmp_expr<...>::operator=(&v116[i], v113); // 保存结果到 v116[i]
}
-
每个字符(
INPUT[1][i]
)经过以下数学运算:
-
初始化
v119 = 1。 -
将字符减去一个偏移量
v115,结果存入v118。 -
计算字符的 5 次幂:
v119 = (INPUT[1][i] - v115)^5。 -
将结果取模 323,存入
v116[i]。
-
此循环的作用是将输入的每个字符转化为一个与其相关的数值,便于后续验证。
4. 结果验证
for (i = 1; i < strlen(INPUT[1]); ++i) {
v108[0] = operator+<...>(&v116[i], &v116[i - 1]); // v116[i] + v116[i - 1]
__gmp_expr<...>::operator=(&v111[i], v108); // 保存结果到 v111[i]
}
-
计算数组
v116中相邻元素的和,并存入v111。 -
这可能是对转换后的值再进行一次处理,以增加难度。
中间部分是一堆大数的赋值和比较
for ( i = 38; i < 0x64; ++i )
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v24, 4267316LL, 0LL);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(&v63[16 * i], v24);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v24);
}
for ( i = 0; ; ++i )
{
v16 = i;
if ( v16 >= strlen(v122[1]) )
break;
encrypt(v23, &v111[i], v101, v102);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(&v107[i], v23);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v23);
if ( (operator!=<__mpz_struct [1],__mpz_struct [1],__mpz_struct [1],__mpz_struct [1]>(&v107[i], &v63[16 * i]) & 1) != 0 )
{
v15 = std::operator<<<std::char_traits<char>>(&_bss_start, (unsigned int)"wrong flag.");
std::ostream::operator<<(v15, (unsigned int)&std::endl<char,std::char_traits<char>>);
v124 = 0;
goto LABEL_31;
}
}
v14 = std::operator<<<std::char_traits<char>>(&_bss_start, (unsigned int)"bingo!");
std::ostream::operator<<(v14, (unsigned int)&std::endl<char,std::char_traits<char>>);
v124 = 0;
LABEL_31:
v13 = v101;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v13 - 16);
v13 -= 16;
}
while ( v13 != v63 );
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v101);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v102);
std::string::~string(v104);
std::string::~string(v106);
v12 = v108;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v12 - 2);
v12 -= 2;
}
while ( v12 != (__int64 *)v107 );
v11 = &v112;
do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v11 - 2);
v11 -= 2;
}
while ( v11 != (__int64 *)v111 );
v10 = v117;
do
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(--v10);
while ( v10 != v116 );
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v118);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v119);
}
else
{
v124 = 0;
printf("flag require 38 chars");
}
}
else
{
v124 = 0;
printf("Command line parameter error.");
}
return v124;
}
第一个 for 循环
for ( i = 38; i < 0x64; ++i )
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(v24, 4267316LL, 0LL);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(&v63[16 * i], v24);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v24);
}
-
功能
:
-
该循环从索引
38开始到0x64(即100),对每个i生成一个 GMP 表达式并赋值到v63的相应位置。
-
-
过程
:
-
v24被初始化为值4267316。 -
将
v24的值赋值给v63的16 * i偏移处。 -
销毁
v24对象。
-
-
目的
:
-
初始化
v63的特定区域,可能是用于后续比较的参考值。
-
第二个 for 循环
cpp复制编辑for ( i = 0; ; ++i )
{
v16 = i;
if ( v16 >= strlen(v122[1]) )
break;
encrypt(v23, &v111[i], v101, v102);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::operator=(&v107[i], v23);
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v23);
if ( (operator!=<__mpz_struct [1],__mpz_struct [1],__mpz_struct [1],__mpz_struct [1]>(&v107[i], &v63[16 * i]) & 1) != 0 )
{
v15 = std::operator<<<std::char_traits<char>>(&_bss_start, (unsigned int)"wrong flag.");
std::ostream::operator<<(v15, (unsigned int)&std::endl<char,std::char_traits<char>>);
v124 = 0;
goto LABEL_31;
}
}
-
功能:
-
遍历输入字符串的每个字符,并对其执行加密操作。
-
将加密结果与之前的初始化值
v63的对应部分进行比较。
-
-
过程:
-
v16是循环索引,逐个字符处理v122[1](输入字符串)。 -
调用
encrypt函数对输入字符串的当前字符进行加密,结果存储在v23。 -
将
v23的值赋值到v107[i]。 -
如果
v107[i]和v63[16 * i]不相等,表示当前字符错误,打印"wrong flag."并跳转到清理代码块。
-
-
目的:
-
核心功能是校验输入字符串的每个字符是否正确。
-
如果某个字符不正确,会立即退出循环并提示错误。
-
校验成功的情况
cpp复制编辑v14 = std::operator<<<std::char_traits<char>>(&_bss_start, (unsigned int)"bingo!"); std::ostream::operator<<(v14, (unsigned int)&std::endl<char,std::char_traits<char>>); v124 = 0;
-
如果所有字符都通过校验,打印
"bingo!"表示输入正确。
清理代码块
cpp复制编辑do
{
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::~__gmp_expr(v13 - 16);
v13 -= 16;
} while ( v13 != v63 );
-
功能:
-
销毁 GMP 对象,释放动态分配的内存。
-
遍历多个动态数组,包括
v63、v107、v111等,依次销毁其内部的 GMP 表达式对象。
-
-
目的:
-
避免内存泄漏,完成程序清理工作。
-
输入长度检查
cpp复制编辑else
{
v124 = 0;
printf("flag require 38 chars");
}
-
如果输入字符串长度不足 38 个字符,打印提示
"flag require 38 chars"。
命令行参数错误
cpp复制编辑else
{
v124 = 0;
printf("Command line parameter error.");
}
-
如果命令行参数数量不符合要求,打印提示
"Command line parameter error."。
encrypt函数分析
__gmp_expr<__mpz_struct [1],__mpz_struct [1]>::__gmp_expr(a1); mpz_t = __gmp_expr<__mpz_struct [1],__mpz_struct [1]>::get_mpz_t(a1); v7 = __gmp_expr<__mpz_struct [1],__mpz_struct [1]>::get_mpz_t(a2); v6 = __gmp_expr<__mpz_struct [1],__mpz_struct [1]>::get_mpz_t(a3); v5 = __gmp_expr<__mpz_struct [1],__mpz_struct [1]>::get_mpz_t(a4); __gmpz_powm(mpz_t, v7, v6, v5); return a1;
result=(base^exp)mod mod
其中:
-
result存储在a1中。 -
base是a2的值。 -
exp是a3的值。 -
mod是a4的值。
RSA
函数逻辑简化整理
assert len(flag) == 38
v120 = [pow(i, 5, 323) for i in flag]
v114 = v120[38] + [v120[i-1]+v120[i] for i in range(1, 38)]
for i,v in enumerate(v114):
if pow(v,e,n) != v63[i]:
break
else:
print("OK")
脚本
#
'''
assert len(flag) == 38
v120 = [pow(i, 5, 323) for i in flag]
v114 = v120[38] + [v120[i-1]+v120[i] for i in range(1, 38)]
for i,v in enumerate(v114):
if pow(v,e,n) != v63[i]:
break
else:
print("OK")
'''
v63 = [
......这个数据在原程序里,一共38个大大大的数......
]
n = 102651473104605400881443209436335207143364593902607831104659513254775518923447923418776053184964127417292310751110954018379230925038183526950825957076822861193097601598650310458833168757490447855063621089262488908245458996608300475771810218545021100532975095664160301297355685288040601637561442455179633110079846710134322730324284152857852000538712290118985202146945804609486282114958343308956178741452118058076488074220293303425550534104695916297651437260840156614208398265649572936591070707149727591261946573549966777759067945870542262596595729532884877741113485459644140649532472144766397594354234108576755815917168003359597993072007662182342629809152936969421895552780144527391604982975657819198048361600023456702313892160810273481932944137974282216381637292972896247123735265111606267014480229602366343234386044792316318028789845062796141719269577108623503432313385433912012680162134432871999515572195678215741149038561107783321860080221501590006190270380869307116405522430479782169008415898242325411271043447827685653357582905940740125675545255630155684164945409286389585255976330122263610987012875989116119004168237430091958750377684385918076049811463810026787681970329875350154256541485562299929744955216059064911687028831046268556619196694147338675484825249402694136964225868844636091765013673567792490217775308571769318669397501731133181116010571526812759760618304461298242712032781458409426120142005834592865613957784145176085762288081896026523415885624361265385011667667343515890459493297688753
e = 41609
t = [0]*38
for i in range(38):
for j in range(323*2):
k = pow(j,e,n)
if k == v63[i]:
t[i] = j
break
print(t)
#t = [85,335,338,235,410,512,529,423,267,327,370,232,188,170,169,192,239,179,179,300,356,394,336,212,196,355,471,459,437,448,506,472,256,134,318,317,265,188]
tab = [pow(i,5,323) for i in range(0x7f)]
for i in range(0x20,0x7f):
v = pow(i, 5, 323)
if v<t[1]:
r = [0]*38
r[0] = v
for j in range(1,38):
r[j] = t[j]-r[j-1]
if r[j]<0 or (r[j] not in tab):
break
else:
flag = [tab.index(k) for k in r]
print(bytes(flag))
#QCTF{5Ym4aOEww2NcZcvUPOWKYMnPaqPywR2m}
RSA解密部分
Python复制
t = [0]*38 for i in range(38): for j in range(323*2): k = pow(j, e, n) if k == v63[i]: t[i] = j break
-
这段代码的目的是对
v63中的每个值进行RSA解密。 -
v63是一个长度为38的列表,每个元素是一个大整数。 -
n是RSA的模数,e是公钥指数。 -
程序通过暴力尝试
j的值(范围是0到646,即323*2),计算pow(j, e, n),直到找到一个j使得pow(j, e, n) == v63[i]。 -
如果找到这样的
j,则将j存入t[i]。
2. 差分序列还原部分
Python复制
tab = [pow(i, 5, 323) for i in range(0x7f)] for i in range(0x20, 0x7f): v = pow(i, 5, 323) if v < t[1]: r = [0]*38 r[0] = v for j in range(1, 38): r[j] = t[j] - r[j-1] if r[j] < 0 or (r[j] not in tab): break else: flag = [tab.index(k) for k in r] print(bytes(flag))
-
这部分代码的目的是还原一个差分序列。
-
tab是一个预计算的表,包含0到0x7f(即127)的所有数的五次方模323的结果。 -
程序尝试从
0x20到0x7f的所有可能的起始值i,计算pow(i, 5, 323),并将其作为差分序列的第一个值r[0]。 -
然后通过差分公式
r[j] = t[j] - r[j-1]逐步还原整个序列。 -
如果某个
r[j]小于0或者不在tab中,则中断当前尝试。 -
如果成功还原整个序列,则通过
tab.index(k)将每个r[j]映射回原始值,并将这些值转换为字节,最终输出flag。
动态插桩法()pintools
import subprocess
import time
st_time = time.time()
l = 38
table="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
now = 5
flag = "QCTF{"+"*"*33
prev_cnt = 11718047
while(1):
if(now>=37):
break
for x in table:
cmd = '../../../pin -t obj-intel64/inscount0.so -o ollvm.log -- ./ollvm '+\
flag[:now]+x+flag[now+1:]+\
'; cat ./ollvm.log'
output = subprocess.check_output(cmd,shell=True,stderr=subprocess.PIPE)
now_cnt = int(output.split(b'\n')[1].split()[1].decode())
# print(now_cnt)
if(now_cnt-prev_cnt>=1000000):
print(f"[+] RIGHT! {x}")
flag = flag[:now]+x+flag[now+1:]
now += 1
prev_cnt = now_cnt
break
else:
print("[+] ERROR !")
print(f'[+] Done!\ntime: {time.time()-st_time}')
print(f'\n[+]{flag}\n')
代码功能概述
-
目标: 通过逐字符尝试,利用指令执行计数的变化(
inscount0.so插桩工具生成),判断每个字符是否正确,从而逐步还原正确的flag。 -
假设:
-
如果尝试的字符是正确的,则程序的行为会发生显著变化(比如指令执行数增加)。
-
如果字符错误,则指令执行数的变化幅度较小或不符合预期。
-
核心逻辑
-
初始化:
-
st_time记录破解过程的开始时间。 -
l = 38表示flag的总长度。 -
table包含所有可能的字符(数字 + 大小写字母)。 -
flag初始化为QCTF{开头,后跟 33 个*作为占位符。 -
prev_cnt初始为指令执行计数的基准值,手动设置为11718047。
-
-
字符破解:
-
外层循环:
按顺序破解每一位字符。
-
now表示当前正在破解的字符位置(初始为 5)。
-
-
内层循环:
遍历
table
中所有可能的字符,逐一尝试。
-
调用
Pin工具运行目标程序,输入当前尝试的flag。 -
读取插桩工具生成的日志
ollvm.log,提取指令执行计数。 -
判断当前字符是否正确:
-
如果指令执行计数相比上一次增加超过 1,000,000,则认为当前字符正确,更新
flag。 -
否则继续尝试下一个字符。
-
-
-
-
结束条件:
-
如果所有字符(
now >= 37)破解完毕,结束循环。
-
-
输出:
-
打印破解完成所用时间。
-
输出最终破解的
flag。
-
改进建议
-
优化字符表:
-
如果有部分字符范围已知,可以缩小
table的范围,减少尝试次数。
-
-
动态调整
prev_cnt:-
prev_cnt是手动设置的基准值。若破解多个不同程序,可动态获取基准值代替硬编码。
-
-
增加错误处理:
-
目前对于异常(如
subprocess调用失败或日志解析失败)未处理,可增加捕获和重试机制。
-
-
减少系统调用开销:
-
如果
Pin或目标程序运行较慢,可以通过优化插桩工具或程序逻辑提高效率。
-
运行结果(示例)
如果 flag 是 QCTF{1234...},程序会逐步输出每一位正确字符。例如:
css复制编辑[+] RIGHT! Q
[+] RIGHT! C
[+] RIGHT! T
[+] RIGHT! F
...
[+] Done!
time: 62.384
[+] QCTF{correct_flag}
这段代码是一个典型的基于动态分析的爆破工具,主要依赖程序行为差异(如指令计数)来判断输入的正确性,非常适合用于破解具有复杂混淆的程序。
Q2384729
QC24333
QCTF{ }
您说:
逐行分析
ChatGPT 说:
ChatGPT
以下是代码的逐行分析和功能说明:
python复制编辑import subprocess import time
-
功能:
导入所需的模块。
-
subprocess: 用于执行系统命令(这里运行 Pin 工具)。 -
time: 用于记录破解开始和结束时间,计算耗时。
-
python 复制编辑 st_time = time.time()
-
功能: 记录破解开始时间,用于后续计算破解总耗时。
python 复制编辑 l = 38
-
功能: 定义
flag的长度为 38。这个长度是从目标程序分析中得出的。
python 复制编辑 table="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
-
功能: 定义所有可能的字符集合,包括数字、大写字母、小写字母。这是每个位置可能的字符候选集合。
python复制编辑now = 5
flag = "QCTF{"+"*"*33
prev_cnt = 11718047
-
功能:
-
now: 表示当前正在破解的字符位置,初始为 5(跳过QCTF{)。 -
flag: 初始化flag为QCTF{开头,后面用*占位符代替未知字符。 -
prev_cnt: 初始指令执行计数,用于后续判断当前字符是否正确。这个值是从初始运行或分析结果中获取的。
-
python复制编辑while(1): if(now >= 37): break
-
功能:
-
无限循环,直到破解到第 37 位(从 0 开始计数,即破解完成第 38 个字符)。
-
出口条件:
now >= 37,即所有字符已破解完成。
-
python 复制编辑 for x in table:
-
功能: 遍历
table中所有可能的字符,逐一尝试插入到当前待破解的位置now。
python复制编辑 cmd = '../../../pin -t obj-intel64/inscount0.so -o ollvm.log -- ./ollvm '+\ flag[:now]+x+flag[now+1:]+\ '; cat ./ollvm.log'
-
功能:
-
构造系统命令,调用 Pin 工具对目标程序进行插桩分析。
-
../../../pin: Pin 工具路径。 -
-t obj-intel64/inscount0.so: 使用inscount0.so插桩工具,记录程序运行的指令计数。 -
-o ollvm.log: 将指令计数的结果输出到ollvm.log。 -
-- ./ollvm <flag>: 执行目标程序ollvm,传入当前猜测的flag。
-
-
拼接当前尝试的
flag
。
-
flag[:now]: 已破解的部分。 -
x: 当前尝试的字符。 -
flag[now+1:]: 未破解部分(保持原样)。
-
-
; cat ./ollvm.log: 读取生成的日志文件。
-
python 复制编辑 output = subprocess.check_output(cmd,shell=True,stderr=subprocess.PIPE)
-
功能:
执行系统命令
cmd
,并捕获其输出。
-
shell=True: 允许在 shell 环境中执行命令。 -
stderr=subprocess.PIPE: 捕获命令的标准错误输出。
-
python 复制编辑 now_cnt = int(output.split(b'\n')[1].split()[1].decode())
-
功能:
-
解析
ollvm.log
日志中的指令计数。
-
output.split(b'\n')[1]: 获取日志中包含指令计数的第二行。 -
.split()[1]: 提取指令计数值。 -
.decode(): 将字节流解码为字符串。 -
int(): 转换为整数。
-
-
将当前的指令计数存储到
now_cnt。
-
python复制编辑 if(now_cnt-prev_cnt >= 1000000):
print(f"[+] RIGHT! {x}")
flag = flag[:now]+x+flag[now+1:]
now += 1
prev_cnt = now_cnt
break
-
功能:
判断当前尝试的字符
x
是否正确。
-
如果指令计数的增长量(
now_cnt - prev_cnt)超过 1,000,000,说明x是正确的。 -
输出当前正确字符。
-
更新
flag
:
-
flag[:now] + x + flag[now+1:]: 替换当前位置now的占位符为正确字符x。
-
-
更新
now指针,移动到下一个字符。 -
更新
prev_cnt为当前指令计数,作为下一次比较的基准。 -
使用
break跳出内层循环。
-
python复制编辑 else:
print("[+] ERROR !")
-
功能: 如果
table中所有字符尝试完毕仍未找到正确字符,则输出错误提示。
python复制编辑print(f'[+] Done!\ntime: {time.time()-st_time}')
print(f'\n[+]{flag}\n')
-
功能:
-
输出破解完成的提示。
-
计算并显示总耗时:
time.time() - st_time。 -
打印最终破解完成的
flag。
-

















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









