



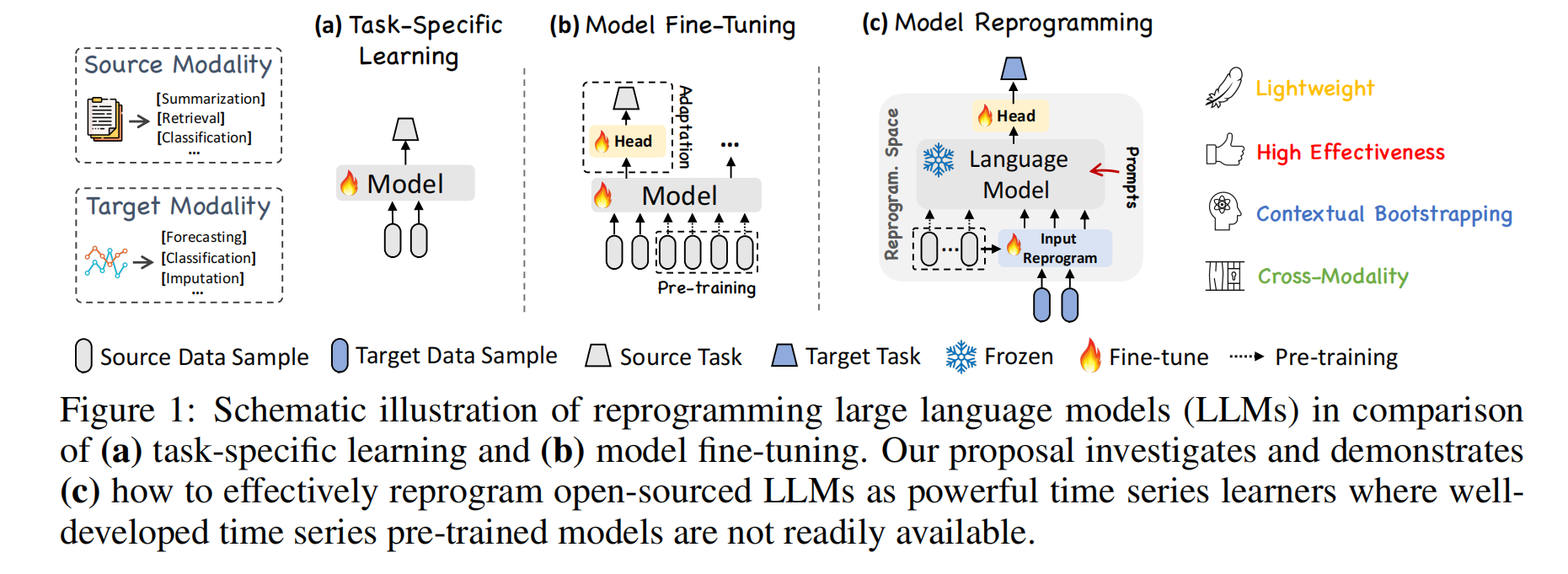
论文内容:TIME-LLM 提出了一种无需微调大语言模型主体、即可用于时间序列预测的全新框架。通过将时间序列片段重编程为一组可被 LLM 理解的“文本原型”,并结合包含数据背景、任务指令与统计特征的 Prompt-as-Prefix 提示结构,模型成功激活了 LLM 的跨模态推理能力。实验表明,TIME-LLM 在长期、短期、少样本与零样本预测任务中均显著超越现有专用时间序列模型,在效率上又极其轻量,为构建通用、跨领域的时序预测模型提供了新的范式。
一、背景:为什么需要 TIME-LLM?
时间序列预测是数据驱动决策的基石,广泛应用于能源负荷预测、交通流量、需求规划、气象与流行病建模等实际场景。尽管这些任务在工程上至关重要,现有的时间序列方法通常高度「任务专用」:为不同场景设计不同架构(例如 ARIMA、LSTM、各种 Transformer 变体),导致模型难以泛化到新领域、需要大量标注数据或昂贵的架构搜索与调参。TIME-LLM 的出发点正是为了解决这种依赖领域数据与专项设计的局限性,探索能否借助大语言模型(LLM)的通用性来做更通用、更数据高效的时间序列预测。
大语言模型在自然语言处理领域表现出色:少量样例或零样例即可完成新任务(few-/zero-shot),并展现出强大的模式识别与推理能力。这些能力在理论上非常适合用于发现并利用时间序列中的复杂模式与高阶关系,从而有望突破传统时间序列模型的局限。论文指出,如果能够“对齐”时间序列与语言模态,就有可能把预测问题“翻译”为 LLM 能理解和推理的形式,从而把 LLM 当作一个通用的时序推理引擎来使用。
然而,要把 LLM 用于时间序列也面临实质性挑战:
- 模态差异:时间序列是连续数值流,而 LLM 处理离散的词/标记(tokens)。如何把连续值表示为对模型有意义的离散信息是一大难点。
- 数值精度与表示问题:直接把数值“写成”自然语言(即把每个数变成字符串)会遇到高精度数值处理不敏感、不同模型生成数值 token 格式不一致、需要复杂后处理等问题。
- 资源与效率考量:直接微调用大模型代价高昂,若能在不改动主干模型的前提下复用其能力,将极大提高实用性与可部署性。
基于上述动机与挑战,TIME-LLM 提出了一种“reprogramming(重编程)+ prompt-as-prefix(提示作前缀)”的思路:在不微调 LLM 主体的前提下,把时间序列通过一套轻量的输入变换(把时间片段映射到若干“文本原型”)和结构化提示转成 LLM 更容易处理的形式,以激活模型的迁移学习与推理能力,从而实现通用、数据高效且可跨域的时序预测。
二、论文创新点
TIME-LLM 的核心创新在于:不修改、不微调 LLM 主干模型,却能让其成为一个强大的时间序列预测模型。论文提出了多项关键技术,使得 LLM 能够在连续数值领域展现少样本、零样本和跨域泛化能力。
1. 将时间序列 Forecasting 视为“语言任务”的跨模态重编程(Reprogramming)
传统做法需要为时间序列设计专用架构(如 Transformer、RNN、MLP 等),难以复用大模型的知识。TIME-LLM 首次提出:
通过重编程,把时间序列片段映射到 LLM 的词向量空间,使 LLM 能直接处理时间序列。
它不改变 LLM 内部结构,是一种“让时间序列适应 LLM”的新范式,非常高效且低成本。
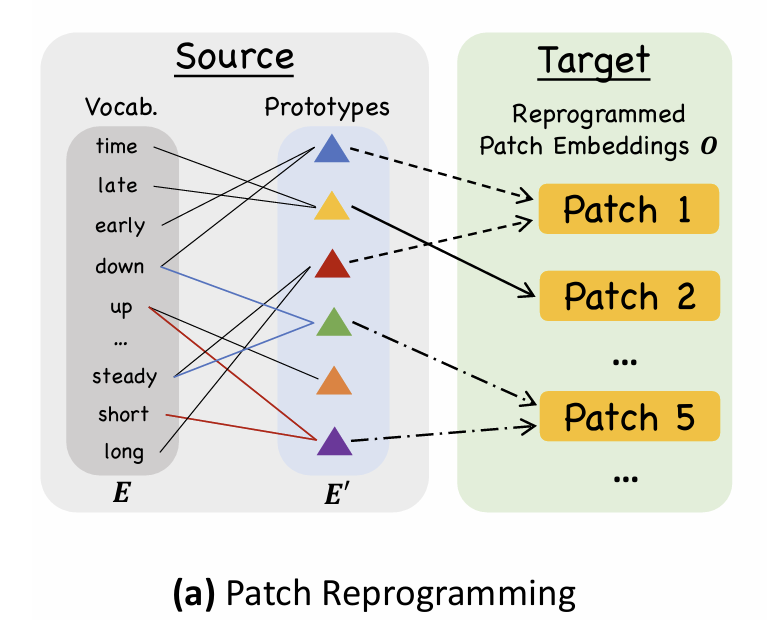
2. Patch Reprogramming:用“文本原型(Text Prototypes)”表示时间序列片段
连续数值序列无法直接输入 LLM。论文创新地提出:
-
将时间序列切分为 patch(类似 vision patch)
-
引入少量可学习的 text prototypes(来自 LLM 词向量空间)
-
通过 cross-attention,将 patch 重编程为这些原型的组合
这样,LLM 看到的不是生硬数字,而是与其训练语境相近的“伪文本语义”,从而能利用语言知识推理时间结构。
3. Prompt-as-Prefix(PaP):通过结构化提示增强 LLM 的时序推理能力
不同于 simply prompting(把数字写成自然语言),TIME-LLM 采用:
把提示作为前缀 embedding 与 patch 一起输入,让 LLM 在语义上“理解”数据背景与任务。
提示中包括:
-
数据集背景(如 ETT 数据的物理含义)
-
任务说明(如“预测未来 H 步”)
-
输入统计信息(趋势、最大值、最小值、重要滞后项)
这一结构极大提升了模型的跨域预测和少样本推理能力。

三、模型整体流程介绍
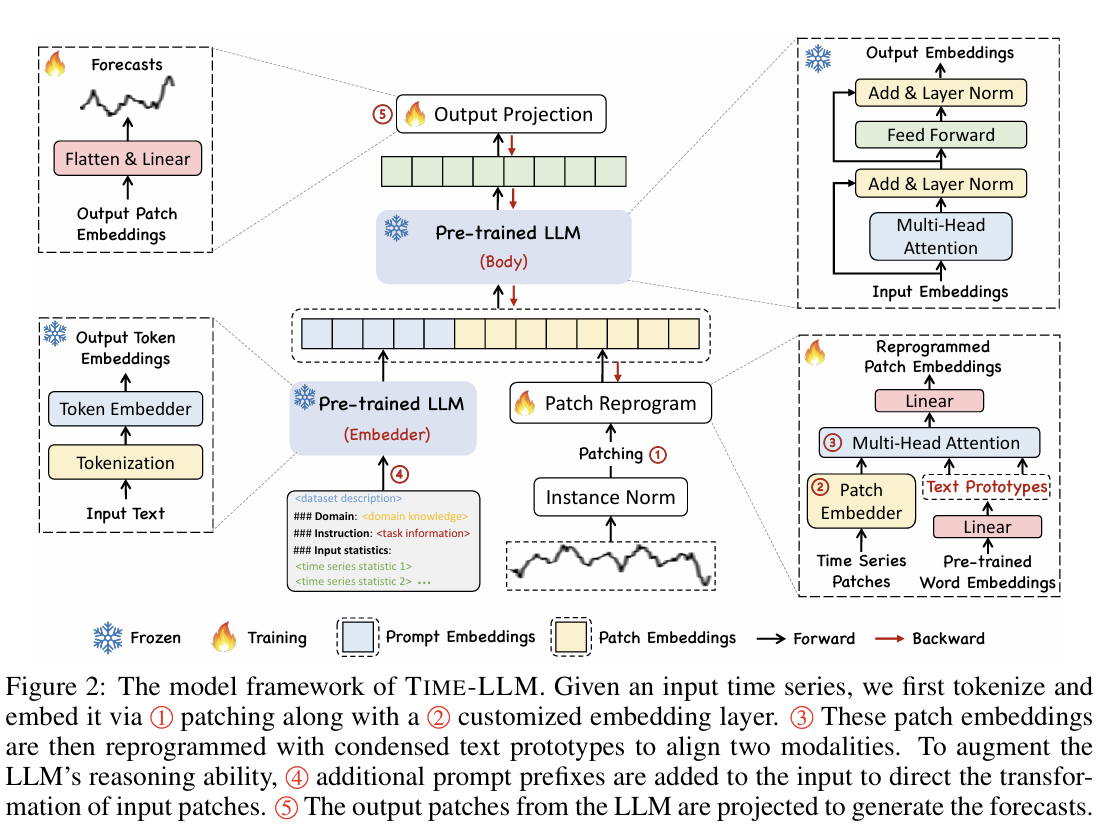
TIME-LLM 的整体架构如上图所示,整个流程可以分为四个阶段:输入预处理 → Patch Reprogramming → Prompt-as-Prefix → 冻结 LLM + 输出投影。核心思想是:“用轻量模块把时间序列转换成 LLM 能理解的形式,再让冻结的 LLM 去做推理”。
1. 输入时间序列预处理(Linear Norm + Patch 切分)
首先对原始时间序列![]() 做线做线性归一化,使不同尺度的数值变得可比较。然后将序列按窗口切分成多个连续 patch,每个 patch 含有固定长度的时间片段。
做线做线性归一化,使不同尺度的数值变得可比较。然后将序列按窗口切分成多个连续 patch,每个 patch 含有固定长度的时间片段。
这样处理的目的是将连续的时间序列分成多个局部子结构,与图像划分 patch 的思想类似,让模型更容易捕捉局部趋势与模式。
2. Patch Reprogramming:将数值 patch 对齐到 LLM 的词向量空间
这是 TIME-LLM 最核心的部分。每个数值 patch 不直接送入 LLM,而是经过三步转换:
-
Patch Embedding
将 patch 映射为向量表示。 -
Text Prototypes(可学习的文本原型)
网络中维护一组可学习的 prototype(来自 LLM 词向量空间)。
这些原型可理解为“伪文本语义单元”。 -
Cross-Attention 重编程
patch embedding 作 query,text prototypes 作 key/value,
通过 cross-attention,patch 被表示为这些原型的加权组合。
最终输出的是包含“文本语义”的时序 embedding,使 LLM 能够“读懂”时间序列。
3. Prompt-as-Prefix(PaP):为 LLM 提供结构化语义先验
在输入 patch 之前,TIME-LLM 还会插入一个专门设计的 语义前缀(prefix),由 Prompt Encoder 生成。
Prompt 内容包括:
-
数据集背景(dataset context)
-
任务描述(task instruction)
-
输入序列统计信息(最大值、最小值、趋势、滞后特征等)
这些前缀以“embedding”的形式接入 LLM 的输入序列,不通过自然语言 token,使提示更稳定、可控。作用是让 LLM 明确:“现在要做的是时间序列预测任务,需要理解局部趋势、周期模式等结构。”
4. 冻结 LLM 主体进行推理(Forward Pass Only)
经过重编程后的 patch embedding 和 prefix 一起送入 LLaMA(或其他 LLM)中。LLM 主体保持完全冻结,不更新任何权重。LLM 负责根据上下文关系与提示内容进行“跨模态推理”。它不“懂数字”,但能“懂语义化的模式”。
这种做法带来的好处包括:
-
训练成本极低
-
几乎不需要额外显存
-
迁移性强,适合跨领域预测
5. Output Projection:把 LLM 输出重新映射为预测值
LLM 输出的是语言向量,需要经过一个 projection head 将其映射回数值:![]() ,
,
这里仅更新这一小部分参数,因此训练非常轻量,最终得到的结果就是未来 H 步的预测值。
四、实验
TIME-LLM 的实验部分系统地验证了模型在 长期预测、短期预测、少样本(few-shot)、零样本(zero-shot)、跨域泛化以及效率 等多个维度的性能。总体而言,TIME-LLM 在绝大多数任务上都显著超越传统时间序列模型与现有基于大模型的方法(如 GPT4TS),并凭借极少的可训练参数展现出优异的效率表现。
1. 实验设置:数据集与任务场景
论文涵盖多个主流时间序列基准数据集,包括:
-
ETT 系列(ETTh1/ETTh2/ETTm1/ETTm2):电力变压器温度
-
Electricity、Traffic、Weather:多变量长序列预测常用数据集
-
Exchange-Rate、ILI:金融与流行病领域
时间序列规模与特性各不相同,有的强趋势、有的强季节性,体现预测场景多样性。
评价任务包括:
-
Multivariate Long-Term Forecasting(多变量长期预测)
-
Few-Shot Learning(5%/10% 训练数据)
-
Zero-Shot Forecasting(跨数据集预测)
-
Cross-domain Generalization(跨领域泛化)
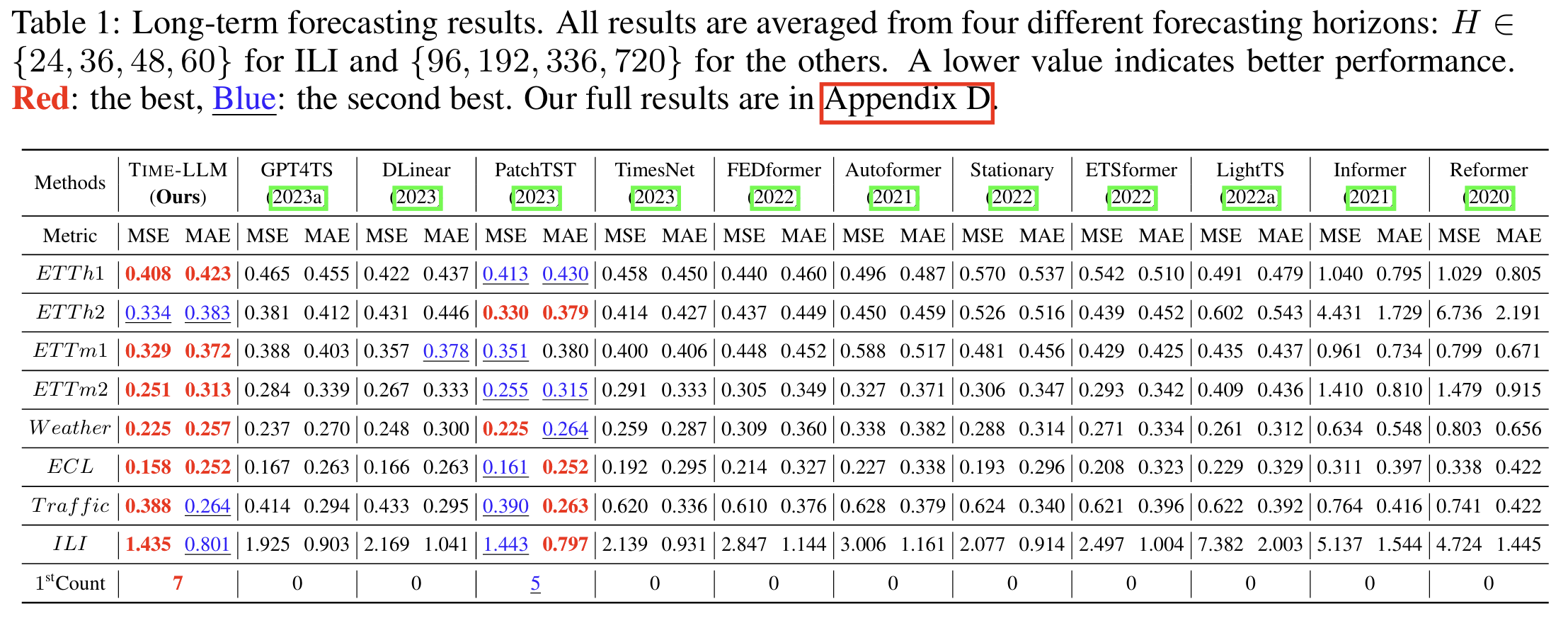
2. 长期预测:全面领先现有 SOTA 模型
在所有四个 ETT 数据集以及 Electricity、Weather、Traffic 等数据集上,TIME-LLM 在 96 / 192 / 336 / 720 步预测中都获得了最优或近似最优结果。
与强竞争对手相比:
-
比 PatchTST 更稳定、平均误差更低
-
比 TimesNet、FEDformer、DLinear 等 Transformer 系列提高显著
-
在复杂多变量场景(如 Electricity、Weather)优势更大
实验表明,TIME-LLM 在不微调 LLM 的前提下,仍能捕捉序列的长期结构与模式。
3. 短期预测:在局部模式学习上与专用模型竞争
在短期预测(如 24、36 步)中,TIME-LLM 仍能保持与专门为短序列设计的模型相近或更优的性能。这表明其重编程结构可以适应不同长度范围的时序结构。
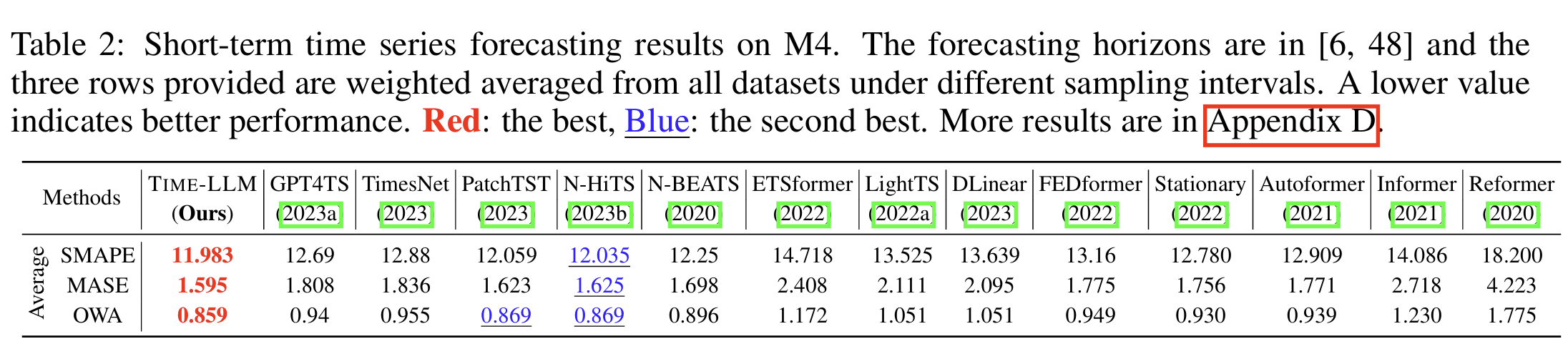
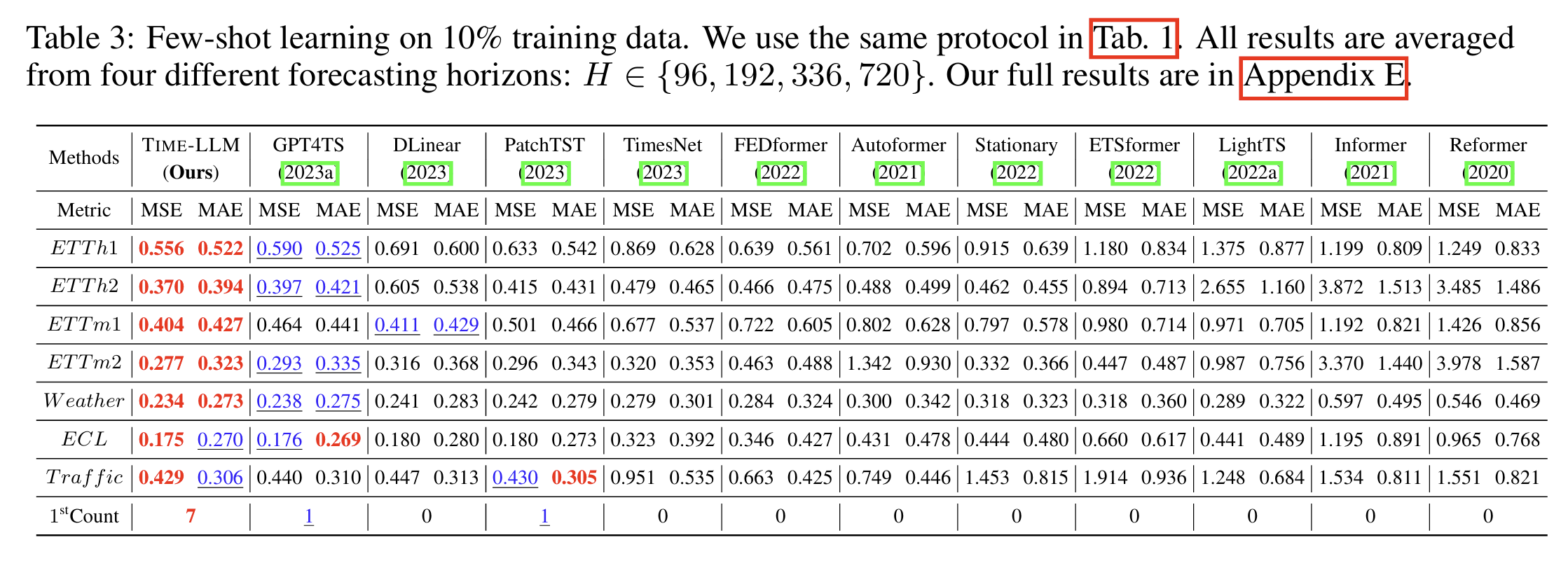
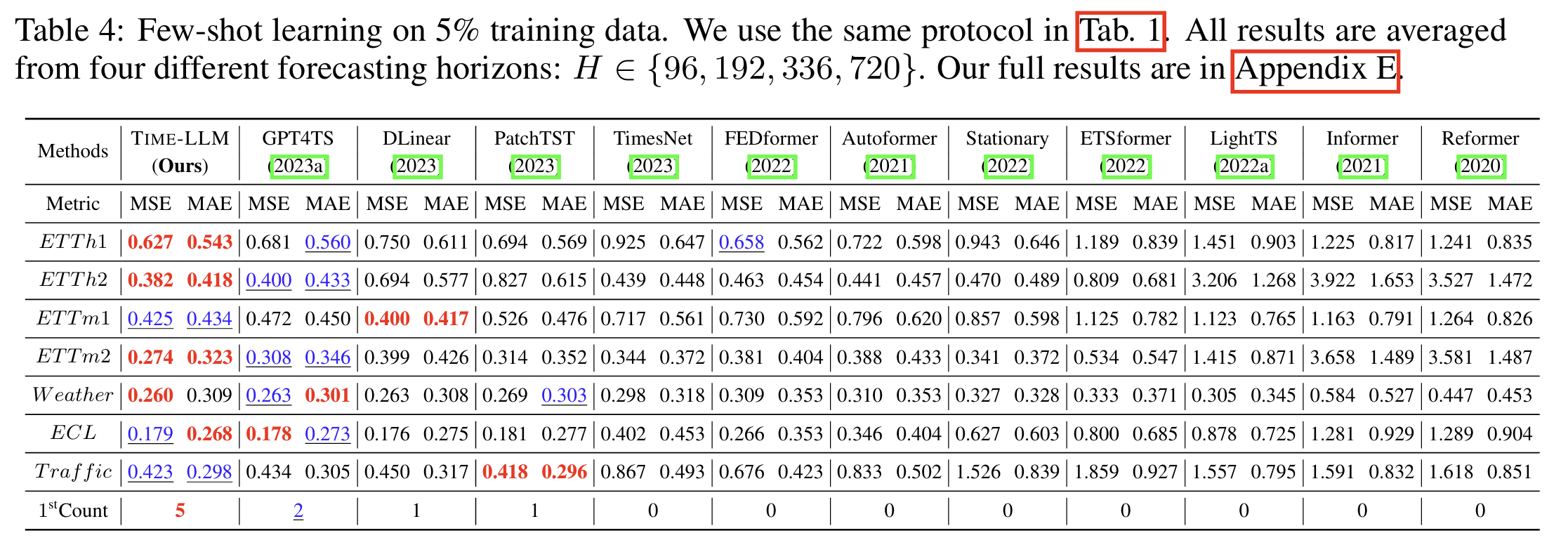
4. Few-Shot 学习(5%/10% 数据):显著优于 GPT4TS 与传统模型
少样本预测是 TIME-LLM 的强项之一。实验发现:
-
仅使用 5% 的训练数据,TIME-LLM 仍明显优于 GPT4TS、PatchTST、TimesNet
-
在 10% 数据场景中性能几乎与全数据训练持平甚至更好
-
说明 LLM 的“语义先验”确实被激活,并能用极少数据完成适配
这类实验验证了 TIME-LLM 的 数据效率(data efficiency) 优势。
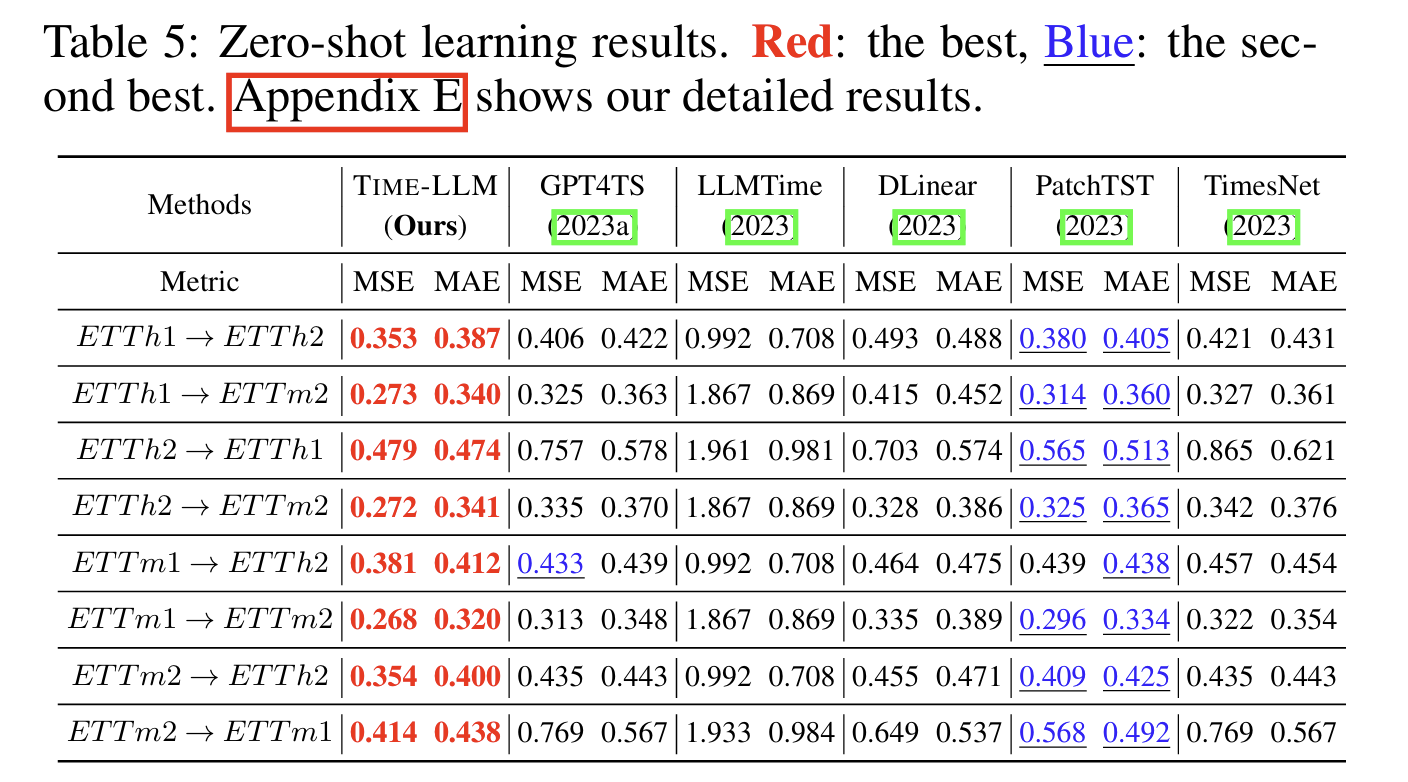
5. Zero-Shot(跨数据集)预测:TIME-LLM 的能力跃迁点
TIME-LLM 在 训练于 A 数据集 → 直接预测 B 数据集 的场景中:
-
零样本性能比第二名(通常是 GPT4TS)平均提升 14%–20%
-
在跨领域任务(如 Weather → ETT)中仍保持稳定预测能力
-
PatchASprefixprefixprefix、StatPrompt 等 prompting 方法明显不如 TIME-LLM
这表明:
通过重编程,LLM 的跨模态知识被成功迁移到时间序列任务中。
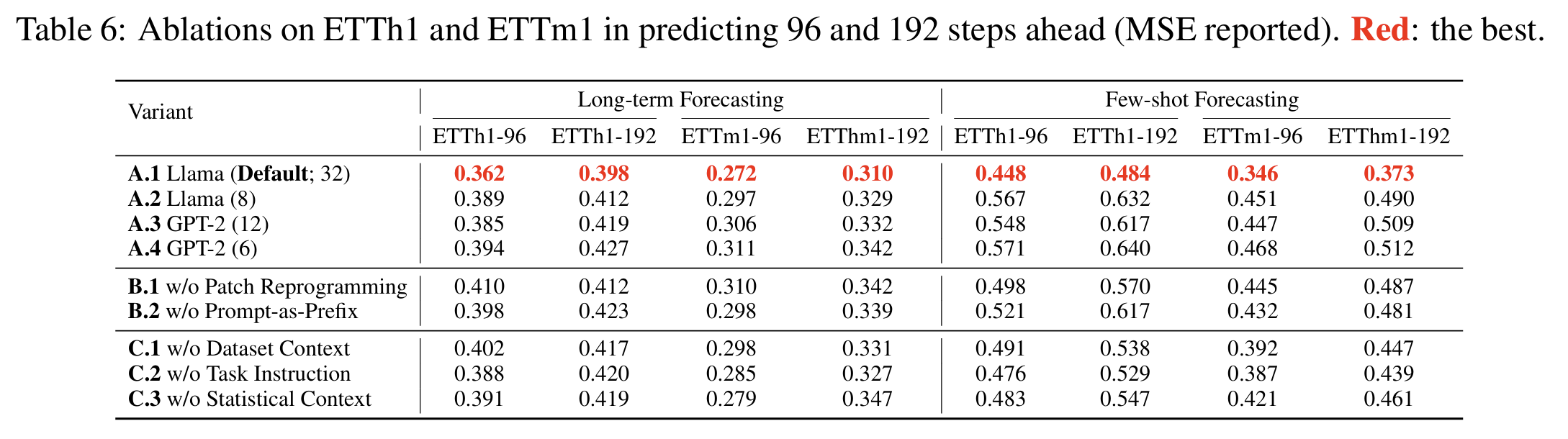
6. 消融实验:每个模块都带来明显提升
论文通过消融验证如下:
-
去掉 Patch Reprogramming → 性能显著下降
因为 LLM 无法理解未对齐的连续值表示。 -
去掉 Prompt-as-Prefix → zero-shot 性能明显变差
表明语义提示对跨域适应至关重要。 -
去掉 normalization → 长期预测精度下降
这些实验说明了每个模块都在 TIME-LLM 中发挥关键作用。
7. 模型效率:训练参数仅占 LLM 的 0.2%
TIME-LLM 仅训练:
-
Patch embedding(极小规模)
-
Reprogramming cross-attention(小规模参数)
-
Output projection(线性层)
-
Prompt encoder(轻量)
总参数量约为 6M,对比:
-
GPT4TS:需要微调 LLM 的部分层,成本高数十倍
-
其他 LLM 方法:需要更大训练资源或更复杂预处理
其显存占用与训练速度在表中显著优于微调类方法。

五、可解释性: text prototypes 的可视化
尽管 TIME-LLM 使用了大语言模型作为核心推理单元,但其重编程结构(Patch Reprogramming)让输入的时间序列与 LLM 词向量空间产生了明确的对应关系。因此,模型具备了良好的可解释性,尤其体现在 text prototypes(文本原型) 的使用模式上。
论文通过可视化这些原型的激活情况,揭示了两个关键发现:
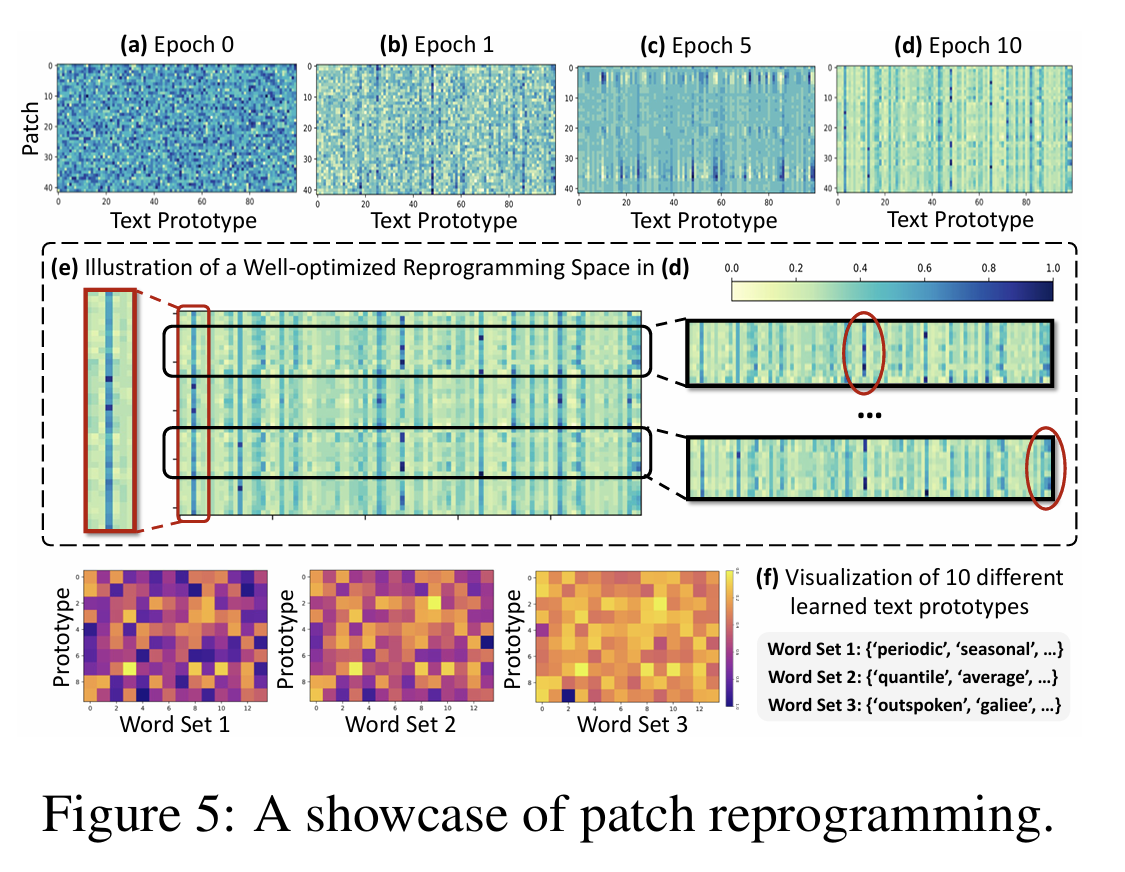
1. 大多数原型保持“未激活”,只有少数成为关键语义单元
模型中包含多组 text prototypes,它们本质上是可学习的向量,来自 LLM 的词向量空间。但实验发现:
-
大部分 prototypes 在预测任务中很少被使用
-
只有 极少数 prototypes 高频参与 patch 的重编程
这说明模型会自动选择最有用的“语义基元”,而不是平均分配注意力。这种稀疏激活(sparse activation)非常符合 LLM 在 NLP 中的工作方式。
2. 被激活的 prototypes 对应“可解释的时间序列语义”
论文进一步分析发现,最常被激活的几个 prototypes 与一些时间序列特征高度相关,例如:
-
periodic(周期性)
-
seasonal(季节性波动)
-
average / trend(平均值或趋势变化)
-
local variation(局部波动)
也就是说,模型实际上学会了:
用语言语义来表达时间序列的结构模式。
这是 TIME-LLM 最大的跨模态亮点之一——时间序列经过重编程后,在 LLM 中被当作“语言意义上的结构”来处理,这使得模型能够利用其庞大的语义知识库进行推理。
3. Patch 与 Prototypes 的匹配模式具有一致性和可解释性
可视化结果显示:
-
相似的时间片段(patch)倾向激活相同或相似的 prototypes
→ 表明模型真正学到了局部结构之间的相似性。 -
在预测具有特定周期或趋势的数据集(如 ETT)时,某些 prototypes 激活频率明显增加
→ 说明模型能够适应数据的宏观结构。
这种“一致的激活规律”使得 TIME-LLM 的预测不仅是黑盒输出,而是具备可追踪、可解释的内部机制。
六、总结与展望
TIME-LLM 提出了一种全新的时间序列预测范式:通过跨模态重编程,让冻结的大语言模型在不进行微调的前提下,也能高效完成数值预测任务。 不同于以往需要大量数据和复杂模型设计的传统方法,TIME-LLM 充分利用了 LLM 强大的泛化能力、语义推理能力与参数规模优势,并通过轻量的 patch reprogramming 与 Prompt-as-Prefix 高效桥接了数值模态与语言模态。
从实验结果看,TIME-LLM 在长期预测、少样本学习、零样本预测、跨域泛化与效率等方面均展现出显著优势,甚至超越大量精心设计的时间序列 SOTA 模型与基于大模型的 GPT4TS。在真实场景中,这意味着未来的预测系统可以借助 LLM 的通用语义知识,以极高的数据效率和良好的迁移性完成复杂任务。
然而,TIME-LLM 也为未来研究打开了新的问题与空间:
1. 更强的跨模态重编程
当前的 text prototypes 机制有效但仍然依赖 LLM 词向量空间,未来可以探索:
-
更精细的时间—语言对齐方式
-
自适应生成原型,而非固定原型集合
-
针对不同类型时间序列(如稀疏、异常、异构)的特定 reprogramming 方法
2. 利用 LLM 知识进一步增强时间序列理解
Prompt-as-Prefix 已证明有效,但仍可发展:
-
注入领域知识(如交通、气象、能源的物理规律)
-
结构化的长期先验(如周期性模型)
-
多层级多模态提示结构(语言 + 图表 + 数值统计)
3. 超越预测任务,扩展到更多时序应用
当前 TIME-LLM 主要用于 forecasting,未来可以扩展到:
-
异常检测(anomaly detection)
-
时序分类(sequence classification)
-
时序填补(imputation)
-
因果推断、事件预测等更复杂任务

















 4397
4397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









