




一、前言
在高并发推荐引擎场景中,C++的极致性能往往以开发效率为妥协,尤其在业务频繁迭代时,C++的开发效率流程成为显著瓶颈。传统嵌入式脚本(如Lua)虽支持动态加载,但其与C++的交互成本(如虚拟栈数据中转、类型转换)仍会带来额外性能损耗。
为此,我们探索设计DScript2.0——一种与C++内存布局及调用约定深度兼容的动态脚本语言,通过自研编译器实现即时编译与无缝嵌入,尝试在保留脚本灵活性的同时,尽可能贴近C++的原生性能,为性能与效率的平衡提供了轻量化解决方案。
二、动态脚本在引擎中的引用
C++引擎的迭代效率瓶颈
在搜推引擎中的实践中,出于对高并发场景下极致性能的追求,使用C++进行引擎自研成为了一种业界常态。
众所周知,C++通过开放底层控制权限(如内存分配,指令优化等),提升了可达的性能上限,但这种提升伴随了大量底层细节的处理,消耗了更多的开发时间,追求性能优先的同时,却又限制了开发效率。
我们希望能够在保持性能的同时,提升引擎的开发效率。
利用嵌入式脚本提升迭代效率
我们的目标是寻求一种平衡性能与迭代效率的方案,一种主流方案是在C++中嵌入脚本语言。例如,在游戏引擎和Nginx开发中集成Lua,在C/C++代码中实现性能需求,结合脚本代码中实现控制逻辑,从而提升开发效率。
嵌入式脚本对迭代效率的提升
-
支持动态加载,无需编译部署。
-
无需C/C++经验,脚本学习成本低,提升参与迭代的人力总量。
引擎的迭代拆解
-
引擎内部的技术性迭代
-
业务侧的需求支持
业务侧的需求非常适合引入嵌入式脚本,实现对易变需求的自迭代,提升开发效率,这也是一种业界主流方案。例如,一些搜索中台中,对于相关性和粗排逻辑封装为插件,业务侧的算法工程师使用Lua开发计算逻辑,可以极大地提升迭代效率。
嵌入式脚本的额外性能开销
在引擎中嵌入脚本,虽然可以提升迭代效率,但并非全无代价,高阶语言与低阶语言的交互存在着额外的性能开销。
例如,Lua和C++的交互机制基于Lua提供的虚拟栈来实现,这个栈是两者进行数据交换的核心通道。
使用虚拟栈实现语言交互存在额外的开销,包括但不限于压栈和弹栈操作、栈空间管理、类型检查和转换、复杂数据结构的处理等。

更加极致的方案
基于以上的瓶颈,我们期望一种更加极致的方案,实现性能与效率的平衡。
嵌入式脚本的额外性能开销
(主要源于两种语言在ABI层面的不一致)
-
函数调用约定不一致,需要一个虚拟栈进行中转。
-
数据类型内存布局不一致,需要额外的检查和转换。
一个直观的解决方案就是我们设计一种编程语言,在底层实现上与C++具有一致内存布局与调用约定,从而消除额外的转换开销。
同时,这种编程语言可以在C++嵌入,也支持即时编译,提升效率的同时,也拥有与原生C++近似的执行性能。
以上是我们规划DScript2.0项目初衷。
三、DScript2.0的编译器实现
语法设计
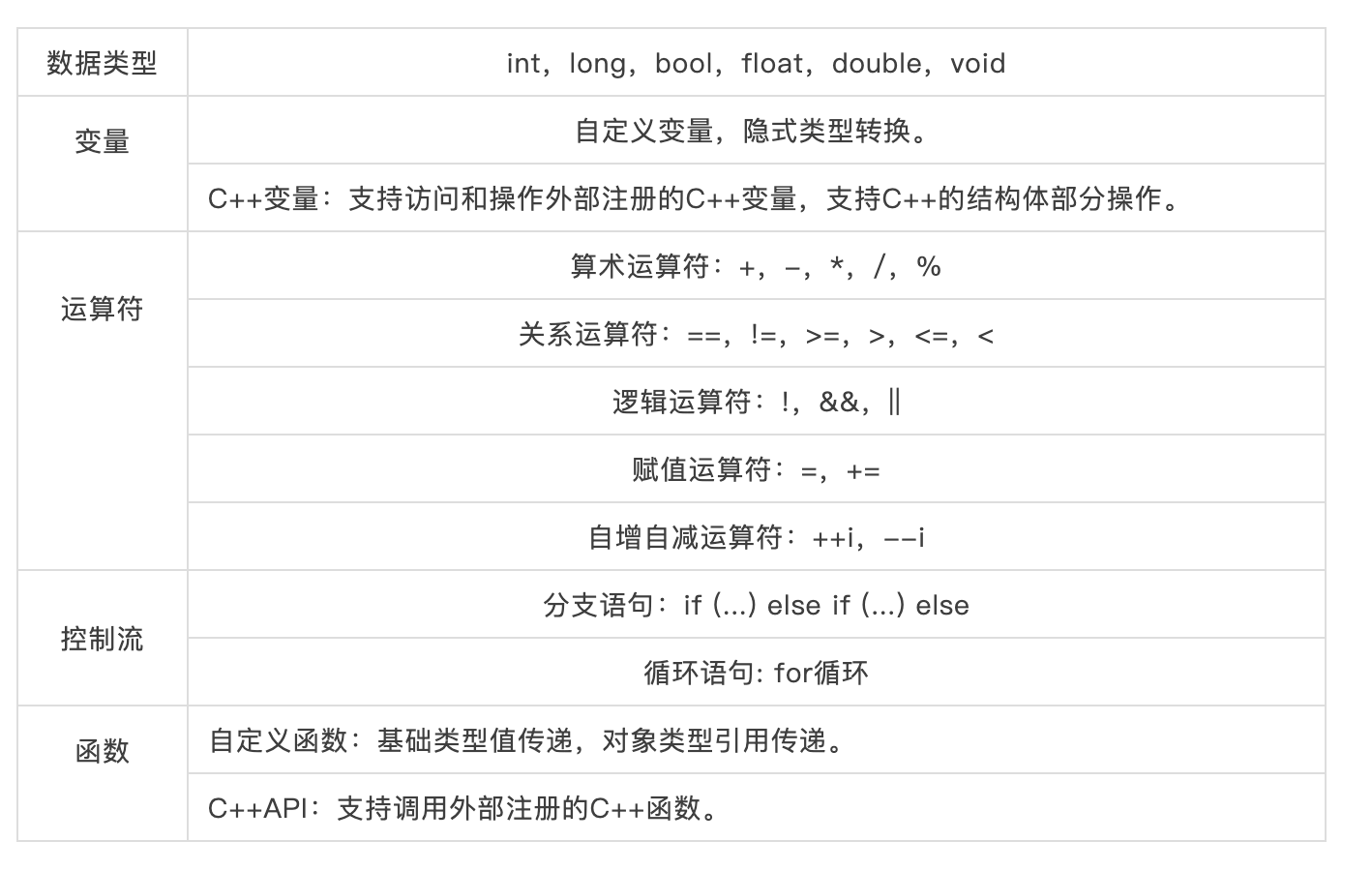
DScript2.0被设计为一种轻量级面向过程的编程语言,同时它也是静态类型的编译语言。
在语法支持上,包含了基础数据类型、变量、运算符、控制流和函数,额外支持了与C++的语言互操作。
浅析编译器架构

(编译器的三段结构)
一个完整的编译器通常由三个主要部分组成:前端、优化器和后端。
-
前端:负责词法分析、语法分析、语义分析、生成中间代码。
-
优化器(中端):负责对中间代码进行优化。
-
后端:负责将中间代码转换成目标机器的的机器码。
基于LLVM实现DScript2.0编译器
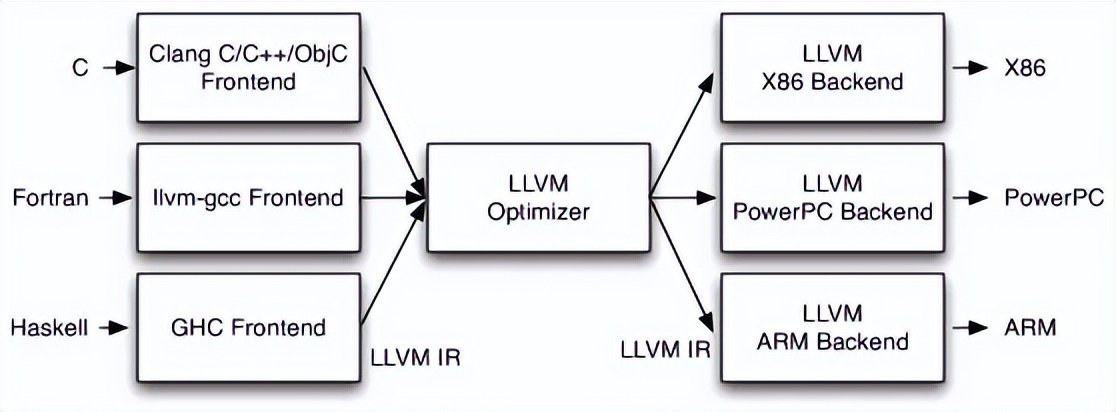
LLVM 是一个模块化且高度可重用的编译器基础设施项目。它提供了前端、优化器和后端工具链,已支持多种编程语言和平台。LLVM具有跨平台性,允许开发者灵活定制编译流程,提供高级优化能力,支持即时编译,被广泛用于编译器开发、虚拟机和代码分析工具场景。
※ 采用LLVM实现DScript2.0的优势
-
提升开发效率:LLVM的前端、中端和后端采用了模块化设计,每个部分都可以独立替换或扩展,这种灵活性使得 LLVM 非常适合定制编译器,我们可以复用LLVM的中端与后端,专注于前端开发,减少开发成本。
-
支持高级优化:LLVM 提供了一套强大的优化工具,能够对代码进行静态和动态优化。这些优化不仅能够提高代码的执行效率,还可以减少代码体积。这是DScript2.0理论上可能提供接近原生C++性能的关
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









