 得物DSearch3.0搜索核心引擎升级之路
得物DSearch3.0搜索核心引擎升级之路





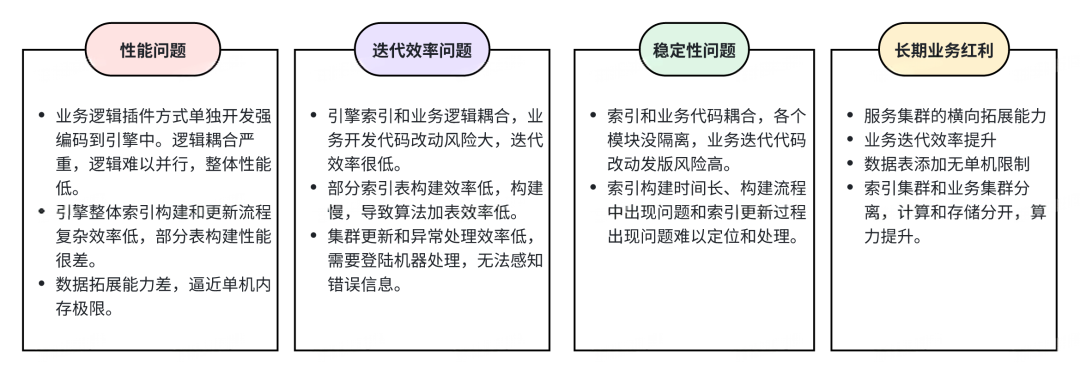
一、背景
随着交易和社区搜索业务稳步快跑,基建侧引擎越来越复杂,之前搜索底层索引查询结构已经存在较为严重的性能瓶颈。成本和运维难度越来越高。在开发效率上和引擎的稳定性上,也暴露出了很多需要解决的运维稳定性和开发效率短板。而在引擎的业务层部分也需要逐步升级,来解决当前引擎中召回层和业务层中各个模块强耦合,难维护,迭代效率低下等问题。
二、引擎开发技术方案
DSearch1.0索引层整体结构
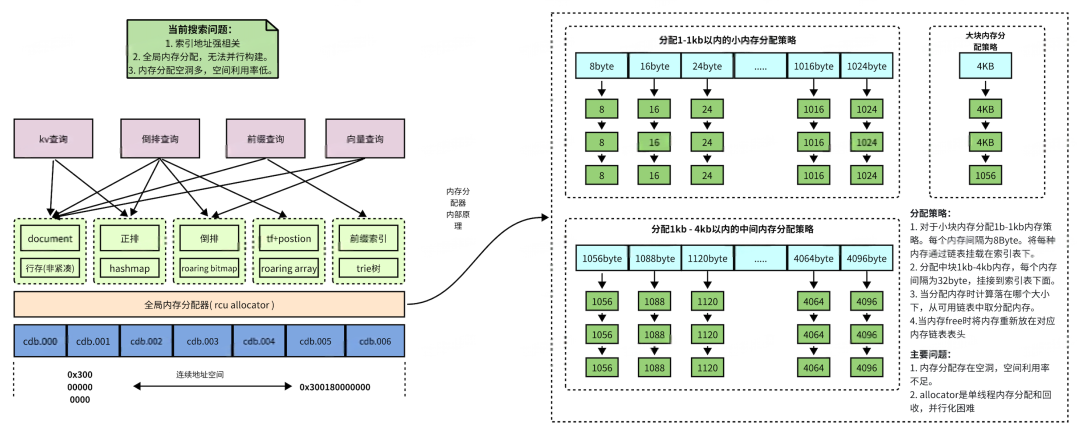
DSearch1.0的索引结构比较特殊一些,总体上使用了全局rcu的设计思想,整体架构上单写多读,所以实现了并发高性能无锁读,内部数据结构都是无锁数据结构,所以查询性能高。在写操作上因为rcu机制实现写入无锁。整体上优点读性能高,没有传统段合并操作带来的磁盘抖动。缺点是索引地址和操作系统强相关,运维复杂,热更新受限。全局地址分配难以并行写入,构建瓶颈明显。无法对浪费的内存进行回收导致内存空间利用率低,索引空间占用大。总体结构如图所示:
DSearch2.0的索引升级
DSearch2.0分段索引整体设计
引擎2.0索引升级采用经典段合并架构,除了继承了段合并中优异的高性能写入性能和查询已经索引合并等优势外,针对段合并中频繁的正排字段更新等带来的高IO缺点。我们设计了新的正排字段原地更新索引,使新的DSearch2.0引擎拥有Redis的高性能写入和查询,也拥有lucene的紧凑索引和索引合并带来的内存空间节省的优势。
※ 索引段结构
-
每个索引段包含了文档文件,用于紧凑存放document中的各个字段的详细信息。字符串池文件是对document中所有的字符串进行统一顺序存储,同时对字符串进行ID化,每个字符串ID就是对应于字符串池中的offset偏移。
-
可变数组文件是专门存放数组类型的数据,紧凑型连续存放,当字段更新的时候采用文件追加append进行写。最终内存回收通过段之间的compaction进行。FST索引文件是专门存放document中全部字符串索引。每个fst的node节点存放了该字符串在字符串池中的偏移offset。而通过字符串的offset,能够快速在倒排termoffset数组上二分查找定位到term的倒排链。
-
倒排文件是专门存放倒排docid,词频信息、位置信息等倒排信息,其中docid倒排链数据结构会根据生成段的时候计算docid和总doc数的密度来做具体判断,如果密度高于一定阈值就会使用bitmap数据结构,如果小于一定阈值会使用array的数据结构。
-
标记删除delete链主要是用于记录段中被删除的document,删除操作是软删除,在最后查询逻辑操作的时候进行最后的过滤。
-
实时增量的trie树结构,实时增量段中的前缀检索和静态段中的前缀检索数据结构不一样,trie因为能够进行实时更新所以在内存中使用trie树。
-
段中的metadata文件,metadata文件是记录每个段中的核心数据的地方,主要记录段内doc数量,段内delete文档比例,实时段的m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 574
574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









