



文章目录
各位同学大家好,本次给大家分享的项目为:
基于深度学习CNN算法的动物识别系统01–带数据集-pyqt5UI界面-全套源码
项目文件获取地址:
百度网盘链接: https://pan.baidu.com/s/14eIJg4X_ESQz_fQ6nHVsgQ?pwd=zugy
提取码: zugy
一、项目摘要
本项目旨在设计并实现一个基于深度学习的动物识别系统。该系统利用卷积神经网络模型,对图像中的动物种类进行自动识别和分类。通过对不同深度学习模型的比较和优化,本研究最终选择了轻量级的MobileNet模型,旨在平衡识别准确率和计算资源消耗,提供一个高效且易于部署的解决方案。
本研究验证了MobileNet模型在动物识别任务中的可行性。MobileNet作为一种轻量级的卷积神经网络,尽管参数量和计算复杂度大幅降低,但在本研究的数据集上依然实现了91.4%的验证集准确率,展示了其在资源受限环境下的优异表现。这一结果表明,MobileNet能够在保持较高识别精度的同时,提供一个高效、低资源消耗的解决方案,适合在移动设备或嵌入式系统中部署。
二、项目运行效果
运行效果视频:
https://www.bilibili.com/video/BV12f4tenE2C
运行效果截图:





三、项目文件介绍


四、项目环境配置
1、项目环境库
python=3.8 pytorch pyqt5 opencv matplotlib 等
2、环境配置视频教程
1)anaconda下载安装教程
2)pycharm下载安装教程
3)项目环境库安装步骤教程
五、项目系统架构
动物识别系统的整体架构分为四个主要模块:
1. 数据输入模块:负责接收用户输入的动物图像。
2. 图像预处理模块:对输入的图像进行标准化处理,包括调整图像大小、归一化等,以确保与训练模型的输入要求一致。
3. 深度学习模型模块:通过预训练的MobileNet模型对预处理后的图像进行识别和分类,输出花卉的种类标签。
4. 用户交互模块:通过PyQt5构建图形用户界面,使用户能够便捷地上传图像,查看识别结果,并获得相应的动物信息。
系统的整体工作流程如下:首先,用户通过用户界面选择要识别的动物图片,随后系统对图像进行预处理,接着将处理后的图像输入到深度学习模型中进行分类,最后在用户界面上显示识别结果及动物相关的简介。
六、项目构建流程
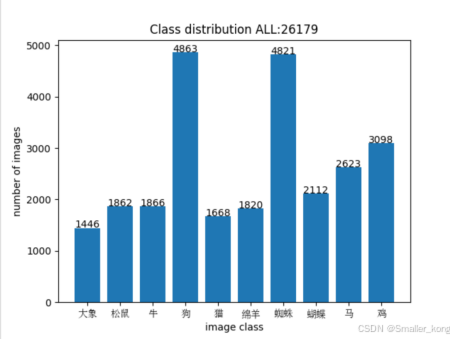
1、数据集
数据集文件夹:all_data

概述:
本文使用的数据集10类动物图像构成,共计26179张图像。
数据集格式及命令统一代码:to_rgb.py
(对数据集中的图像统一成rgb格式并进行统一规范命名)
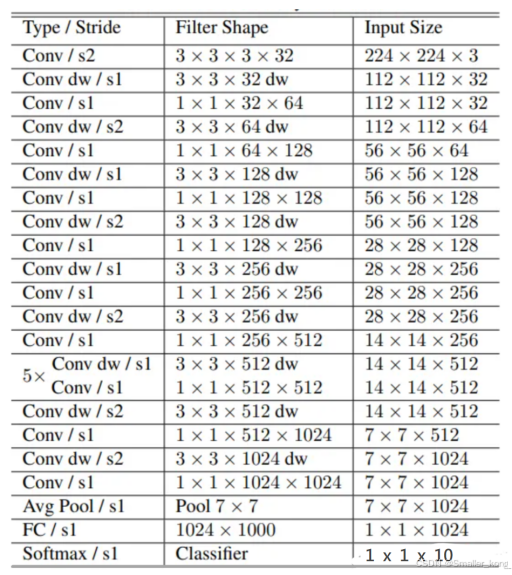
2、算法网络Mobilenet
概述:
Mobilenet是专为移动设备和嵌入式系统设计的轻量化卷积神经网络。其主要特点在于采用了深度可分离卷积(Depthwise Separable Convolution)来减少计算量和参数数量,从而在资源受限的环境下实现高效的图像分类和识别。
算法代码为:models文件夹下的mobilenet.py
"""mobilenet in pytorch
[1] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
https://arxiv.org/abs/1704.04861
"""
import torch
import torch.nn as nn
class DepthSeperabelConv2d(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, **kwargs):
super().__init__()
self.depthwise = nn.Sequential(
nn.Conv2d(
input_channels,
input_channels,
kernel_size,
groups=input_channels,
**kwargs),
nn.BatchNorm2d(input_channels),
nn.ReLU(inplace=True)
)
self.pointwise = nn.Sequential(
nn.Conv2d(input_channels, output_channels, 1),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size, **kwargs):
super().__init__()
self.conv = nn.Conv2d(
input_channels, output_channels, kernel_size, **kwargs)
self.bn = nn.BatchNorm2d(output_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class MobileNet(nn.Module):
"""
Args:
width multipler: The role of the width multiplier α is to thin
a network uniformly at each layer. For a given
layer and width multiplier α, the number of
input channels M becomes αM and the number of
output channels N becomes αN.
"""
def __init__(self, width_multiplier=1, class_num=100):
super().__init__()
alpha = width_multiplier
self.stem = nn.Sequential(
BasicConv2d(3, int(32 * alpha), 3, padding=1, bias=False),
DepthSeperabelConv2d(
int(32 * alpha),
int(64 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv1 = nn.Sequential(
DepthSeperabelConv2d(
int(64 * alpha),
int(128 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(128 * alpha),
int(128 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv2 = nn.Sequential(
DepthSeperabelConv2d(
int(128 * alpha),
int(256 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(256 * alpha),
int(256 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv3 = nn.Sequential(
DepthSeperabelConv2d(
int(256 * alpha),
int(512 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(512 * alpha),
int(512 * alpha),
3,
padding=1,
bias=False
)
)
#downsample
self.conv4 = nn.Sequential(
DepthSeperabelConv2d(
int(512 * alpha),
int(1024 * alpha),
3,
stride=2,
padding=1,
bias=False
),
DepthSeperabelConv2d(
int(1024 * alpha),
int(1024 * alpha),
3,
padding=1,
bias=False
)
)
self.fc = nn.Linear(int(1024 * alpha), class_num)
self.avg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
x = self.stem(x)
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def mobilenet(alpha=1, class_num=10):
return MobileNet(alpha, class_num)
3、网络模型训练
训练代码为:train.py
-
图像尺寸:输入图像大小设置为224×224,以适应MobileNet网络的输入层要求。
-
批量大小(Batch-size):设置为16,既可以保证模型能够充分学习数据特征,又能在有限的计算资源下保持较高的训练效率。
-
学习率(Learning Rate):初始学习率设为0.0001,并使用AdamW优化器,该优化器在保持学习率稳定的同时,能够通过权重衰减减少模型过拟合的风险。
-
损失函数:采用交叉熵损失函数(CrossEntropyLoss),适合多类别分类任务。
-
Epoch设置:训练总共进行50个Epoch,以确保模型能够充分学习到数据特征,并利用早停策略保存最优模型。
import os
import argparse
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from models.mobilenet import mobilenet as create_model
from utils import read_split_data, train_one_epoch, evaluate
def draw(train, val, ca):
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.cla() # 清空之前绘图数据
plt.title('精确度曲线图' if ca == "acc" else '损失值曲线图')
plt.plot(train, label='train_{}'.format(ca))
plt.plot(val, label='val_{}'.format(ca))
plt.legend()
plt.grid()
plt.savefig('精确度曲线图' if ca == "acc" else '损失值曲线图')
# plt.show()
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(class_num=args.num_classes).to(device)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
model.load_state_dict(torch.load(args.weights, map_location=device))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head外,其他权重全部冻结
if "head" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2)
for epoch in range(args.epochs):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
train_acc_list.append(train_acc)
train_loss_list.append(train_loss)
val_acc_list.append(val_acc)
val_loss_list.append(val_loss)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
if train_loss == min(train_loss_list):
print('save-best-epoch:{}'.format(epoch))
torch.save(model.state_dict(), "./weights/best-epoch.pth")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=10)
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=2)
parser.add_argument('--lr', type=float, default=0.0001)
# 数据集所在根目录
parser.add_argument('--data-path', type=str,
default="all_data")
# 预训练权重路径,如果不想载入就设置为空字符
parser.add_argument('--weights', type=str, default='',
help='initial weights path')
# 是否冻结权重
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
main(opt)
draw(train_acc_list, val_acc_list, 'acc')
draw(train_loss_list, val_loss_list, 'loss')
开始训练:
在all_data中准备好数据集,并设置好超参数后,即可开始运行train.py
成功运行效果展示:
1)会生成dataset.png数据集分布柱状图
2)pycharm下方实时显示相关训练日志
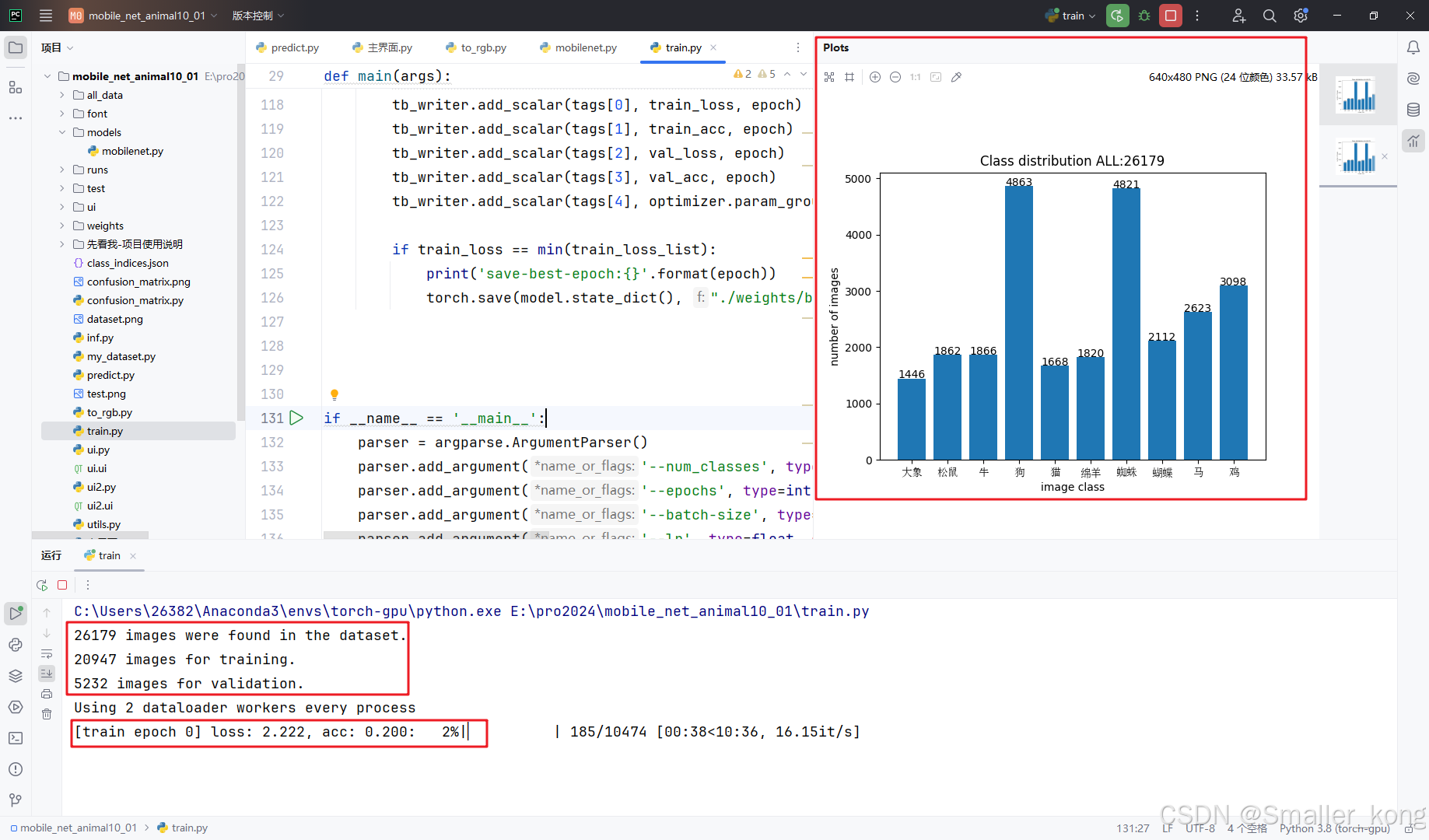
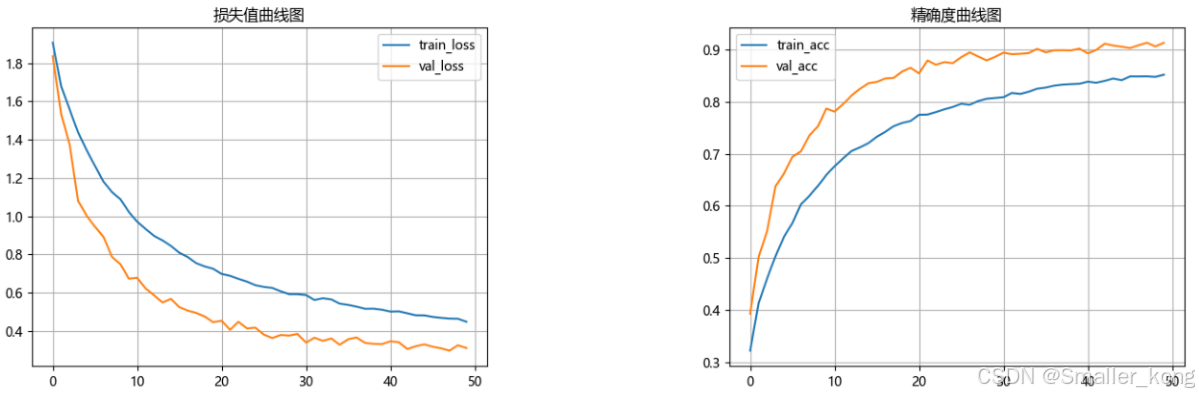
等待所有epoch训练完成后代码会自动停止,并在weights文件夹下生成训练好的模型pth文件,并生成准确率和损失值曲线图。

4、训练好的模型预测
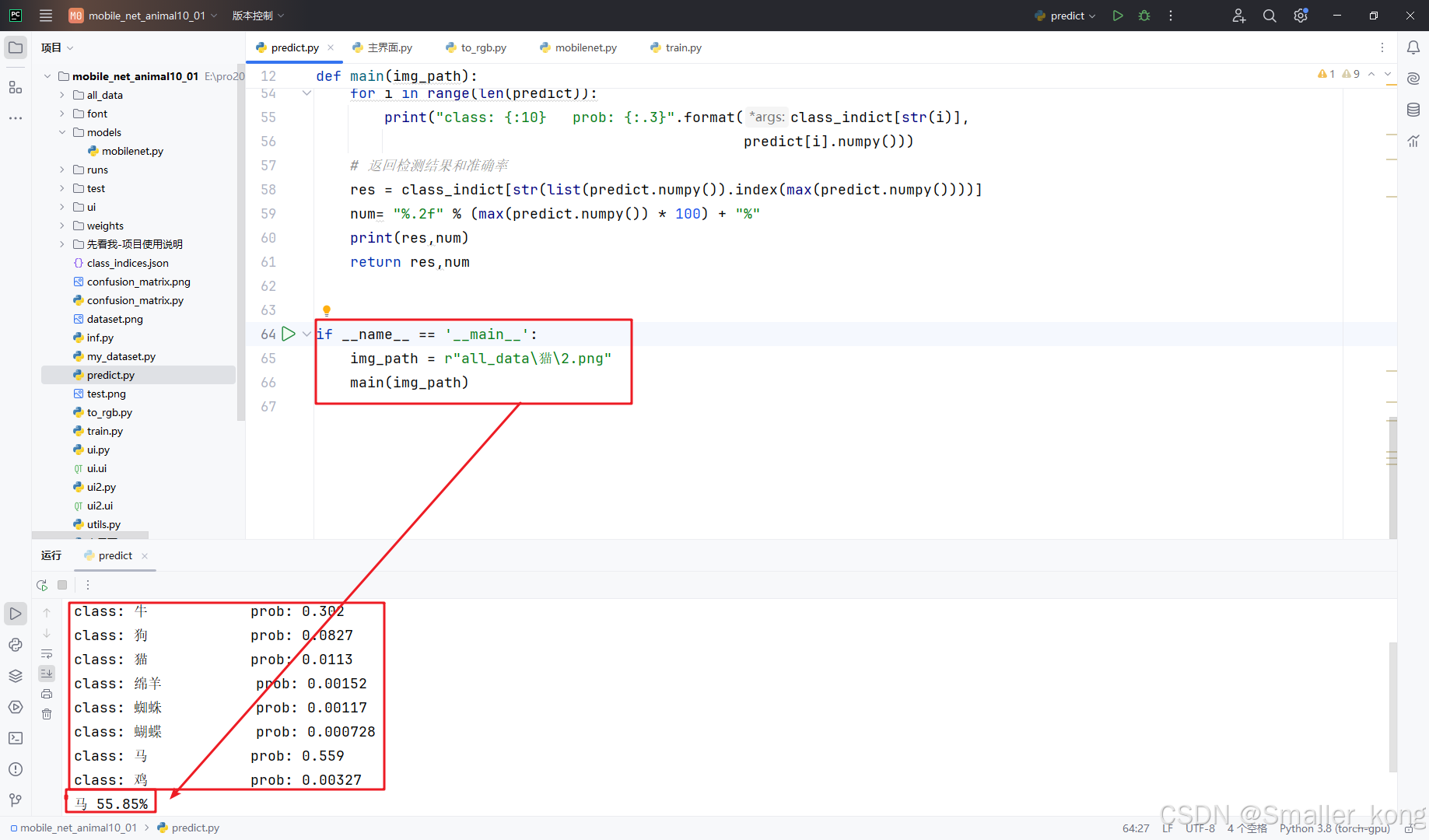
无界面预测代码为:predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from models.mobilenet import mobilenet as create_model
def main(img_path):
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model 创建模型网络
model = create_model(class_num=10).to(device)
# load model weights 加载模型
model_weight_path = "weights/best-epoch.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
#调用模型进行检测
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
# 返回检测结果和准确率
res = class_indict[str(list(predict.numpy()).index(max(predict.numpy())))]
num= "%.2f" % (max(predict.numpy()) * 100) + "%"
print(res,num)
return res,num
if __name__ == '__main__':
img_path = r"all_data\猫\2.png"
main(img_path)
使用方法:
1)设置好训练好的模型权重路径
2)设置好要预测的图像的路径
直接右键运行即可,成功运行后会在pycharm下方生成预测结果数据
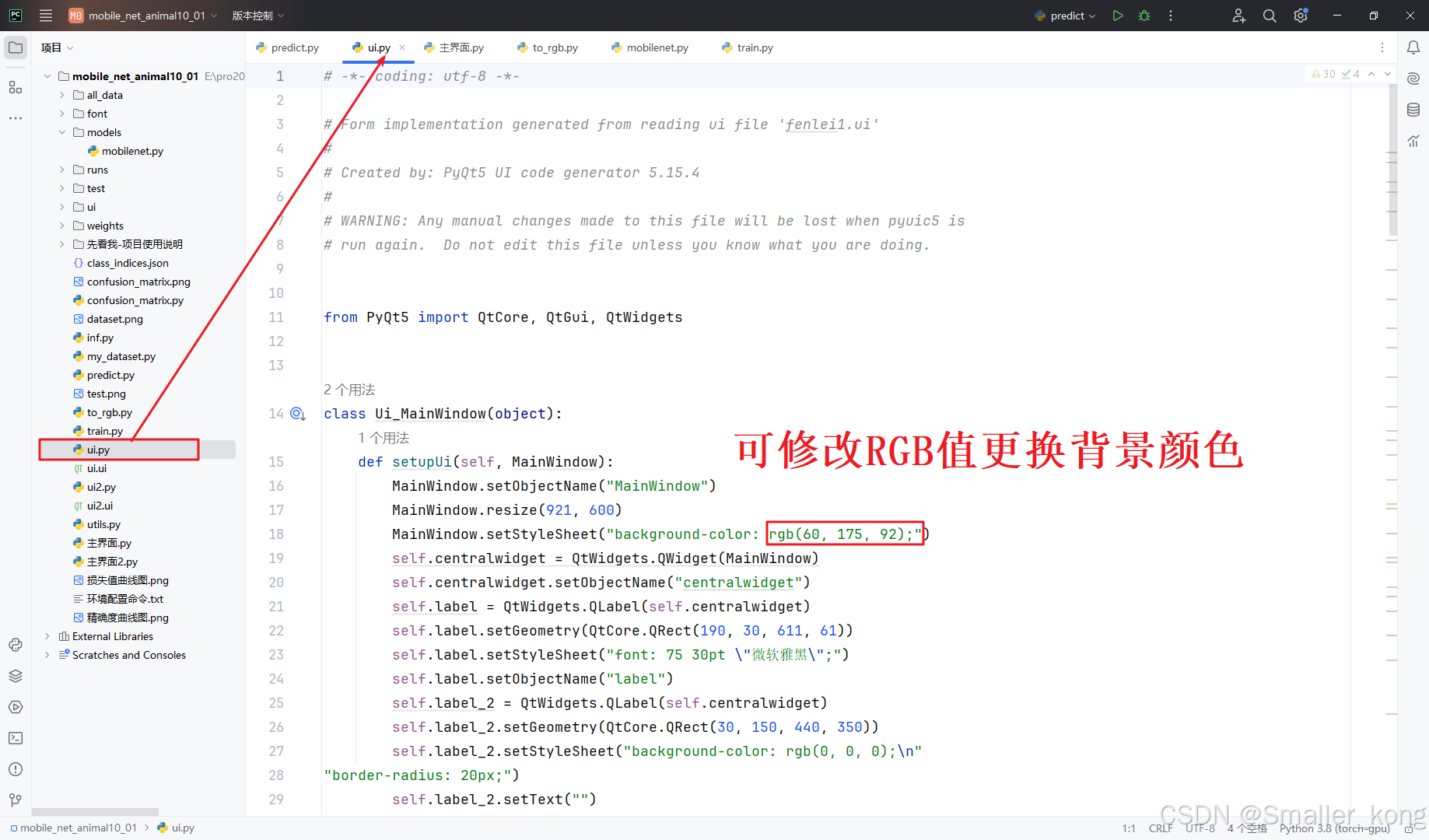
5、UI界面设计-pyqt5
两款UI样式界面,自由选择
样式1:纯色背景界面,可自由更改界面背景颜色

样式2:背景图像界面

对应代码文件:
1)ui.py 和 ui2.py
用于设置界面中控件的属性样式和显示的文本内容,可自行修改界面背景色及界面文本内容
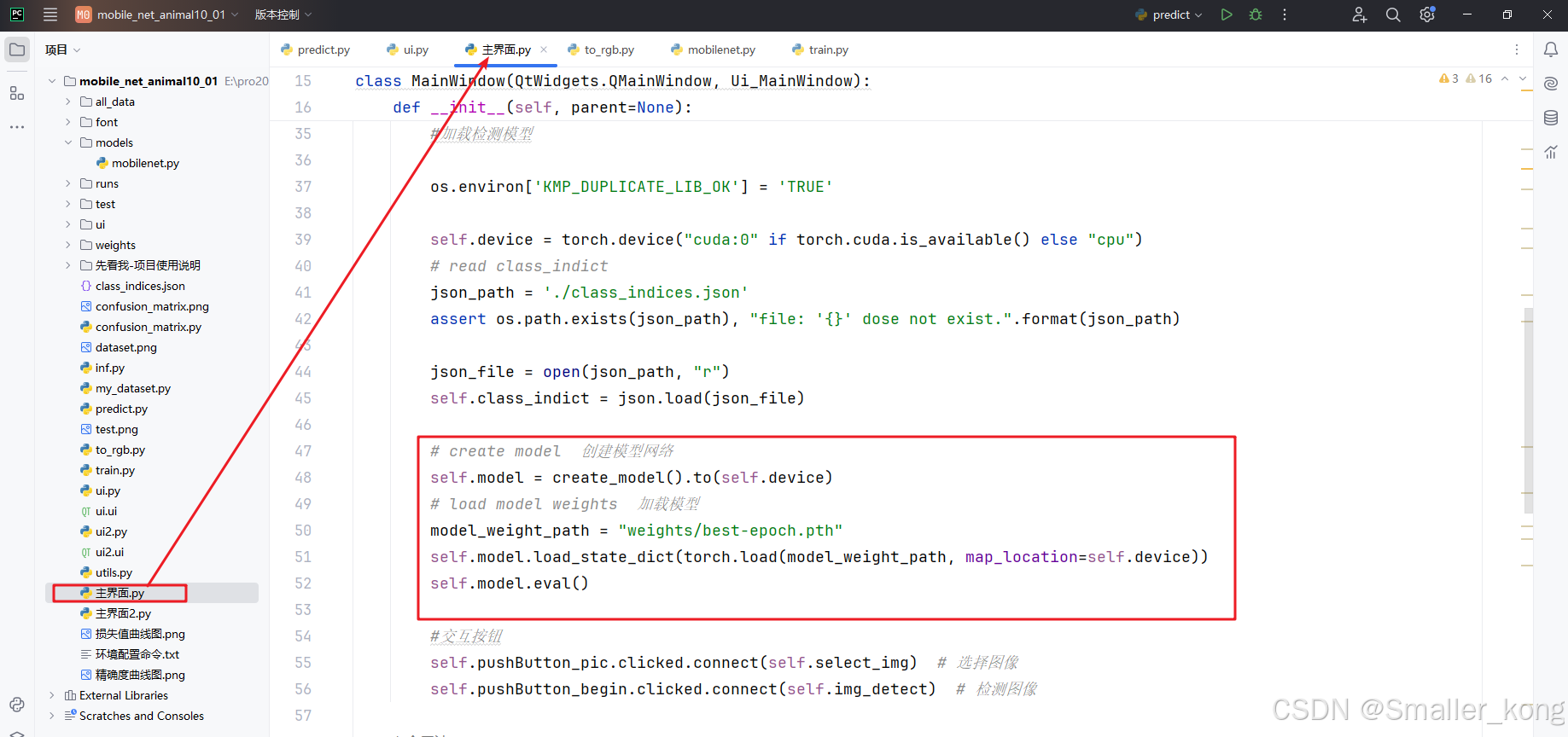
2)主界面.py 和 主界面2.py
用于设置界面中的相关按钮及动态的交互功能
3)inf.py 相关介绍及展示信息文本,可自行修改介绍信息
6、项目相关评价指标
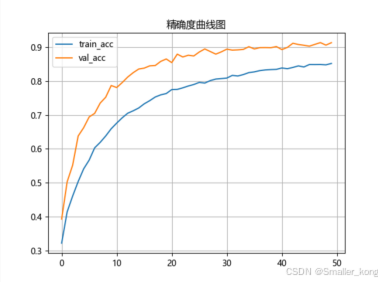
1、准确率曲线图(训练后自动生成)
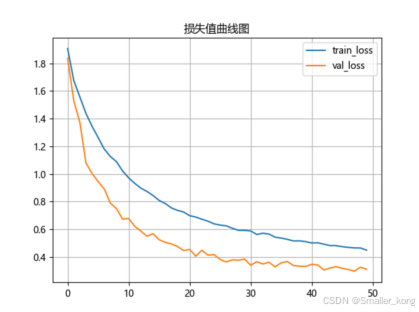
2、损失值曲线图(训练后自动生成)
3、混淆矩阵图
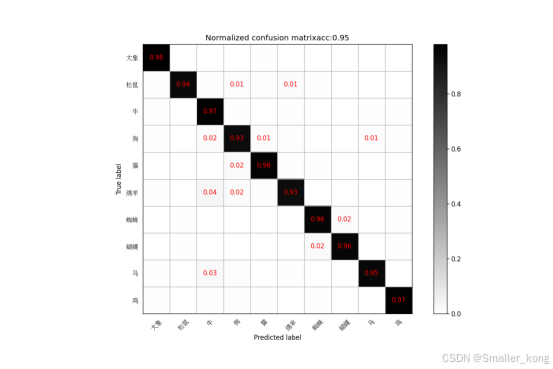
生成方式:训练完模型后,运行confusion_matrix.py文件,设置好使用的模型权重文件后,直接右键运行即可,等待模型进行预测生成
以上为本项目完整的构建实现流程步骤,更加详细的项目讲解视频如下:
https://www.bilibili.com/video/BV1CN4bejEUX/
(对程序使用,项目中各个文件作用,算法网络结构,所有程序代码等进行的细致讲解,时长1小时)
七、项目论文报告
本项目有配套的论文报告(1w字左右),部分截图如下:






















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









