



文章目录
各位同学大家好,本次给大家分享的项目为:
基于深度学习算法的番茄叶病分类系统01–带数据集-pyqt5UI界面-全套源码
项目文件获取地址:
百度网盘链接: https://pan.baidu.com/s/18o0Z2vzNEGwpw3ueVffH1g?pwd=7dxk
提取码: 7dxk
一、项目摘要
番茄叶病的早期准确识别对于提高番茄产量和保障农业生产具有重要意义。传统的人工识别方法效率低且易受人为因素影响,随着深度学习技术的发展,基于计算机视觉的病害识别方法逐渐成为研究热点。本研究提出了一种基于深度学习算法的番茄叶病分类系统,采用ShuffleNetV2网络结构在Pytorch框架下进行模型构建与训练,数据集包含11类不同的番茄叶病图像,总计32534张样本。通过数据增强、优化器和超参数的选择,最终模型在验证集上取得了0.96的最高准确率,平均分类准确率达到0.98。此外,本系统通过PyQt5库设计了用户界面,用户可以便捷地进行图像上传与分类预测。实验结果表明,该系统能够快速、准确地对番茄叶病进行分类,具有较高的实用性和推广价值。
二、项目运行效果
运行效果视频:
https://www.bilibili.com/video/BV1pgmbY1Ep7
运行效果截图:





三、项目文件介绍


四、项目环境配置
1、项目环境库
python=3.8 pytorch pyqt5 opencv matplotlib 等
2、环境配置视频教程
1)anaconda下载安装教程
2)pycharm下载安装教程
3)项目环境库安装步骤教程
五、项目系统架构

系统架构主要分为以下几个模块:
1.数据输入模块:用户可以通过系统界面上传或选择要检测的番茄叶片图像。系统支持多种常见图像格式,确保了图片导入的便捷性和灵活性。
2.数据预处理模块:在数据输入后,系统对图像进行预处理,包括尺寸调整(224x224)和归一化处理,以确保输入数据符合ShuffleNetV2模型的要求。此外,系统还进行了必要的数据增强,以提升模型对不同拍摄环境的适应性。
3.分类模型模块:该模块是系统的核心,利用训练好的ShuffleNetV2模型对预处理后的图像进行病害分类。模型将根据图像的特征进行分析,输出预测结果和相应的分类概率。
4.结果展示模块:分类完成后,系统界面会显示分类结果和置信度分数,帮助用户直观地了解番茄叶片的健康状况或可能的病害类别。
六、项目构建流程
1、数据集
数据集文件夹:all_data

概述:
本文使用的数据集11类不同番茄叶病的图像数据集,总计32,534张样本。
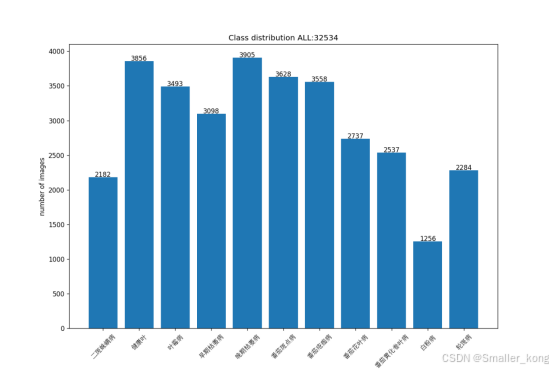
数据集格式及命令统一代码:to_rgb.py
(对数据集中的图像统一成rgb格式并进行统一规范命名)
2、算法网络ShuffleNetV2
概述:
ShuffleNetV2是近年来发展起来的一种高效的轻量级卷积神经网络,主要针对资源受限的移动设备设计,能够在低计算量和低存储需求下实现高效的图像分类。该网络结构通过通道分组、特征混洗等机制实现计算效率的提升。
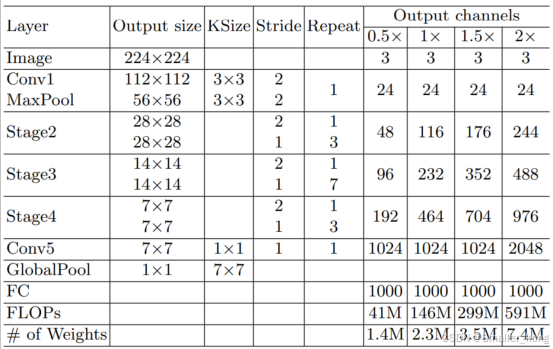
算法代码为:models文件夹下的shufflenetv2.py
"""shufflenetv2 in pytorch
[1] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, Jian Sun
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
https://arxiv.org/abs/1807.11164
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def channel_split(x, split):
"""split a tensor into two pieces along channel dimension
Args:
x: input tensor
split:(int) channel size for each pieces
"""
assert x.size(1) == split * 2
return torch.split(x, split, dim=1)
def channel_shuffle(x, groups):
"""channel shuffle operation
Args:
x: input tensor
groups: input branch number
"""
batch_size, channels, height, width = x.size()
channels_per_group = int(channels // groups)
x = x.view(batch_size, groups, channels_per_group, height, width)
x = x.transpose(1, 2).contiguous()
x = x.view(batch_size, -1, height, width)
return x
class ShuffleUnit(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super().__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
if stride != 1 or in_channels != out_channels:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, int(out_channels / 2), 1),
nn.BatchNorm2d(int(out_channels / 2)),
nn.ReLU(inplace=True)
)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, int(out_channels / 2), 1),
nn.BatchNorm2d(int(out_channels / 2)),
nn.ReLU(inplace=True)
)
else:
self.shortcut = nn.Sequential()
in_channels = int(in_channels / 2)
self.residual = nn.Sequential(
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, in_channels, 3, stride=stride, padding=1, groups=in_channels),
nn.BatchNorm2d(in_channels),
nn.Conv2d(in_channels, in_channels, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
if self.stride == 1 and self.out_channels == self.in_channels:
shortcut, residual = channel_split(x, int(self.in_channels / 2))
else:
shortcut = x
residual = x
shortcut = self.shortcut(shortcut)
residual = self.residual(residual)
x = torch.cat([shortcut, residual], dim=1)
x = channel_shuffle(x, 2)
return x
class ShuffleNetV2(nn.Module):
def __init__(self, ratio=1, class_num=11):
super().__init__()
if ratio == 0.5:
out_channels = [48, 96, 192, 1024]
elif ratio == 1:
out_channels = [116, 232, 464, 1024]
elif ratio == 1.5:
out_channels = [176, 352, 704, 1024]
elif ratio == 2:
out_channels = [244, 488, 976, 2048]
else:
ValueError('unsupported ratio number')
self.pre = nn.Sequential(
nn.Conv2d(3, 24, 3, padding=1),
nn.BatchNorm2d(24)
)
self.stage2 = self._make_stage(24, out_channels[0], 3)
self.stage3 = self._make_stage(out_channels[0], out_channels[1], 7)
self.stage4 = self._make_stage(out_channels[1], out_channels[2], 3)
self.conv5 = nn.Sequential(
nn.Conv2d(out_channels[2], out_channels[3], 1),
nn.BatchNorm2d(out_channels[3]),
nn.ReLU(inplace=True)
)
self.fc = nn.Linear(out_channels[3], class_num)
def forward(self, x):
x = self.pre(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.conv5(x)
x = F.adaptive_avg_pool2d(x, 1)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def _make_stage(self, in_channels, out_channels, repeat):
layers = []
layers.append(ShuffleUnit(in_channels, out_channels, 2))
while repeat:
layers.append(ShuffleUnit(out_channels, out_channels, 1))
repeat -= 1
return nn.Sequential(*layers)
def shufflenetv2():
return ShuffleNetV2()
3、网络模型训练
训练代码为:train.py
本研究基于Pytorch框架构建ShuffleNetV2模型,并设置了一系列训练参数:
学习率(Learning Rate):初始学习率设为0.0001,并根据训练过程中的表现进行动态调整。
优化器(Optimizer):使用AdamW优化器,该优化器相比传统Adam优化器具备更强的鲁棒性,并采用权重衰减策略(weight_decay = 5e-2)以防止过拟合。
批次大小(Batch Size):设置为8,以平衡模型训练的效率和显存占用。
损失函数(Loss Function):采用交叉熵损失函数(CrossEntropyLoss),适用于多分类任务。
训练过程中,在每个epoch后评估验证集的准确性(val_acc),并以验证集准确率最高的模型参数作为最终模型。
import os
import argparse
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from models.shufflenetv2 import shufflenetv2 as create_model
from utils import read_split_data, train_one_epoch, evaluate
def draw(train, val, ca):
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
plt.cla() # 清空之前绘图数据
plt.title('精确度曲线图' if ca == "acc" else '损失值曲线图')
plt.plot(train, label='train_{}'.format(ca))
plt.plot(val, label='val_{}'.format(ca))
plt.legend()
plt.grid()
plt.savefig('精确度曲线图' if ca == "acc" else '损失值曲线图')
# plt.show()
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model().to(device)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
model.load_state_dict(torch.load(args.weights, map_location=device))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head外,其他权重全部冻结
if "head" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2)
for epoch in range(args.epochs):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
train_acc_list.append(train_acc)
train_loss_list.append(train_loss)
val_acc_list.append(val_acc)
val_loss_list.append(val_loss)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
if val_acc == max(val_acc_list):
print('save-best-epoch:{}'.format(epoch))
with open('loss.txt', 'w') as fb:
fb.write(str(train_loss) + ',' + str(train_acc) + ',' + str(val_loss) + ',' + str(val_acc))
torch.save(model.state_dict(), "./weights/tomato-best-epoch.pth")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=11)
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.0001)
# 数据集所在根目录
parser.add_argument('--data-path', type=str,
default="all_data")
# 预训练权重路径,如果不想载入就设置为空字符
parser.add_argument('--weights', type=str, default='',
help='initial weights path')
# 是否冻结权重
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
main(opt)
draw(train_acc_list, val_acc_list, 'acc')
draw(train_loss_list, val_loss_list, 'loss')
开始训练:
在all_data中准备好数据集,并设置好超参数后,即可开始运行train.py
成功运行效果展示:
1)会生成dataset.png数据集分布柱状图
2)pycharm下方实时显示相关训练日志
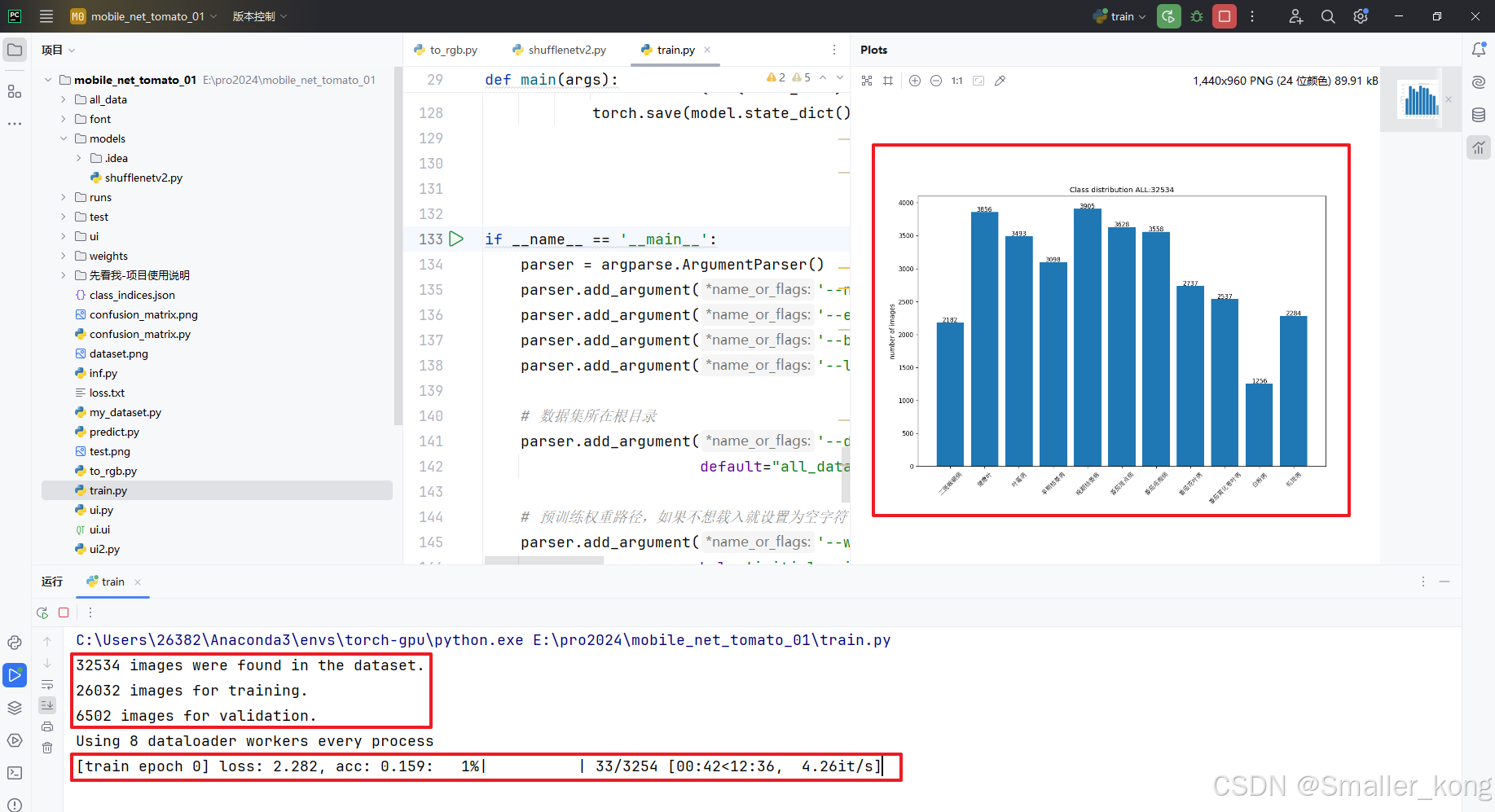
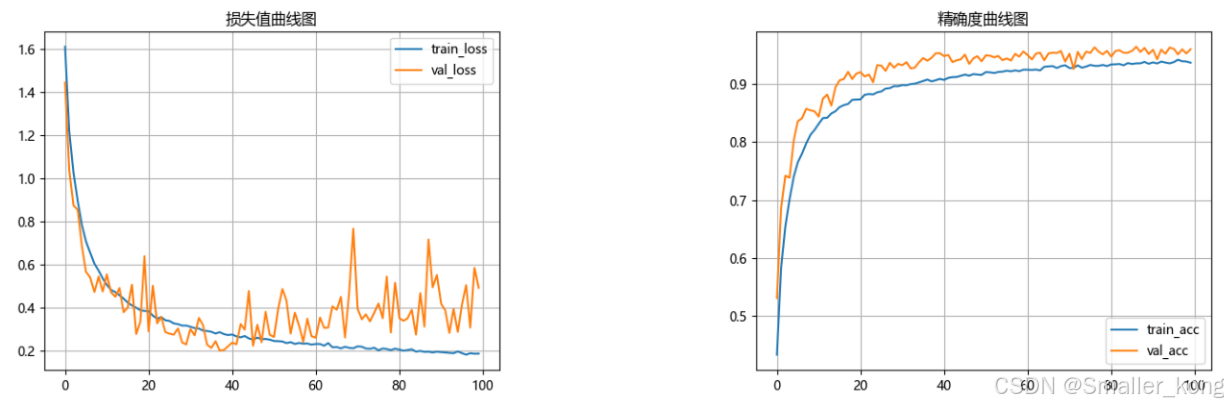
等待所有epoch训练完成后代码会自动停止,并在weights文件夹下生成训练好的模型pth文件,并生成准确率和损失值曲线图。

4、训练好的模型预测
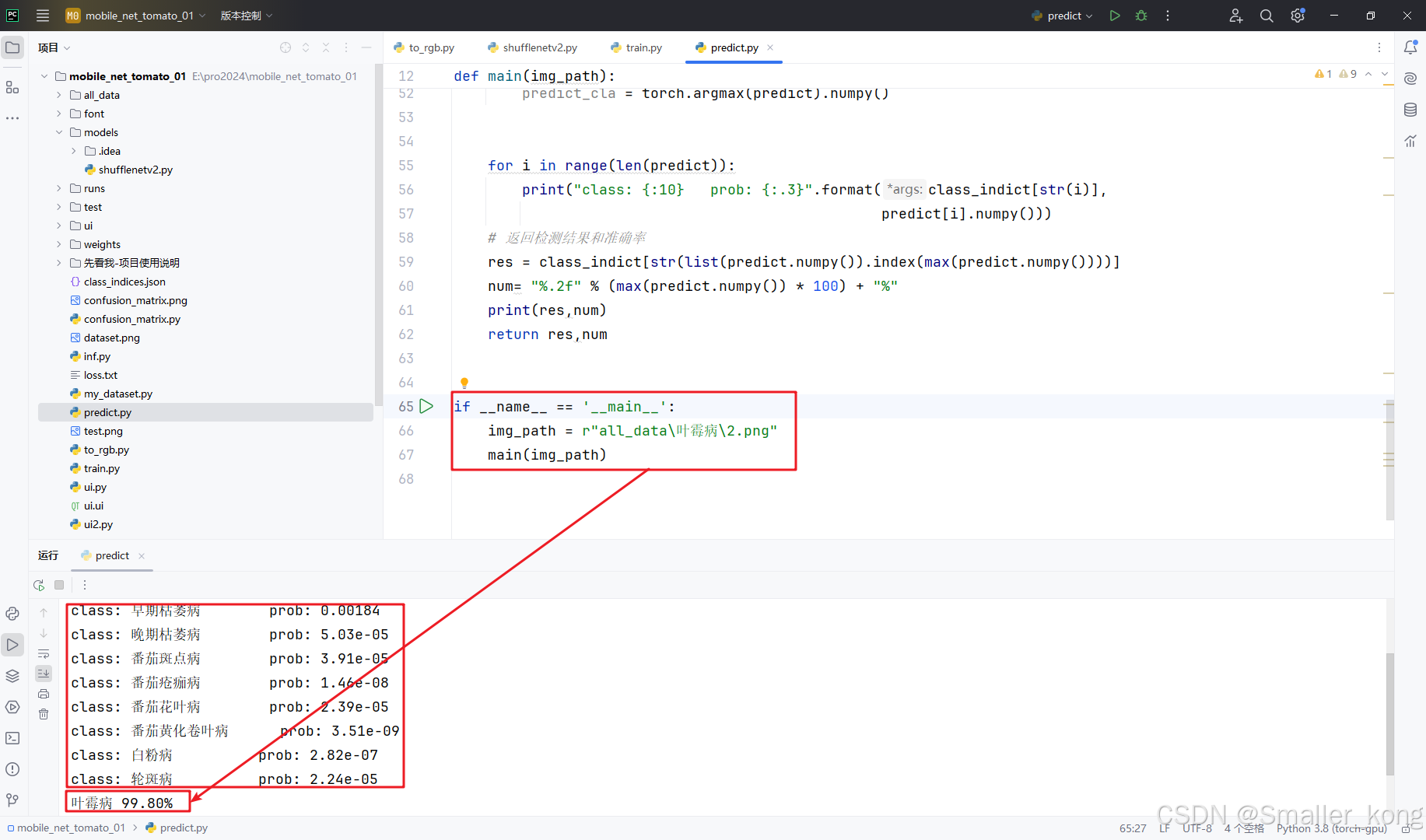
无界面预测代码为:predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from models.shufflenetv2 import shufflenetv2 as create_model
def main(img_path):
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = 224
data_transform = transforms.Compose(
[transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model 创建模型网络
model = create_model().to(device)
# load model weights 加载模型
model_weight_path = "weights/tomato-best-epoch.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
#调用模型进行检测
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
# 返回检测结果和准确率
res = class_indict[str(list(predict.numpy()).index(max(predict.numpy())))]
num= "%.2f" % (max(predict.numpy()) * 100) + "%"
print(res,num)
return res,num
if __name__ == '__main__':
img_path = r"all_data\叶霉病\2.png"
main(img_path)
使用方法:
1)设置好训练好的模型权重路径
2)设置好要预测的图像的路径
直接右键运行即可,成功运行后会在pycharm下方生成预测结果数据
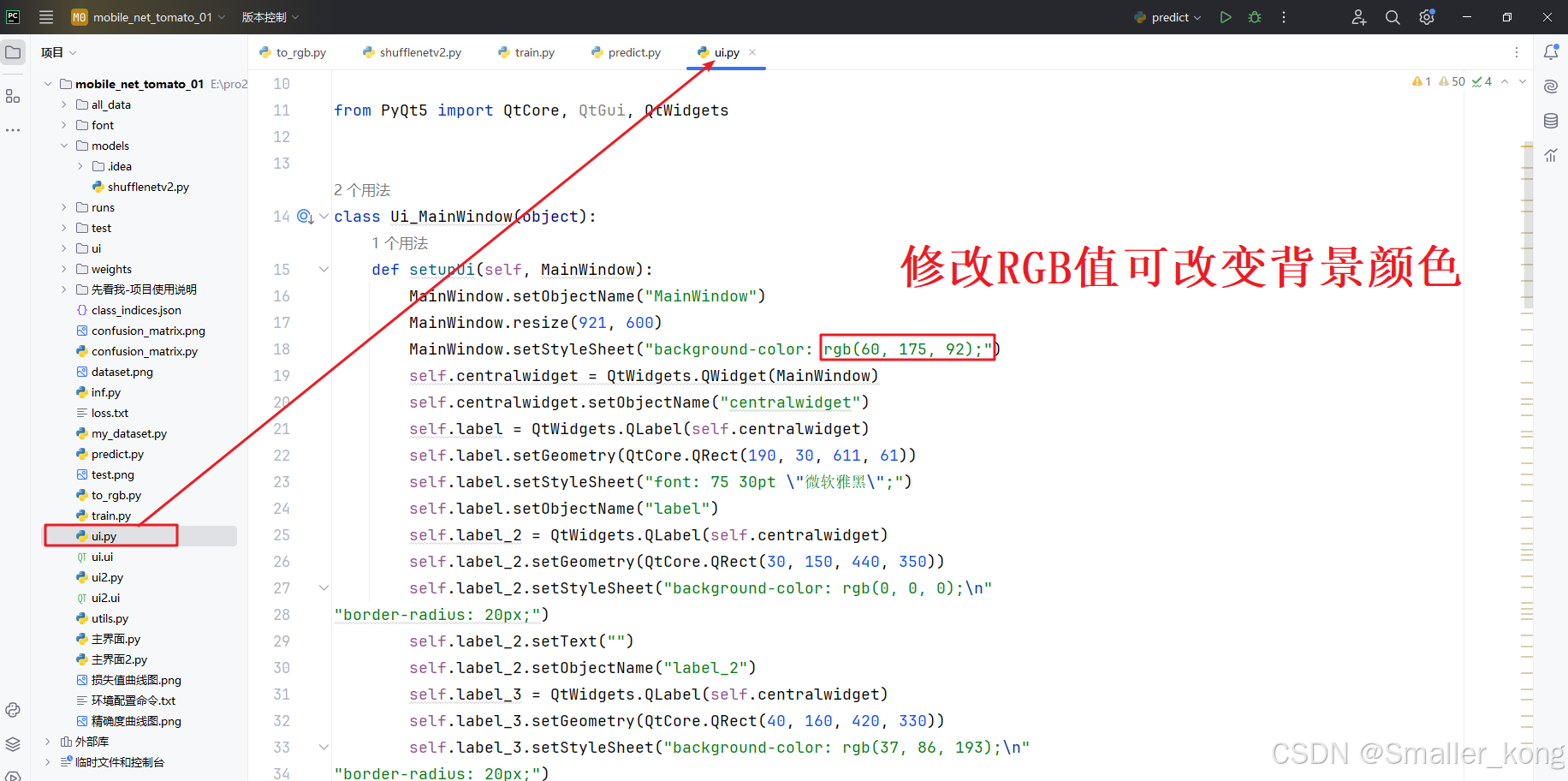
5、UI界面设计-pyqt5
两款UI样式界面,自由选择
样式1:纯色背景界面,可自由更改界面背景颜色

样式2:背景图像界面

对应代码文件:
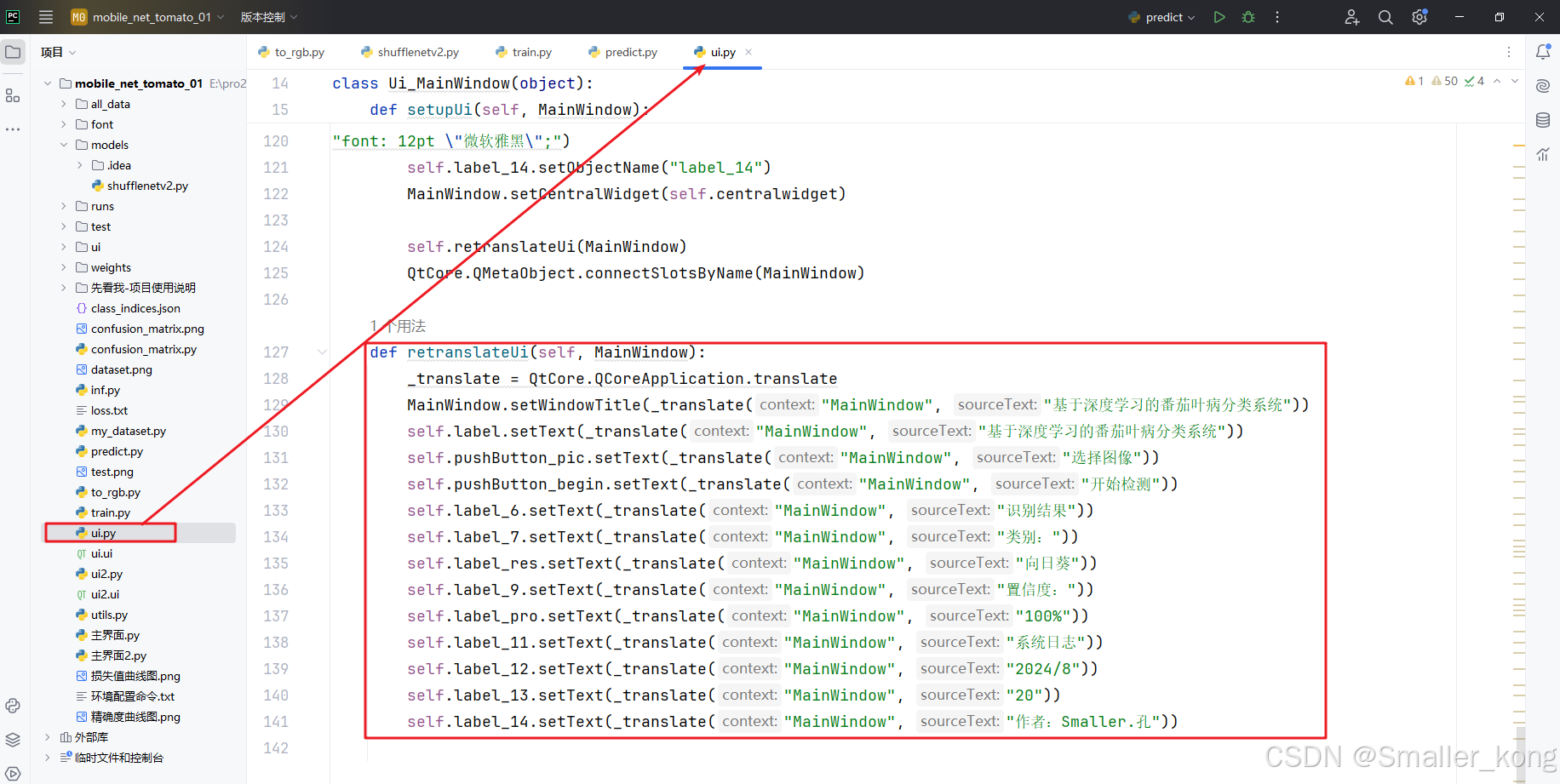
1)ui.py 和 ui2.py
用于设置界面中控件的属性样式和显示的文本内容,可自行修改界面背景色及界面文本内容
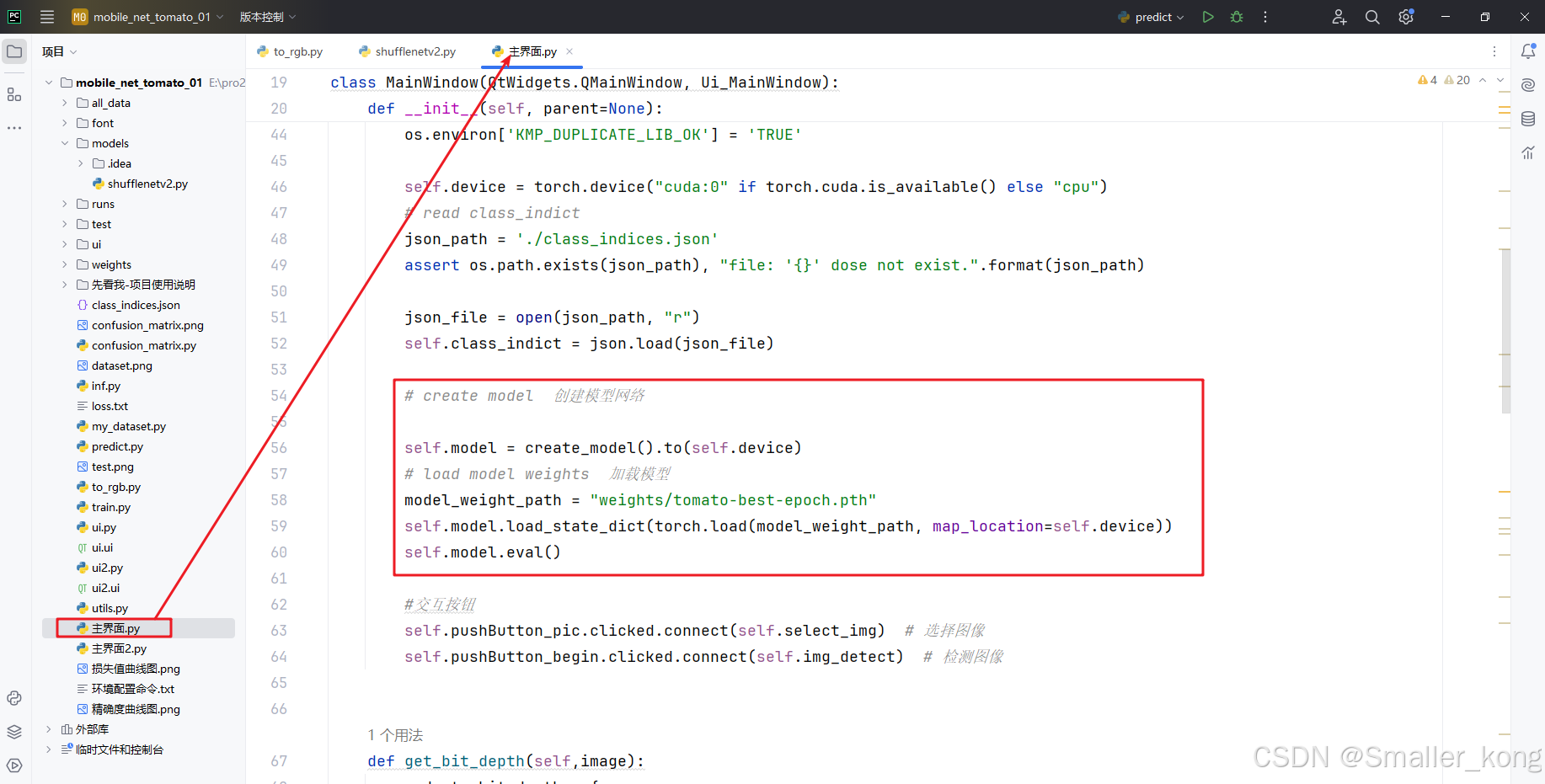
2)主界面.py 和 主界面2.py
用于设置界面中的相关按钮及动态的交互功能
3)inf.py 相关介绍及展示信息文本,可自行修改介绍信息
6、项目相关评价指标
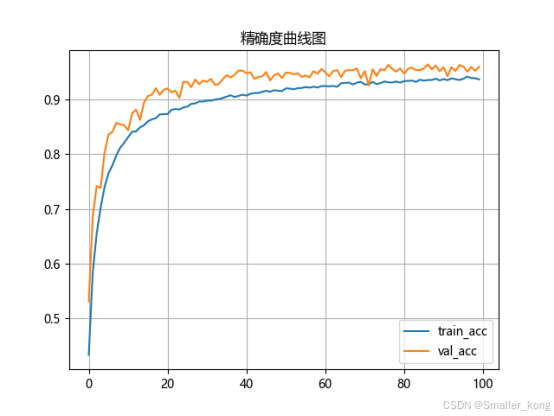
1、准确率曲线图(训练后自动生成)
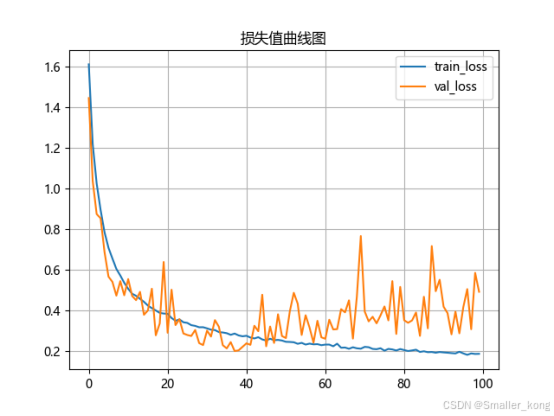
2、损失值曲线图(训练后自动生成)
3、混淆矩阵图
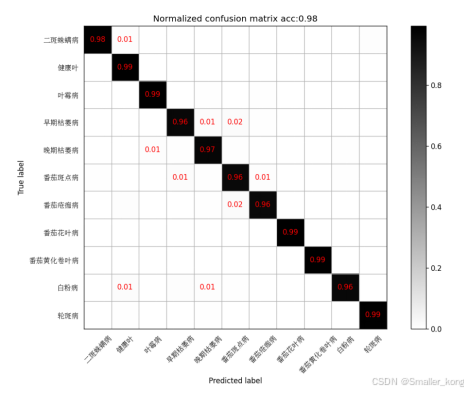
生成方式:训练完模型后,运行confusion_matrix.py文件,设置好使用的模型权重文件后,直接右键运行即可,等待模型进行预测生成
以上为本项目完整的构建实现流程步骤,更加详细的项目讲解视频如下:
https://www.bilibili.com/video/BV1pGmbY5Egb
(对程序使用,项目中各个文件作用,算法网络结构,所有程序代码等进行的细致讲解,时长1小时)
七、项目论文报告
本项目有配套的论文报告(8k字左右),部分截图如下:






















 6242
6242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









