




@浙大疏锦行
一、什么是独热编码?
独热编码(One-Hot Encoding) 是一种常用的将分类变量(categorical features)转化为数值表示的方法。
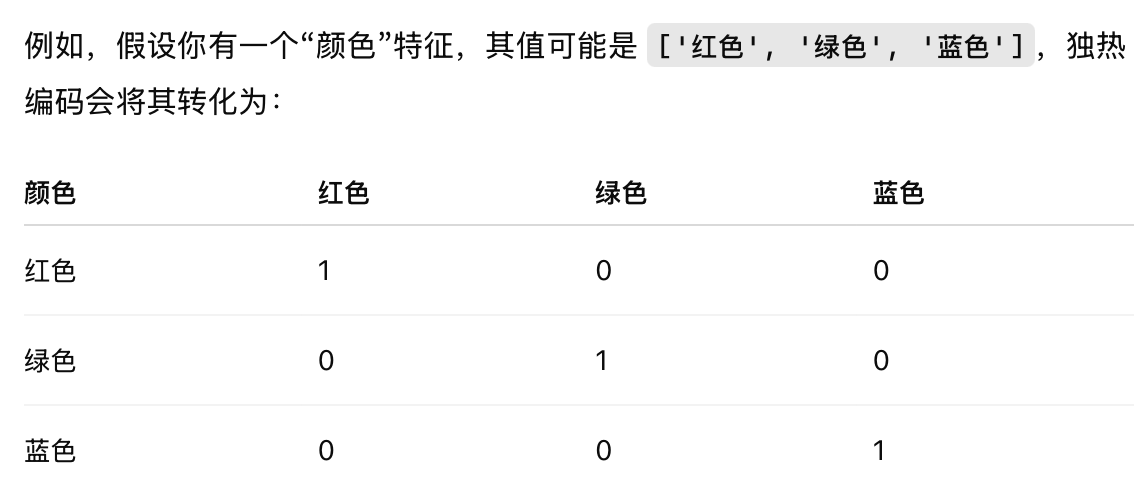
例如,假设你有一个“颜色”特征,其值可能是 ['红色', '绿色', '蓝色'],独热编码会将其转化为:
二、代码实战讲解(处理离散特征和缺失值)
1. 导入依赖 & 读取数据
import pandas as pd
data = pd.read_csv("data.csv") # 或根据文件格式选择 pd.read_excel / pd.read_table
2. 区分连续变量和离散变量
-
离散变量:数据类型为
object或category -
连续变量:数值类型(int, float 等)
discrete_cols = [col for col in data.columns if data[col].dtype == 'object']
continuous_cols = [col for col in data.columns if data[col].dtype != 'object']
3. 对离散变量进行独热编码
data = pd.get_dummies(data, columns=discrete_cols)
作业:
现在在py文件中 一次性处理data数据中所有的连续变量和离散变量
1. 读取data数据
2. 对离散变量进行one-hot编码
3. 对独热编码后的变量转化为int类型
4. 对所有缺失值进行填充
导入数据
import pandas as pd
data = pd.read_csv("data.csv")
data.columns使用循环一次性对离散变量进行独热编码
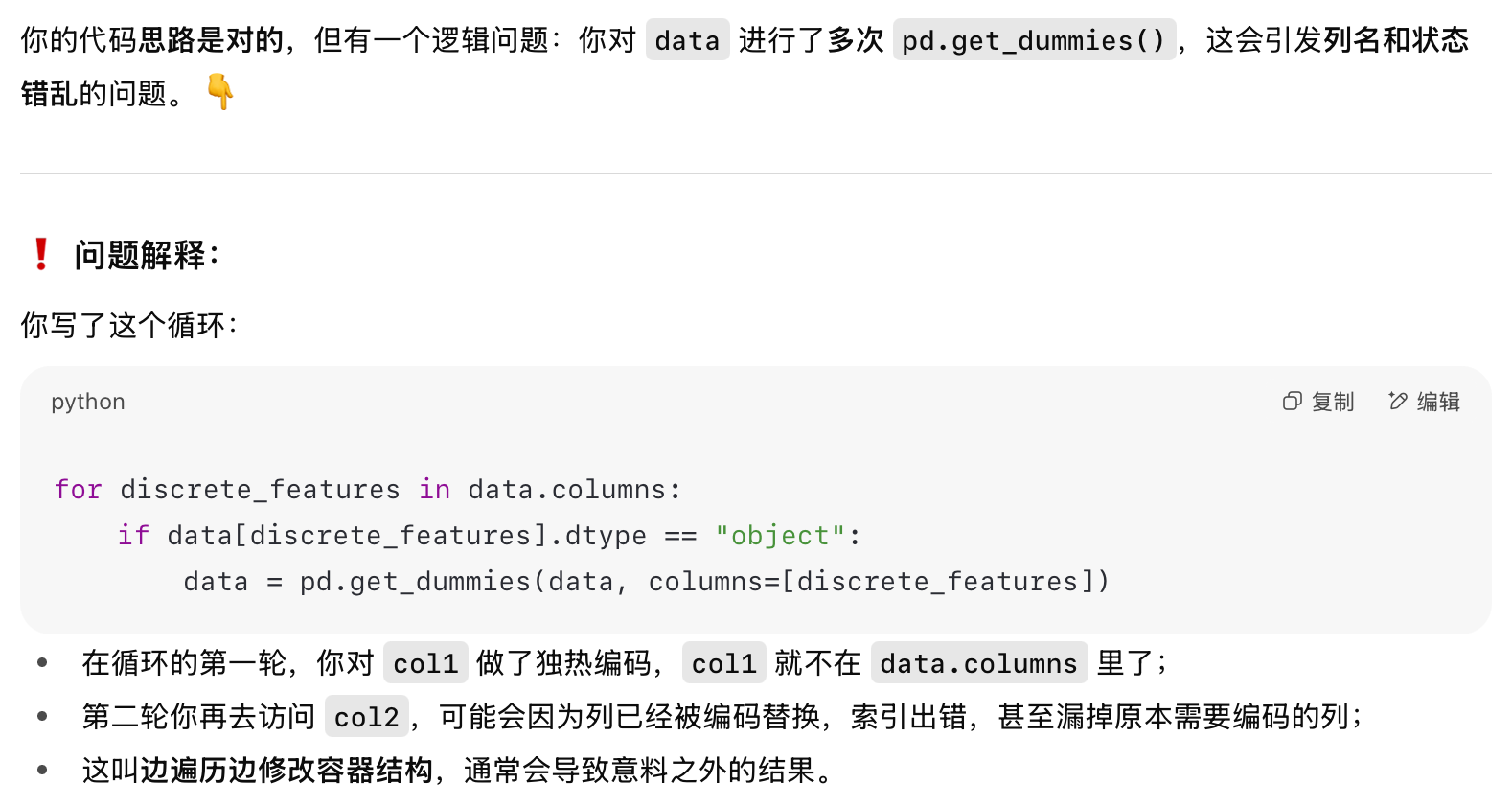
一开始是这么写的,但是不对,pd.get_dummies()最好不要放在循环里
for discrete_features in data.columns:
if data[discrete_features].dtype == "object":
print(discrete_features)
for discrete_features in data.columns:
if data[discrete_features].dtype == "object":
data = pd.get_dummies(data,columns=[discrete_features])
一次性找出所有离散变量,再统一调用一次 pd.get_dummies()
import pandas as pd
# 1. 读取数据
data = pd.read_csv("data.csv")
# 2. 保存编码前的列名
before_cols = data.columns
# 3. 找出离散变量列名(dtype 为 object)
discrete_cols = [col for col in data.columns if data[col].dtype == "object"]
print("待编码的列:", discrete_cols)
# 4. 一次性进行独热编码
data = pd.get_dummies(data, columns=discrete_cols)
# 5. 找出新增列
new_cols = data.columns.difference(before_cols)
print("独热编码新增列:", new_cols.tolist())
对独热编码后的变量转化为int类型
for i in new_cols:
data[i] = data[i].astype(int) # 这里的i就是独热编码后的特征名
data.head()用平均值填充缺失值
data.isnull().sum() # 统计每一列的缺失值个数
for i in data.columns:
if data[i].isnull().sum() >0:
meanvalue = data[i].mean()
data[i].fillna(meanvalue,inplace=True)
data.isnull().sum()
















 7535
7535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









