









本文记录了博主阅读论文《Panoptic Segmentation with a Joint Semantic and Instance Segmentation Network》(JSIS-Net)的笔记。更新于2019.04.16。
文章目录
摘要
这个方法用一个网络实现全景分割。网络结构包括由语义分割和全景分割分支共享的ResNet-50特征提取器、用于实例分割的Mask R-CNN型结构,和用于予以分割的Pyramid Pooling Module。本文的结果提交了COCO and Mapillary Joint Recognition Challenge 2018,在Mapillary Vistas validation set上的PQ score为17.6,在COCO test-dev set上为27.2。
方法
网络结构包括两部分:联合估计语义和实例的CNN+正和全景分割的heuristics。
网络结构
联合估计语义与实例的CNN的共用基础结构是ResNet-50,如下图所示。
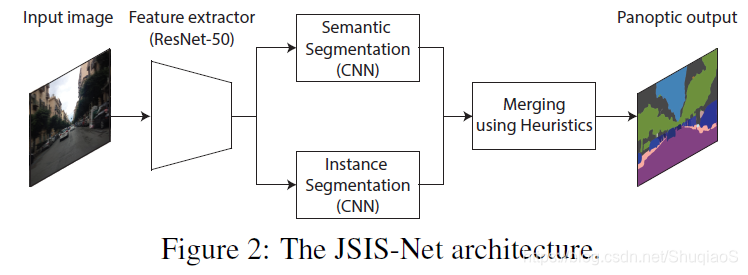
语义分割分支用用了金字塔池化模块生成特征图,再用混合上采样将估计还原成输入尺寸。这个混合上采样方法先应用deconvolution,再将predictions通过双线性插值恢复成输入图像的尺寸。这个过程的输出是一个像素级的map,每个像素点都有对应的类别标签。
实例分割分支是基于Mask R-CNN的。首先用一个Region Proposal Network(RPN)生成隐含目标的region proposals;随后将这些proposals对应的特征从特征图中提取出来,通过(subject to)ResNet-50的最后几层。最后,用这些特征生成三个平行的predictions:一个classification score,bounding box坐标,和一个instance mask。在应用了非极大值抑制(non-maximum suppression)后,这个分值的输出是一些含有类别标签的pixel clusters的集合。经过后处理后,这些pixel clusters会变成per-object normalized isntance masks,与输入图像尺寸相同。
【即实例分割分支直接出来的是聚类,需要通过后处理变成像素级的instance mask】
Loss balancing for joint learning
损失形如:
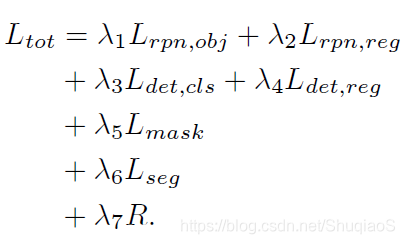
其中,
L
r
p
n
,
o
b
j
L_{rpn,obj}
Lrpn,obj是用于RPN的softmax cross-entropy目标损失函数(objectness loss function),
L
r
p
n
,
r
e
g
L_{rpn,reg}
Lrpn,reg是用于RPN的smooth L1回归损失函数。
L
d
e
t
.
c
l
s
L_{det.cls}
Ldet.cls是用于目标检测的softmax cross-entropy分类损失函数,
L
d
e
t
,
r
e
g
L_{det,reg}
Ldet,reg是用于目标bounding boxes的smooth L1 回归损失函数,
L
m
a
s
k
L_{mask}
Lmask是用于实例mask的sigmoid cross-entropy loss,
L
s
e
g
L_{seg}
Lseg是用于分割输出的sparse softmax cross-entropy segmentation loss。最后,
R
R
R是对于模型的L2 regularization。权重
λ
1
…
λ
n
\lambda_1\dots\lambda_n
λ1…λn是用于平衡损失的
n
n
n tunning parameters。
Merging heuristics
由于全景分割要求每个像素点要有两个标注:类别和实例id。因此就需要解决重叠的instance masks和冲突的things classes这两个问题。
Overlapping instance masks
实例分割的本质是基于目标检测的,这就导致了不同实例mask之间可能存在重叠。尽管可以通过对所有重叠区域应用non-maximum supression的方法去除重叠,但这样做也会去除许多真实标签。因此,这里用per-instance probability maps的方法解决有争议的区域,也就是当一个像素点被认为属于多个实例时,它会选择概率最大的那个实例作为自己的实例。
Conflicting predictions for things classes
与stuff类别不同,things类别同时属于语义分割与实例分割任务,因此,就不可避免地会出现两个分支的歧义,而这两个分支的输出又不能直接比较。于是,论文中采用了这种方法:把所有的things类别从语义分割中去除,并用最可能的stuff类别替换。这就使得所有的语义分割结果都是对应stuff类别的。再用things类别替换对应的位置。
随后移除所有少于4096个点的stuff类别。
Implementation
训练过程整个网络是联合训练的,用动量为0.9的SGD优化算法。初始学习率0.075,随后依次减半,减半的频率由数据决定。损失和归一化权重如下表所示。

网络由在ImageNet数据集下训练的权重初始化。在单个Titan Xp GPU上训练。
网络在两个数据集上进行训练和测试:Mapillary Vistas和COCO。
具体实施规则如下:


Results
结果如下表所示:

度量:Panoptic Quality (PQ),Segmentation Quality (SQ)和Recognition Quality (RQ)。


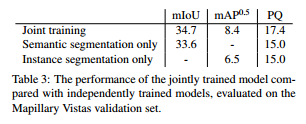
Joint training vs. independent training

加入星球了解更多分割知识:


















 3194
3194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









