





📢 CircularNet 垃圾识别:用机器学习从废品中分拣可回收材料
https://blog.tensorflow.org/2022/10/circularnet-reducing-waste-with-machine.html
据统计,全球资源只有不到 10% 被有效回收利用,与此同时每 5 件物品中就有 1 件(约 17%)被错误地扔进了回收箱。有效的回收策略对于可持续发展至关重要,那么如何利用技术力量来确保能够回收更多并正确回收?

材料回收设施(MRF)每天将有价值的可回收材料(金属/塑料等)与不可回收材料分开,这个过程中无法识别废物并将其分离成高质量的材料,是关键的低效率因素。分选的准确性直接决定了回收料的质量。本文使用 CircularNet,开发一个强大且数据高效的废物/可回收物检测模型,提升整个垃圾管理生态系统中识别、分类、管理和回收材料的效率。
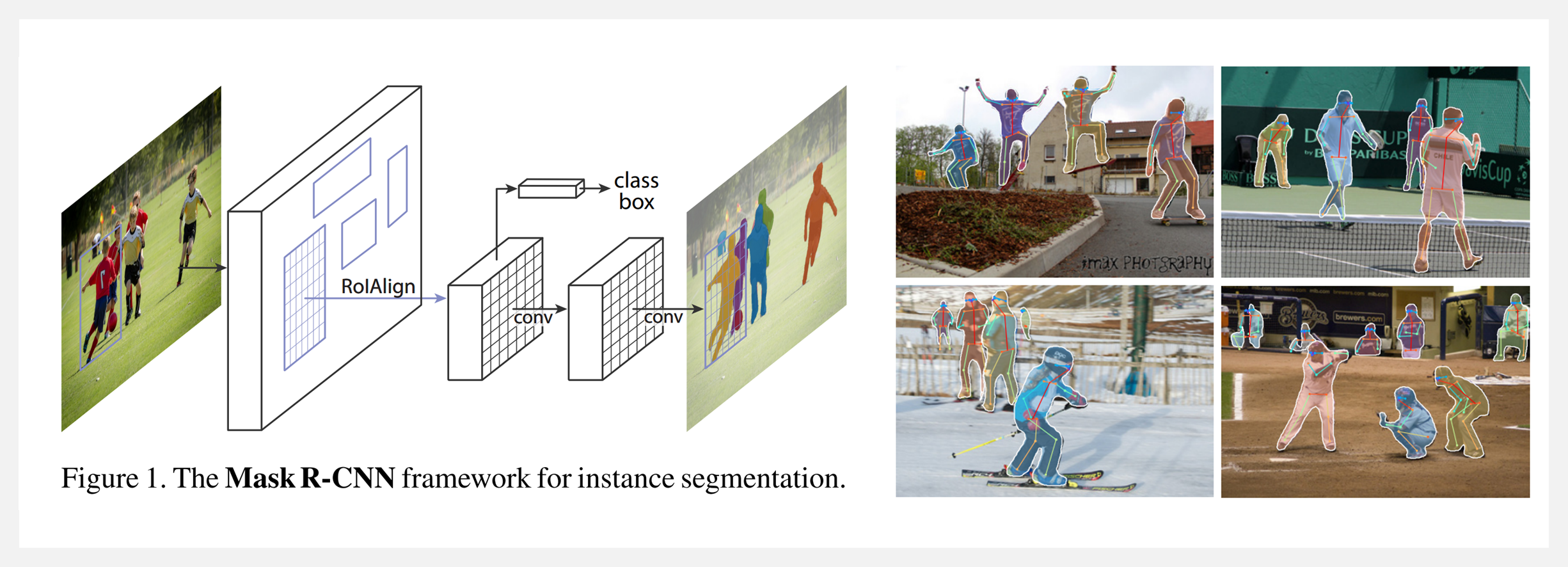
CircularNet 模型旨在通过使用 Mask R-CNN 算法对数千张图像进行训练来执行实例分割。通过与回收行业的专家合作,作者团队开发了一种定制的、全球适用的材料类型与形式标签,用于标注模型的训练数据,并使用 ResNet、MobileNet 和 SpineNet 等网络开发了模型来识别材料类型、材料形式和塑料类型等。完整流程包括:
- 数据导入、清洗和预处理
- 收集数据后,必须将注释文件转换为 COCO JSON 格式。从 COCO JSON 文件中删除所有噪音、错误和不正确的标签。损坏的图像也从 COCO JSON 和数据集中删除,以确保顺利训练
- 最终文件被转换为 TFRecord 格式以便更快的训练
- 训练
- Mask RCNN 是使用 Google Cloud Platform 上的 Model Garden 存储库进行训练的
- 超参数优化是通过改变图像大小、批量大小、学习率、训练步骤、时期和数据增强步骤来完成的
- 模型转换
- 训练模型后实现的最终检查点被转换为保存模型和 TFLite 模型格式,以支持服务器端和边缘端部署
-模型部署- 在 Google Cloud 上部署模型以进行服务器端推理和边缘计算设备
- 可视化

工具&框架
🚧 『EVA Video Analytics System』探索性视频分析系统
https://github.com/georgia-tech-db/eva
https://evadb.readthedocs.io/en/latest/
EVA 是一个为视频分析量身定制的新数据库系统——可以看作视频的 MySQL。它支持一种简单的类似 SQL 的语言来查询视频(例如,在电影中与您最喜欢的演员一起查找帧或在足球比赛中查找达阵)。它配备了广泛的常用计算机视觉模型。

🚧 『Code4Me』用于 JetBrains 和 VScode 的两个 IDE 代码自动补全扩展
https://github.com/code4me-me/code4me
Code4Me 基于大型预训练语言模型,通过预测语句(行)提供代码自动补全,可用于 PyCharm(以及其他 JetBrains IDEs)和 Visual Studio Code。Jetbrains 的触发字符为 ALT + SHIFT + K,VScode 的触发字符为 triggerSuggest 命令的键绑定(可能是 CTRL + Space)。

🚧 『diffusion-ui』深度学习图像生成前端
https://github.com/leszekhanusz/diffusion-ui
https://diffusionui.readthedocs.io/en/latest/
这是一个使用 Stable Diffusion 模型生成图像的 Web 界面前端。其目的是为在线和离线后端提供一个接口,以便像 Stable Diffusion 那样进行图像生成和绘画。
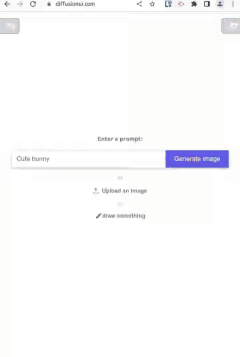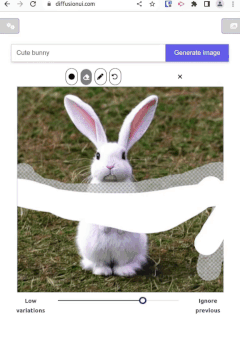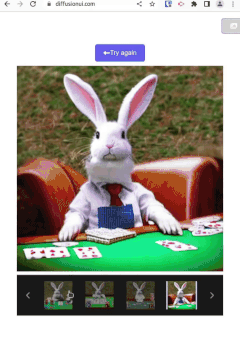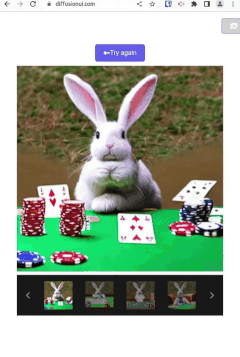
🚧 『PyTorch Template Using DistributedDataParallel』PyTorch分布式模板
https://github.com/Janspiry/distributed-pytorch-template
这是一个分布式PyTorch训练的模板项目,你可以基于它快速定制你的网络。它具备以下特点:
- 使用DistributedDataParallel的分布式训练
- 可扩展的基类
- .json配置文件用于大多数参数的调整
- 支持多个网络/损失/度量定义
- 用于快速测试的调试模式 🌟

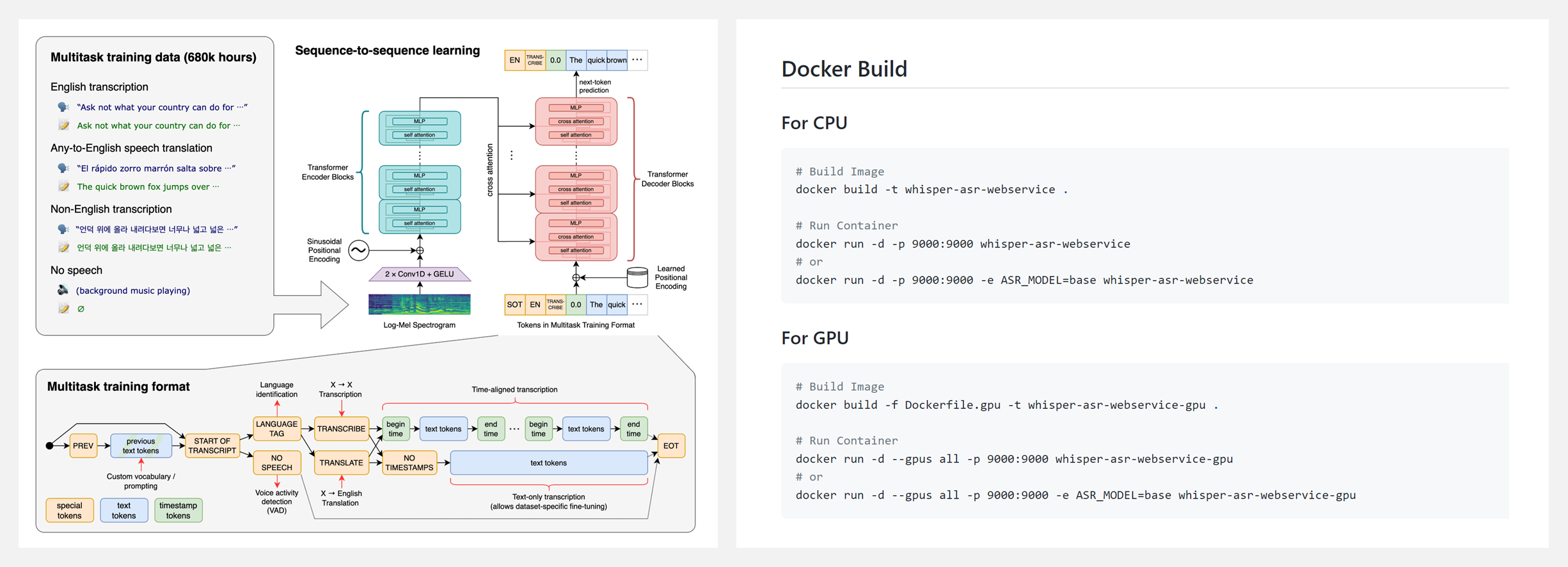
🚧 『Whisper ASR Webservice』Whisper 语音识别的 Webservice
https://github.com/ahmetoner/whisper-asr-webservice
https://github.com/openai/whisper
Whisper 是一个通用的语音识别模型。它是在一个大型的多样化音频数据集上训练出来的,也是一个多任务模型,可以进行多语言语音识别以及语音翻译和语言识别。更多细节在上方第二个链接。
博文&分享
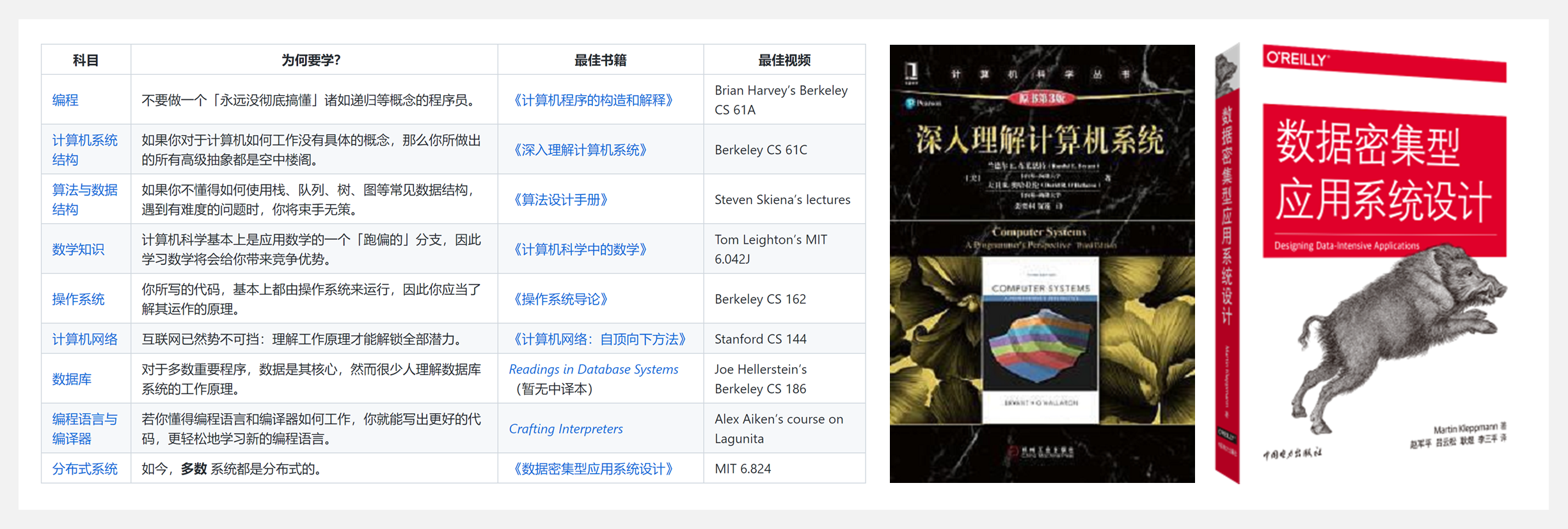
👍 『TeachYourselfCS』计算机科学自学计划(中文翻译版)
https://github.com/izackwu/TeachYourselfCS-CN/blob/master/TeachYourselfCS-CN.md
自学计算机科学需要学习哪些科目?这些科目,最好的书籍或者视频课程是什么?
这份教程的作者尝试对这些问题给出了确定的答案——大致按照列出的顺序,使用参考教材&课程,学习如下 9 门科目:编程、计算机系统结构、算法与数据结构、数学知识、操作系统、计算机网络、数据库、编程语言与编译器、分布式系统。
当然如果自学 门科目还是让你望而却步,那建议只专注于两本书:《深入理解计算机系统》《数据密集型应用系统设计》。
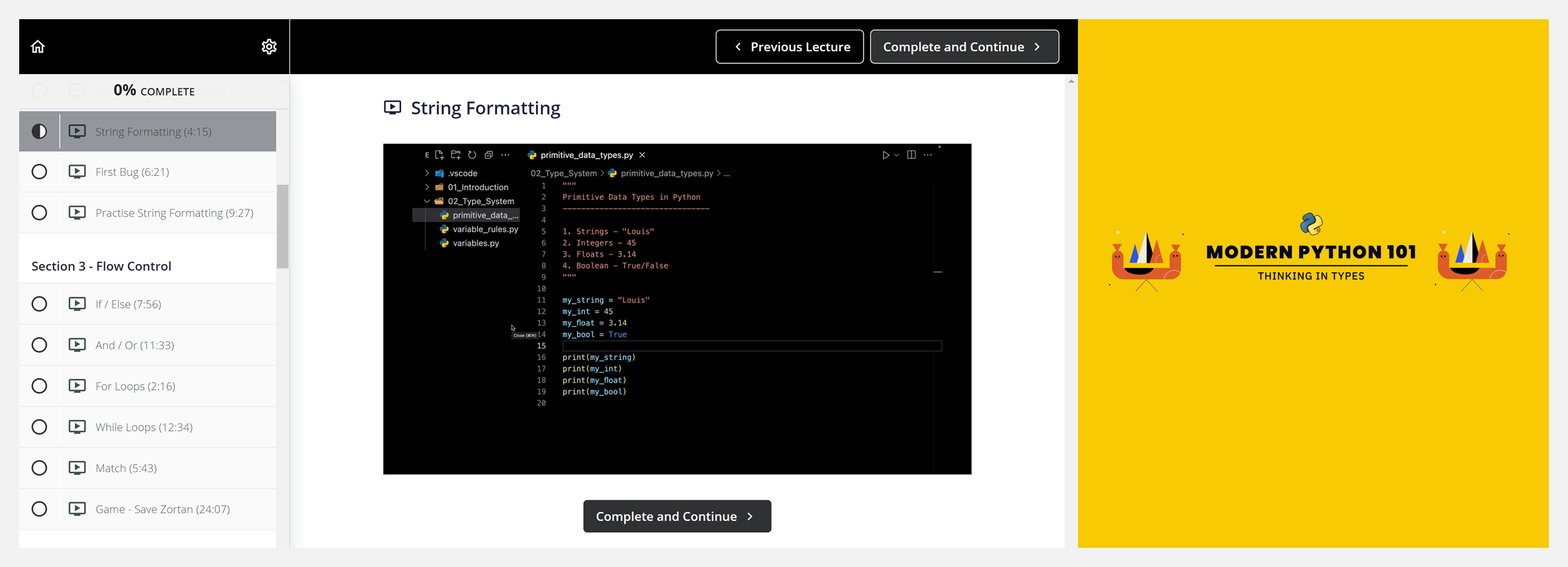
👍 『Modern Python 101 | Thinking in Types』现代Python入门指南
https://github.com/octallium/modern-python-101
https://learn.octallium.com/p/modern-python-101-thinking-in-types
Python 对于初学者而言是一门完美的编程语言,上手简单,并且可以快速创建各类应用—— Web 应用程序、游戏、桌面应用程序、数据科学项目、AI 等等!
这是一份 Python 编程语言的入门指南,简单易懂且免费,不需要具备任何编程基础。教程带你了解基本语法知识,以及如何持续进行学习。要知道,Python虽然上手容易,但真正掌握仍旧需要大量时间和练习。教程包含以下章节,学习需登录上方第二个连接:
- 01 Introduction(简介)
- 02 Type System(类型)
- 03 Flow Control(流控制)
- 04 Data Structures(数据结构)
- 05 Functions(函数)
- 06 Object Oriented Programming(面向对象编程)
- 07 Error Handling(错误处理)
- 08 Packages(包)
- 09 Projects(项目)
数据&资源
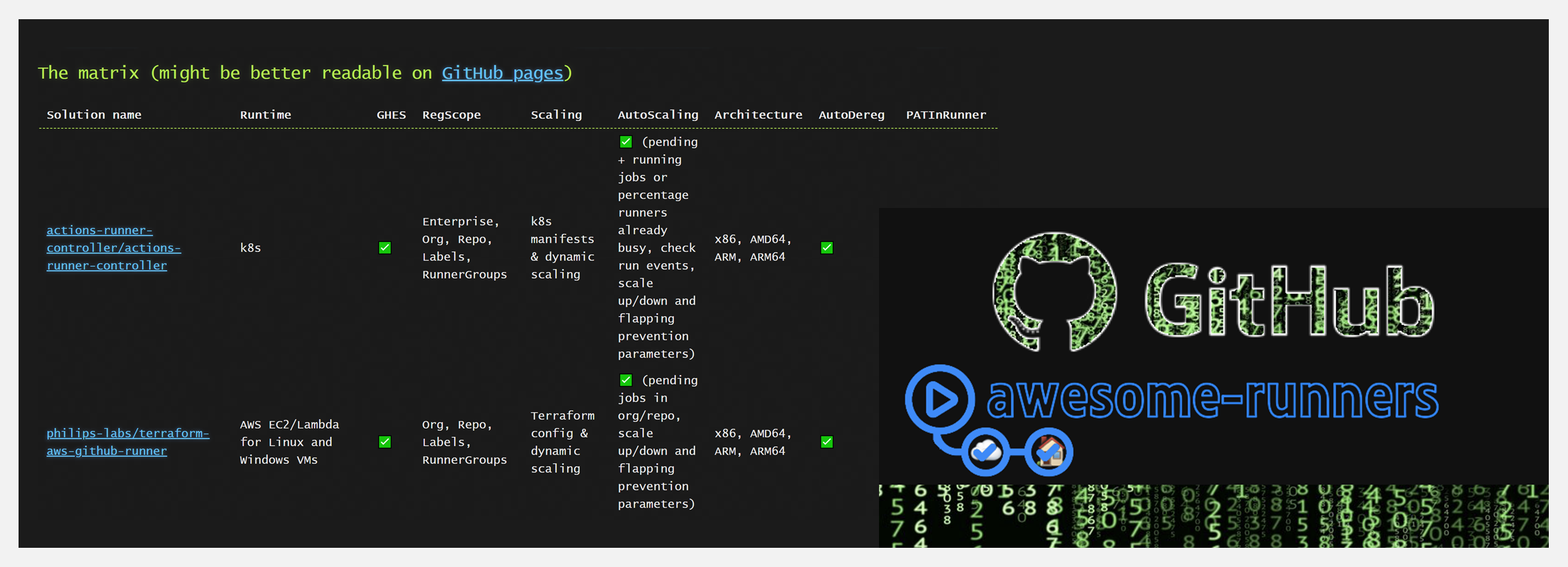
🔥 『Awesome Runners』GitHub Action 本地运行引擎资源列表
https://github.com/jonico/awesome-runners
通过各种标准,对 GitHub Actions 自托管引擎解决方案进行比较。比较类别包括:
- Runtime(运行时间)
- GHES(GitHub Enterprise Server)
- RegScope(注册范围)
- Scaling(缩放)
- Architecture(架构/支持的操作系统)
- Dereg(Deregistration/自动引擎注销)
- PATInRunner(引擎需要个人访问权限或 OAuth token)
- CleanUp(构建后自动清理)
- Privileged(运行或安装解决方案所需的任何特殊权限)
- Exposed(GitHub 需要通过网络挂钩访问运行器解决方案的部分内容)
- AllInOne(安装在自托管运行器中的软件)
- Contributors(解决方案的贡献者数量)
- SelfService(最终用户能够设置新的引擎规模集)
- IdleCosts(即使没有作业正在运行也会产生的成本)
🔥 『Awesome Container Tinkering』用于修补容器的工具列表
https://github.com/iximiuz/awesome-container-tinkeringome-container-tinkering
这是作者多年积累的几十个容器相关项目的链接,对于熟悉Docker 的读者来说,这是一个宝藏!每个人都能在这里找到有用的资料——runtimes、库、CLI,本地/远程运行容器的解决方案,用于检查/编辑/移动图像的辅助工具,以及相关深入报道和视频资源等。当前资源的类别列表包括:
- Container runtimes(容器运行时)
- Image builders, viewers, editors(图像构建者、查看者、编辑者)
- Development environments(开发环境)
- Container networking tools(容器网络工具)
- Interesting GitHub organizations(有趣的GitHub组织)
- Container Standards and Specifications(容器标准和规范)

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.09.30 『计算机视觉』 Mind Reader: Reconstructing complex images from brain activities
- 2022.09.30 『蛋白结构预测』 ModelAngelo: Automated Model Building in Cryo-EM Maps
- 2022.10.03 『场景理解』 Uncertainty-Driven Active Vision for Implicit Scene Reconstruction
⚡ 论文:Mind Reader: Reconstructing complex images from brain activities
论文时间:30 Sep 2022
领域任务:计算机视觉
论文地址:https://arxiv.org/abs/2210.01769
代码实现:https://github.com/sklin93/mind-reader
论文作者:Sikun Lin, Thomas Sprague, Ambuj K Singh
论文简介:Instead of training models from scratch to find a latent space shared by the three modalities, we encode fMRI signals into this pre-aligned latent space./我们没有从头开始训练模型以找到三种模式共享的潜空间,而是将fMRI信号编码到这个预先对齐的潜空间。
论文摘要:了解大脑如何编码外部刺激以及如何从测量的大脑活动中解码这些刺激是神经科学中长期存在的挑战性问题。在本文中,我们重点讨论了从fMRI(功能性磁共振成像)信号中重建复杂的图像刺激的问题。与以往重建单一物体或简单形状的图像的工作不同,我们的工作旨在重建具有丰富语义的图像刺激,更接近于日常场景,并能揭示更多的视角。然而,fMRI数据集的数据稀缺性是将最先进的深度学习模型应用于这个问题的主要障碍。我们发现,与直接将大脑信号转化为图像相比,纳入一个额外的文本模式对重建问题是有益的。因此,我们的方法中涉及的模式是。(i) 体素级的fMRI信号,(ii) 触发大脑信号的观察图像,以及(iii) 图像的文本描述。为了进一步解决数据稀缺的问题,我们利用了在大规模数据集上预先训练的一致的视觉-语言潜在空间。我们不需要从头开始训练模型来寻找三种模式共享的潜空间,而是将fMRI信号编码到这个预先对齐的潜空间。然后,以这个空间的嵌入为条件,我们用生成模型重建图像。我们的管道所重建的图像兼顾了自然性和保真度:它们如照片般真实,并且很好地捕捉了地面真实图像的内容。


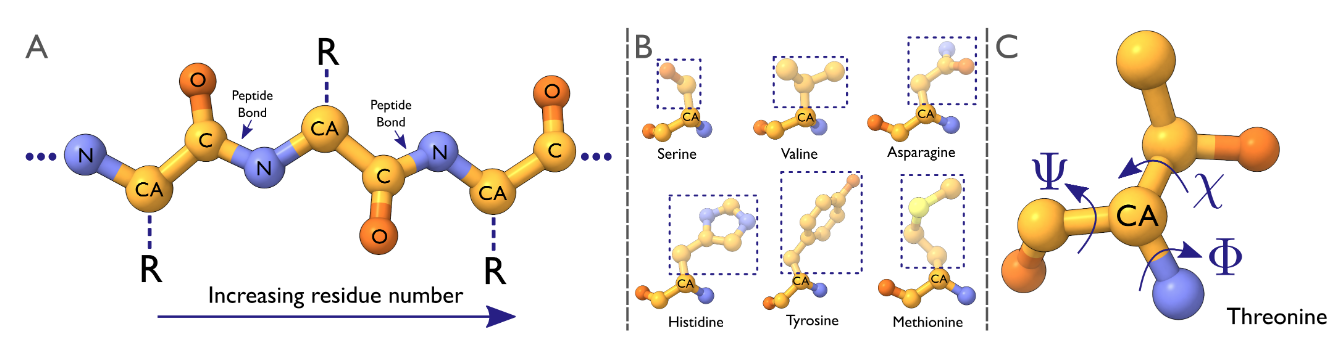
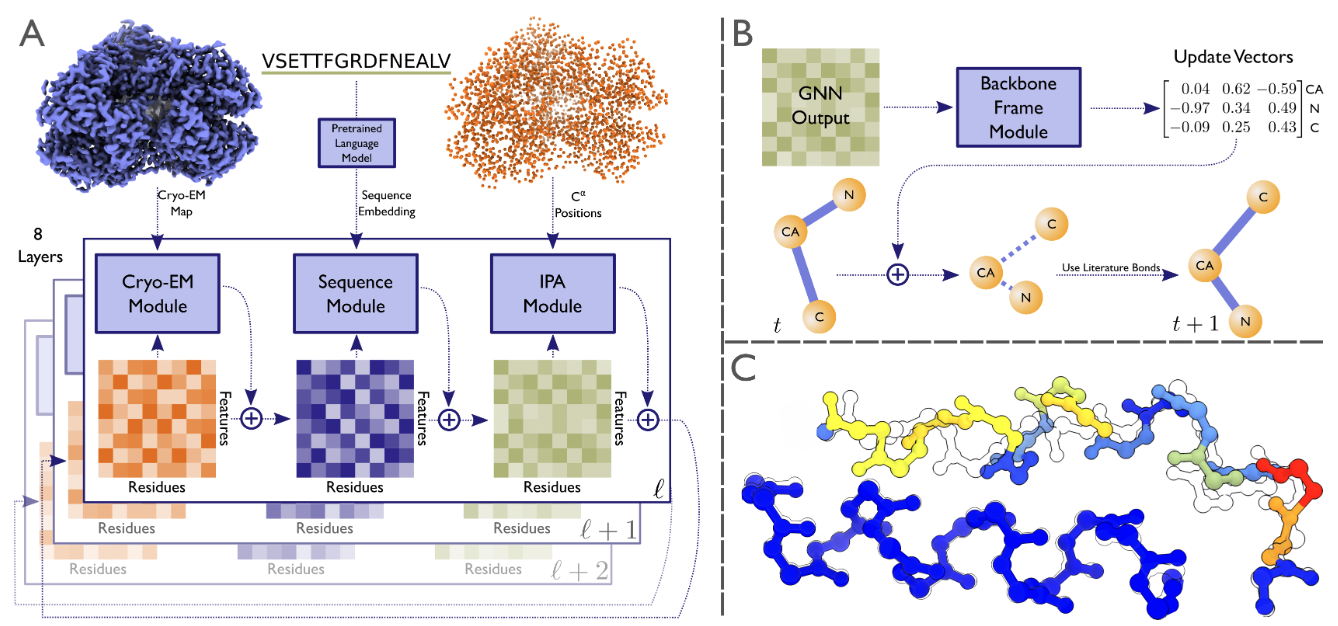
⚡ 论文:ModelAngelo: Automated Model Building in Cryo-EM Maps
论文时间:30 Sep 2022
领域任务:Protein Structure Prediction,蛋白结构预测
论文地址:https://arxiv.org/abs/2210.00006
代码实现:https://github.com/3dem/model-angelo
论文作者:Kiarash Jamali, Dari Kimanius, Sjors Scheres
论文简介:The GNN refines the geometry of the protein chain and classifies the amino acids for each of its nodes./GNN细化了蛋白质链的几何结构,并对其每个节点的氨基酸进行分类。
论文摘要:电子低温显微镜(cryo-EM)产生了包括蛋白质在内的生物大分子静电电位的三维(3D)地图。在足够的分辨率下,冷冻电镜图,加上一些关于成像分子的知识,可以进行新的原子建模。通常情况下,这是通过一个费力的手工过程完成的。最近机器学习在蛋白质结构预测方面的应用进展显示了这个过程自动化的潜力。从这些技术中得到启发,我们建立了ModelAngelo,用于自动建立低温电磁图中的蛋白质模型。ModelAngelo首先使用一个残余卷积神经网络(CNN)来初始化一个图形表示,其节点分配给图中蛋白质的单个氨基酸,边代表蛋白质链。然后用图形神经网络(GNN)来完善该图,该网络结合了冷冻电镜数据、氨基酸序列数据和关于蛋白质几何形状的先验知识。图神经网络完善了蛋白质链的几何形状,并对其每个节点的氨基酸进行分类。最终的图被用隐马尔可夫模型(HMM)搜索进行后处理,将每个蛋白质链映射到用户提供的序列文件中的条目。对28个测试案例的应用表明,ModelAngelo的性能优于最先进的技术,并接近于人工构建分辨率优于3.5A的低温电磁图。
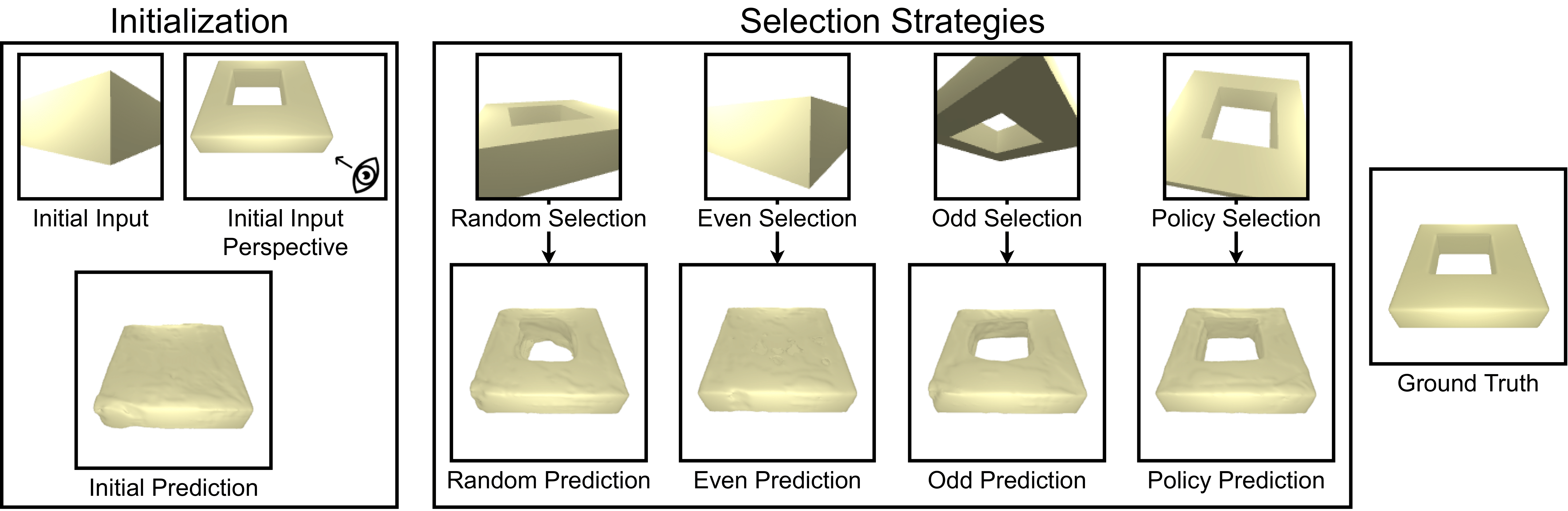
⚡ 论文:Uncertainty-Driven Active Vision for Implicit Scene Reconstruction
论文时间:3 Oct 2022
领域任务:Scene Understanding,场景理解
论文地址:https://arxiv.org/abs/2210.00978
代码实现:https://github.com/facebookresearch/uncertainty-driven-active-vision
论文作者:Edward J. Smith, Michal Drozdzal, Derek Nowrouzezahrai, David Meger, Adriana Romero-Soriano
论文简介:We evaluate our proposed approach on the ABC dataset and the in the wild CO3D dataset, and show that: (1) we are able to obtain high quality state-of-the-art occupancy reconstructions; (2) our perspective conditioned uncertainty definition is effective to drive improvements in next best view selection and outperforms strong baseline approaches; and (3) we can further improve shape understanding by performing a gradient-based search on the view selection candidates./ 我们在ABC数据集和野外CO3D数据集上评估了我们提出的方法,并表明:(1)我们能够获得高质量的最先进的占位重建;(2)我们的视角条件不确定性定义能够有效地推动下一个最佳视图选择的改进,并优于强大的基线方法;(3)我们可以通过对视图选择候选人进行基于梯度的搜索来进一步提高形状理解。
论文摘要:多视图隐式场景重建方法由于能够表现复杂的场景细节而变得越来越流行。最近,人们一直致力于改善输入信息的表示,并减少获得高质量重建所需的视图数量。然而,也许令人惊讶的是,关于选择哪些视图以最大限度地提高场景理解的研究在很大程度上还没有被探索。我们提出了一种用于隐式场景重建的不确定性驱动的主动视觉方法,该方法利用体积渲染在整个场景中积累的占有率不确定性来选择要获取的下一个视图。为此,我们开发了一种基于占有率的重建方法,该方法使用二维或三维监督准确地表示场景。我们在ABC数据集和野外CO3D数据集上评估了我们提出的方法,并表明。(1)我们能够获得高质量的最先进的占有率重建;(2)我们的视角条件不确定性定义能够有效地推动下一个最佳视图选择的改进,并优于强大的基线方法;(3)我们可以通过对视图选择候选人进行基于梯度的搜索来进一步提高形状理解。总的来说,我们的结果强调了视图选择对隐性场景重建的重要性,使其成为一个有前途的途径来进一步探索。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。



















 7919
7919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}