







前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
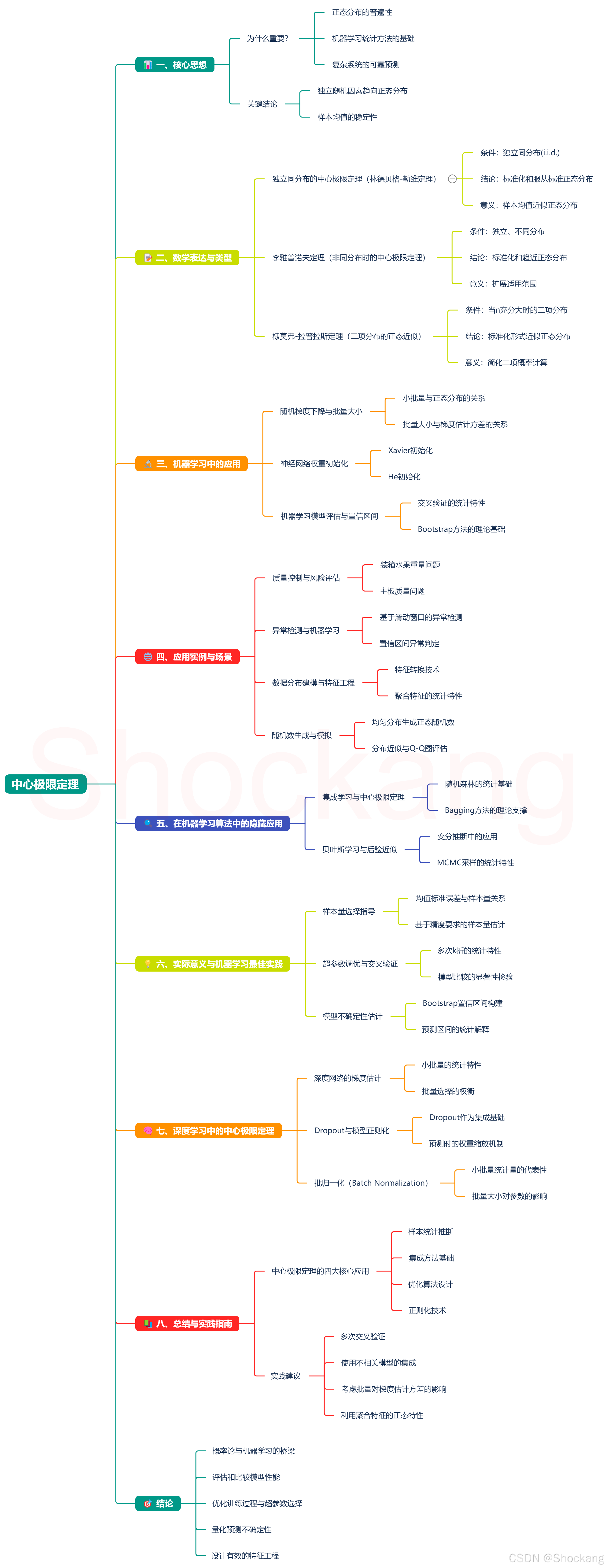
📊 一、核心思想
中心极限定理(Central Limit Theorem,CLT)是概率论中最重要的理论之一,也是机器学习中许多算法和统计方法的基石。它揭示了一个令人惊叹的数学现象:
🌟 无论原始随机变量的分布形态如何,只要满足一定条件,大量独立随机变量之和(或均值)经过标准化后,其分布将趋近于标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。
为什么重要?
- 🔗 解释了为何正态分布在自然界和数据科学中如此普遍
- 🧠 为机器学习中的众多统计方法提供了理论基础
- 🛠️ 使我们能够对复杂系统做出可靠预测
关键结论:
- 多个独立随机因素的综合效应趋向正态分布
- 样本均值的分布具有稳定性,便于统计推断和机器学习模型评估
📝 二、数学表达与类型
中心极限定理有几种重要形式,每种形式适用于不同的场景:
1️⃣ 独立同分布的中心极限定理(林德贝格-勒维定理)
- 条件:随机变量 X 1 , X 2 , … , X n X_1, X_2, \ldots, X_n X1,X2,…,Xn 独立同分布(i.i.d.),且具有有限的均值 μ \mu μ 和方差 σ 2 \sigma^2 σ2。
- 结论:当
n
→
∞
n \to \infty
n→∞,标准化后的和服从标准正态分布:
∑ k = 1 n X k − n μ σ n → d N ( 0 , 1 ) \frac{\sum_{k=1}^n X_k - n\mu}{\sigma \sqrt{n}} \overset{d}{\to} N(0,1) σn∑k=1nXk−nμ→dN(0,1) - 意义:样本均值 X ˉ = 1 n ∑ X k \bar{X} = \frac{1}{n} \sum X_k Xˉ=n1∑Xk 的分布近似为 N ( μ , σ 2 / n ) N(\mu, \sigma^2/n) N(μ,σ2/n)。
2️⃣ 李雅普诺夫定理(非同分布时的中心极限定理)
- 条件:随机变量独立但允许不同分布,若存在 δ > 0 \delta > 0 δ>0,使得 lim n → ∞ 1 B n 2 + δ ∑ k = 1 n E ∣ X k − μ k ∣ 2 + δ = 0 \lim_{n \to \infty} \frac{1}{B_n^{2+\delta}} \sum_{k=1}^n E|X_k - \mu_k|^{2+\delta} = 0 limn→∞Bn2+δ1∑k=1nE∣Xk−μk∣2+δ=0,其中 B n 2 = ∑ k = 1 n σ k 2 B_n^2 = \sum_{k=1}^n \sigma_k^2 Bn2=∑k=1nσk2。
- 结论:标准化和仍趋近正态分布:
∑ k = 1 n ( X k − μ k ) B n → d N ( 0 , 1 ) \frac{\sum_{k=1}^n (X_k - \mu_k)}{B_n} \overset{d}{\to} N(0,1) Bn∑k=1n(Xk−μk)→dN(0,1) - 意义:即使随机变量不同分布,只要满足方差增长与控制条件,其和仍可近似为正态分布。
3️⃣ 棣莫弗-拉普拉斯定理(二项分布的正态近似)
- 条件: X ∼ Binomial ( n , p ) X \sim \text{Binomial}(n, p) X∼Binomial(n,p),当 n n n 充分大时。
- 结论:二项分布的标准化形式近似服从标准正态分布:
X − n p n p ( 1 − p ) → d N ( 0 , 1 ) \frac{X - np}{\sqrt{np(1-p)}} \overset{d}{\to} N(0,1) np(1−p)X−np→dN(0,1) - 意义:解决二项分布概率计算的复杂性,通过正态分布近似简化。
🔬 三、机器学习中的应用
🧪 1. 随机梯度下降与批量大小
在机器学习中,随机梯度下降(SGD)的批量大小选择与中心极限定理密切相关:
- 小批量梯度: 当批量大小增加时,梯度估计的方差减小,分布更接近正态
- 批量平衡: 根据中心极限定理,批量大小为 n n n 时,梯度估计的标准误差约为 σ / n \sigma/\sqrt{n} σ/n
# 批量梯度下降与中心极限定理的关系示例
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 模拟不同批量大小的梯度估计
def gradient_estimate(batch_size, n_experiments=1000):
# 假设真实梯度为1,梯度噪声服从均值0,方差1的分布
gradient_samples = []
for _ in range(n_experiments):
batch_gradients = 1 + np.random.randn(batch_size) # 真实梯度+噪声
batch_mean = np.mean(batch_gradients)
gradient_samples.append(batch_mean)
return gradient_samples
# 不同批量大小的实验
batch_sizes = [1, 10, 30, 100]
plt.figure(figsize=(12, 8))
for i, size in enumerate(batch_sizes):
gradients = gradient_estimate(size)
plt.subplot(2, 2, i+1)
sns.histplot(gradients, kde=True)
plt.title(f'批量大小: {size}')
plt.axvline(x=1, color='r', linestyle='--', label='真实梯度')
plt.xlabel('梯度估计')
plt.ylabel('频率')
# 计算标准差并与理论值比较
empirical_std = np.std(gradients)
theoretical_std = 1/np.sqrt(size)
plt.annotate(f'实测标准差: {empirical_std:.4f}\n'
f'理论标准差: {theoretical_std:.4f}',
xy=(0.05, 0.85), xycoords='axes fraction')
plt.tight_layout()
plt.suptitle('中心极限定理在梯度下降中的应用', y=1.02, fontsize=16)
🤖 2. 神经网络权重初始化
中心极限定理解释了为什么合适的权重初始化对神经网络训练至关重要:
- Xavier初始化: 基于中心极限定理设计,确保每层输出近似正态分布
- He初始化: 考虑ReLU激活函数的影响,同样依赖中心极限定理原理
# 神经网络权重初始化与中心极限定理
def demonstrate_weight_initialization(n_neurons_prev=1000, n_neurons=1000, n_samples=1000):
# 标准正态分布初始化(不佳)
W_standard = np.random.randn(n_neurons_prev, n_neurons)
# Xavier初始化 - 适合Sigmoid/Tanh
W_xavier = np.random.randn(n_neurons_prev, n_neurons) * np.sqrt(1/n_neurons_prev)
# He初始化 - 适合ReLU
W_he = np.random.randn(n_neurons_prev, n_neurons) * np.sqrt(2/n_neurons_prev)
# 生成随机输入
X = np.random.randn(n_samples, n_neurons_prev)
# 计算各种初始化方式的输出
Z_standard = np.dot(X, W_standard)
Z_xavier = np.dot(X, W_xavier)
Z_he = np.dot(X, W_he)
# 可视化输出分布
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
sns.histplot(Z_standard[:, 0], kde=True)
plt.title(f'标准初始化\n方差: {np.var(Z_standard[:, 0]):.2f}')
plt.subplot(1, 3, 2)
sns.histplot(Z_xavier[:, 0], kde=True)
plt.title(f'Xavier初始化\n方差: {np.var(Z_xavier[:, 0]):.2f}')
plt.subplot(1, 3, 3)
sns.histplot(Z_he[:, 0], kde=True)
plt.title(f'He初始化\n方差: {np.var(Z_he[:, 0]):.2f}')
plt.tight_layout()
plt.suptitle('不同初始化方法下神经元输出的分布', y=1.05, fontsize=16)
📈 3. 机器学习模型评估与置信区间
中心极限定理允许我们构建模型性能的置信区间:
- 交叉验证: 多次交叉验证的性能分数近似服从正态分布
- Bootstrap方法: 通过重采样评估模型稳定性,依赖中心极限定理
# 模型评估中的置信区间估计
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
from scipy import stats
def model_confidence_interval(model, X, y, n_splits=10, confidence=0.95):
"""基于中心极限定理计算模型性能的置信区间"""
kf = KFold(n_splits=n_splits)
scores = []
for train_idx, test_idx in kf.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 计算均值和标准差
mean_score = np.mean(scores)
std_score = np.std(scores, ddof=1)
# 计算置信区间
n = len(scores)
margin = std_score / np.sqrt(n) * stats.t.ppf((1 + confidence) / 2, n - 1)
return mean_score, (mean_score - margin, mean_score + margin)
🌐 四、应用实例与场景
1️⃣ 质量控制与风险评估
-
例1(装箱水果重量):
某水果箱由 100 个独立水果组成,每个水果重量均值 1000g,标准差 100g。利用定理:
P ( ∑ X k > 101000 ) ≈ P ( Z > 101000 − 100000 100 100 ) = P ( Z > 1 ) = 0.1587 P\left(\sum X_k > 101000\right) \approx P\left(Z > \frac{101000-100000}{100 \sqrt{100}}\right) = P(Z > 1) = 0.1587 P(∑Xk>101000)≈P(Z>100100101000−100000)=P(Z>1)=0.1587 -
例2(主板质量问题):
每 100 块主板中问题数的均值 μ = 1 \mu = 1 μ=1,标准差 σ = 0.99 \sigma = \sqrt{0.99} σ=0.99。利用正态近似计算问题数≤5 的概率:
P ( X ≤ 5 ) ≈ Φ ( 5 − 1 0.99 ) ≈ Φ ( 4 ) ≈ 1 P(X \leq5) \approx \Phi\left(\frac{5-1}{\sqrt{0.99}}\right) \approx \Phi(4) \approx 1 P(X≤5)≈Φ(0.995−1)≈Φ(4)≈1
2️⃣ 异常检测与机器学习
在机器学习中,中心极限定理支撑了许多异常检测算法:
# 基于中心极限定理的简单异常检测示例
def anomaly_detection_with_clt(data, window_size=30, threshold=3):
"""使用滑动窗口均值和中心极限定理检测异常"""
anomalies = []
means = []
upper_bounds = []
lower_bounds = []
for i in range(len(data) - window_size + 1):
window = data[i:i+window_size]
window_mean = np.mean(window)
window_std = np.std(window)
# 根据中心极限定理,均值的标准误差
std_error = window_std / np.sqrt(window_size)
# 设置阈值边界(基于正态分布的性质)
upper_bound = window_mean + threshold * std_error
lower_bound = window_mean - threshold * std_error
# 检查当前点是否为异常
current_point = data[i+window_size-1] if i+window_size < len(data) else data[-1]
if current_point > upper_bound or current_point < lower_bound:
anomalies.append(i+window_size-1)
means.append(window_mean)
upper_bounds.append(upper_bound)
lower_bounds.append(lower_bound)
return anomalies, means, upper_bounds, lower_bounds
# 使用示例
np.random.seed(42)
# 生成正常数据加上一些异常值
normal_data = np.random.normal(loc=10, scale=2, size=200)
# 添加一些异常值
normal_data[50] = 25
normal_data[100] = 2
normal_data[150] = 30
anomalies, means, upper_bounds, lower_bounds = anomaly_detection_with_clt(normal_data)
# 可视化结果
plt.figure(figsize=(12, 6))
plt.plot(normal_data, label='原始数据')
plt.plot(range(len(means)), means, 'g--', label='滑动平均')
plt.plot(range(len(upper_bounds)), upper_bounds, 'r--', label='上边界')
plt.plot(range(len(lower_bounds)), lower_bounds, 'r--', label='下边界')
plt.scatter(anomalies, [normal_data[i] for i in anomalies], color='red', s=100, marker='x', label='检测到的异常')
plt.legend()
plt.title('基于中心极限定理的异常检测')
plt.xlabel('样本索引')
plt.ylabel('数值')
3️⃣ 数据分布建模与特征工程
- 特征转换: 利用中心极限定理,通过求和或平均可以将非正态特征转化为近似正态分布
- 聚合特征: 当创建聚合特征(如用户平均购买金额)时,大样本下这些特征更可能呈正态分布
# 特征转换示例:将偏态分布转换为近似正态分布
def feature_normalization_demo():
# 生成一个偏态分布(指数分布)
skewed_data = np.random.exponential(scale=2.0, size=10000)
# 创建不同大小的子样本均值
sample_sizes = [1, 2, 5, 10, 30, 50]
transformed_data = []
for size in sample_sizes:
# 确保数据点数能被sample_size整除
n_full_samples = len(skewed_data) // size * size
reshaped_data = skewed_data[:n_full_samples].reshape(-1, size)
# 计算每组的平均值
means = np.mean(reshaped_data, axis=1)
transformed_data.append(means)
# 可视化转换效果
fig, axs = plt.subplots(2, 3, figsize=(15, 10))
axs = axs.flatten()
for i, (size, data) in enumerate(zip(sample_sizes, transformed_data)):
sns.histplot(data, kde=True, ax=axs[i])
axs[i].set_title(f'样本大小 = {size}')
# 计算偏度
skewness = stats.skew(data)
axs[i].annotate(f'偏度: {skewness:.4f}', xy=(0.05, 0.9), xycoords='axes fraction')
plt.tight_layout()
plt.suptitle('中心极限定理在特征工程中的应用: 均值聚合降低偏度', y=1.02, fontsize=16)
4️⃣ 随机数生成与模拟
- 生成正态分布随机数: 根据中心极限定理,叠加多个均匀分布变量的均值可近似生成标准正态随机数:
Z = ∑ i = 1 12 U i − 6 1 ≈ N ( 0 , 1 ) ( U i ∼ U ( 0 , 1 ) ) Z = \frac{\sum_{i=1}^{12} U_i - 6}{\sqrt{1}} \approx N(0,1) \quad (U_i \sim U(0,1)) Z=1∑i=112Ui−6≈N(0,1)(Ui∼U(0,1))
# 使用中心极限定理生成近似正态分布随机数
def clt_random_normal(n_samples=10000, n_uniforms=12):
# 生成多个均匀分布随机数
uniform_samples = np.random.uniform(0, 1, (n_samples, n_uniforms))
# 求和并减去均值调整
normal_approx = np.sum(uniform_samples, axis=1) - n_uniforms/2
# 根据方差进行标准化 (Var(U(0,1)) = 1/12)
normal_approx = normal_approx / np.sqrt(n_uniforms/12)
# 比较与真正的正态分布
true_normal = np.random.normal(0, 1, n_samples)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot(normal_approx, kde=True, stat="density", label="CLT近似")
x = np.linspace(-4, 4, 100)
plt.plot(x, stats.norm.pdf(x, 0, 1), 'r-', label="理论正态分布")
plt.title(f'使用{n_uniforms}个均匀分布的和生成的正态分布')
plt.legend()
plt.subplot(1, 2, 2)
sns.scatterplot(x=np.sort(true_normal), y=np.sort(normal_approx))
plt.plot([-4, 4], [-4, 4], 'r--')
plt.title('Q-Q图: CLT近似 vs 真实正态分布')
plt.xlabel('理论分位数')
plt.ylabel('样本分位数')
plt.tight_layout()
🔍 五、在机器学习算法中的隐藏应用
1️⃣ 集成学习与中心极限定理
中心极限定理解释了为什么集成方法(如随机森林、Boosting)如此有效:
- 🌲 随机森林: 多个决策树的预测结果平均后变得更稳定,分布更接近正态
- 🔄 Bagging方法: 通过bootstrap采样训练多个模型,利用中心极限定理降低方差
# 集成学习中的中心极限定理效应
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import make_regression
def ensemble_clt_effect():
# 生成回归数据集
X, y = make_regression(n_samples=1000, n_features=20, noise=0.5, random_state=42)
# 分割训练测试集
X_train, X_test = X[:800], X[800:]
y_train, y_test = y[:800], y[800:]
# 单个决策树的多次预测(不同随机状态)
tree_preds = []
for i in range(100):
tree = DecisionTreeRegressor(max_depth=5, random_state=i)
tree.fit(X_train, y_train)
tree_preds.append(tree.predict(X_test))
# 随机森林的预测(一次训练,内部集成)
rf = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
rf.fit(X_train, y_train)
# 单个树预测的平均
avg_tree_pred = np.mean(tree_preds, axis=0)
# 随机森林预测
rf_pred = rf.predict(X_test)
# 可视化分布
plt.figure(figsize=(15, 5))
# 绘制单个树的预测分布(针对第一个测试样本)
plt.subplot(1, 3, 1)
sns.histplot([preds[0] for preds in tree_preds], kde=True)
plt.axvline(x=y_test[0], color='r', linestyle='--', label='真实值')
plt.title('单个树对同一样本的预测分布')
plt.legend()
# 比较单个树与平均预测的误差分布
plt.subplot(1, 3, 2)
tree_errors = [np.mean((pred - y_test)**2) for pred in tree_preds]
avg_error = np.mean((avg_tree_pred - y_test)**2)
rf_error = np.mean((rf_pred - y_test)**2)
sns.histplot(tree_errors, kde=True)
plt.axvline(x=avg_error, color='g', linestyle='--', label=f'平均预测MSE: {avg_error:.2f}')
plt.axvline(x=rf_error, color='r', linestyle='--', label=f'随机森林MSE: {rf_error:.2f}')
plt.title('单个树的MSE分布')
plt.legend()
# 比较预测误差散点图
plt.subplot(1, 3, 3)
plt.scatter(y_test, tree_preds[0], alpha=0.5, label='单个树')
plt.scatter(y_test, avg_tree_pred, alpha=0.8, label='平均预测')
plt.scatter(y_test, rf_pred, alpha=0.8, label='随机森林')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'k--')
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.title('预测对比')
plt.legend()
plt.tight_layout()
plt.suptitle('集成学习中的中心极限定理效应', y=1.02, fontsize=16)
2️⃣ 贝叶斯学习与后验近似
- 🧩 变分推断: 在复杂贝叶斯模型中,常利用中心极限定理近似后验分布
- 🔄 MCMC采样: 马尔科夫链蒙特卡洛方法产生的样本均值渐近正态,依赖中心极限定理
💡 六、实际意义与机器学习最佳实践
1️⃣ 样本量选择指导
中心极限定理为机器学习中的样本量选择提供了理论依据:
- 📏 均值标准误差 = σ / n \sigma/\sqrt{n} σ/n,说明样本量增加 4 4 4 倍,标准误差减半
- 🎯 根据所需精度估计最小样本量: n ≥ ( z α / 2 ⋅ σ E ) 2 n \geq \left(\frac{z_{\alpha/2} \cdot \sigma}{E}\right)^2 n≥(Ezα/2⋅σ)2
2️⃣ 超参数调优与交叉验证
利用中心极限定理指导交叉验证过程:
- 🔄 多次k折交叉验证结果近似正态分布,可以构建置信区间
- 📊 当比较不同模型性能时,可使用t检验评估差异显著性
# 使用中心极限定理进行模型比较
def compare_models_with_clt(model1, model2, X, y, n_iterations=30, test_size=0.2):
"""
使用多次训练测试分割来比较两个模型性能,并应用t检验
"""
model1_scores = []
model2_scores = []
for i in range(n_iterations):
# 创建不同的训练测试分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size)
# 训练并评估模型1
model1.fit(X_train, y_train)
score1 = model1.score(X_test, y_test)
model1_scores.append(score1)
# 训练并评估模型2
model2.fit(X_train, y_train)
score2 = model2.score(X_test, y_test)
model2_scores.append(score2)
# 计算平均分数和标准差
model1_mean = np.mean(model1_scores)
model2_mean = np.mean(model2_scores)
model1_std = np.std(model1_scores, ddof=1)
model2_std = np.std(model2_scores, ddof=1)
# 执行配对t检验
t_stat, p_value = stats.ttest_rel(model1_scores, model2_scores)
# 可视化结果
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
sns.histplot(model1_scores, label=f'模型1: μ={model1_mean:.4f}, σ={model1_std:.4f}', kde=True)
sns.histplot(model2_scores, label=f'模型2: μ={model2_mean:.4f}, σ={model2_std:.4f}', kde=True)
plt.title('模型性能分布比较')
plt.legend()
plt.subplot(1, 2, 2)
diff_scores = np.array(model1_scores) - np.array(model2_scores)
sns.histplot(diff_scores, kde=True)
plt.axvline(x=0, color='r', linestyle='--')
plt.title(f'性能差异分布\np值={p_value:.4f}')
plt.tight_layout()
return model1_mean, model2_mean, p_value
3️⃣ 模型不确定性估计
中心极限定理为机器学习模型的不确定性量化提供了理论基础:
- 🎲 Bootstrap方法: 通过重采样估计模型参数的置信区间
- 📊 预测区间构建: 结合点预测和方差估计构建预测区间
# 使用Bootstrap进行模型不确定性估计
def bootstrap_uncertainty(model, X, y, n_bootstrap=1000, test_idx=None):
"""
使用bootstrap方法估计模型预测的不确定性
"""
n_samples = len(X)
if test_idx is None:
# 随机选择一个测试点
test_idx = np.random.choice(n_samples)
test_point = X[test_idx:test_idx+1]
test_true = y[test_idx]
# 保存bootstrap预测结果
bootstrap_predictions = []
for i in range(n_bootstrap):
# 带放回采样
bootstrap_idx = np.random.choice(np.delete(np.arange(n_samples), test_idx),
size=n_samples-1, replace=True)
X_boot = X[bootstrap_idx]
y_boot = y[bootstrap_idx]
# 训练模型
model.fit(X_boot, y_boot)
# 预测测试点
pred = model.predict(test_point)[0]
bootstrap_predictions.append(pred)
# 计算预测统计量
mean_pred = np.mean(bootstrap_predictions)
std_pred = np.std(bootstrap_predictions)
# 构建95%置信区间
ci_lower = np.percentile(bootstrap_predictions, 2.5)
ci_upper = np.percentile(bootstrap_predictions, 97.5)
# 可视化结果
plt.figure(figsize=(10, 6))
sns.histplot(bootstrap_predictions, kde=True)
plt.axvline(x=test_true, color='r', linestyle='--', label=f'真实值: {test_true:.2f}')
plt.axvline(x=mean_pred, color='g', linestyle='-', label=f'平均预测值: {mean_pred:.2f}')
plt.axvline(x=ci_lower, color='b', linestyle=':', label=f'95%置信区间下限: {ci_lower:.2f}')
plt.axvline(x=ci_upper, color='b', linestyle=':', label=f'95%置信区间上限: {ci_upper:.2f}')
plt.title('模型预测的bootstrap分布')
plt.xlabel('预测值')
plt.ylabel('频率')
plt.legend()
return mean_pred, std_pred, (ci_lower, ci_upper)
🧠 七、深度学习中的中心极限定理
1️⃣ 深度网络的梯度估计
中心极限定理解释了为什么小批量梯度下降在深度学习中效果良好:
- 🔢 小批量梯度是整体梯度的无偏估计,其误差近似正态分布
- ⚡ 批量大小的选择权衡:更大的批量提供更精确的梯度估计(标准差减小),但计算成本增加
# 批量大小与梯度估计精度关系可视化
def visualize_batch_size_impact():
batch_sizes = [1, 4, 16, 64, 256, 1024]
gradient_std_errors = [1/np.sqrt(b) for b in batch_sizes] # 根据CLT,标准误差与批大小平方根成反比
plt.figure(figsize=(10, 6))
plt.plot(batch_sizes, gradient_std_errors, 'o-')
plt.xscale('log2')
plt.yscale('log2')
plt.xlabel('批量大小(对数刻度)')
plt.ylabel('梯度标准误差(对数刻度)')
plt.title('中心极限定理预测的批量大小与梯度估计精度关系')
# 添加批次大小翻倍时的效应标注
for i in range(len(batch_sizes)-1):
plt.annotate(f'精度提升: {gradient_std_errors[i]/gradient_std_errors[i+1]:.2f}倍',
xy=((batch_sizes[i]+batch_sizes[i+1])/2,
(gradient_std_errors[i]+gradient_std_errors[i+1])/2),
xytext=(0, 15),
textcoords='offset points',
arrowprops=dict(arrowstyle='->'))
plt.grid(True, which='both', linestyle='--', alpha=0.7)
2️⃣ Dropout与模型正则化
中心极限定理解释了Dropout为何能有效防止过拟合:
- 🎭 Dropout相当于训练多个不同子网络的集成
- 🔄 预测时,集成多个子网络的输出(通过权重缩放)利用了中心极限定理的稳定效应
3️⃣ 批归一化(Batch Normalization)
- 📊 批归一化依赖于小批量统计量近似整体统计量的性质
- 🧮 当批量足够大时,批归一化估计的均值和方差更接近真实分布参数
📚 八、总结与实践指南
🌟 中心极限定理在机器学习中的四大核心应用:
- 样本统计推断:构建置信区间、假设检验和模型评估
- 集成方法基础:解释为何多个弱学习器的组合效果优于单个强学习器
- 优化算法设计:小批量梯度下降、Adam等优化器参数更新策略
- 正则化技术:Dropout、批归一化等技术的理论基础
📝 实践建议:
- ✅ 模型评估时:进行多次交叉验证,构建性能指标的置信区间
- ✅ 集成学习中:尽量使用不相关的模型,以最大化中心极限定理带来的稳定性
- ✅ 超参数选择时:考虑批量大小对梯度估计方差的影响
- ✅ 特征工程中:利用聚合特征近似正态的特性,改善模型表现
# 中心极限定理在特征工程中的实践
def feature_engineering_with_clt(df, categorical_col, target_col, min_samples=30):
"""
使用分组统计量作为特征,并考虑样本量的影响
"""
# 计算每个类别的目标均值
category_means = df.groupby(categorical_col)[target_col].agg(['mean', 'count']).reset_index()
# 应用中心极限定理的影响:样本量小的类别均值不可靠
# 使用全局均值作为先验,样本量作为权重进行平滑
global_mean = df[target_col].mean()
# 贝叶斯平滑后的特征(考虑样本量)
def smooth_mean(row):
count = row['count']
raw_mean = row['mean']
# 平滑系数,随样本量增加而减小
alpha = min_samples / (min_samples + count)
return alpha * global_mean + (1 - alpha) * raw_mean
category_means['smoothed_mean'] = category_means.apply(smooth_mean, axis=1)
# 可视化原始均值vs平滑均值
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(category_means['count'], category_means['mean'], alpha=0.7)
plt.axhline(y=global_mean, color='r', linestyle='--', label='全局均值')
plt.xscale('log')
plt.xlabel('样本量(对数刻度)')
plt.ylabel('原始类别均值')
plt.title('样本量与类别均值关系')
plt.legend()
plt.subplot(1, 2, 2)
plt.scatter(category_means['count'], category_means['smoothed_mean'], alpha=0.7)
plt.axhline(y=global_mean, color='r', linestyle='--', label='全局均值')
plt.xscale('log')
plt.xlabel('样本量(对数刻度)')
plt.ylabel('平滑后的类别均值')
plt.title('应用中心极限定理的均值平滑效果')
plt.legend()
plt.tight_layout()
return category_means
🎯 结论
中心极限定理是连接概率论与机器学习实践的桥梁,它不仅解释了为什么某些算法有效,还为算法设计和模型评估提供了理论基础。作为机器学习从业者,深入理解中心极限定理能够:
- 🧐 更科学地评估和比较模型性能
- 🛠️ 优化模型训练过程与超参数选择
- 🔍 更准确地量化预测不确定性
- 💡 设计更有效的特征工程策略
正如统计学家 George Box 所言:“所有模型都是错的,但有些是有用的”—中心极限定理帮助我们理解为什么即使是不完美的模型,在适当条件下也能获得令人满意的结果。在数据科学的旅程中,中心极限定理将一直是我们最可靠的指南之一。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









