





论文代码:https://github.com/mylbuaa/MGCA-RAFFNet
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. Multi-Template Parcellation
2.3.2. Multi-Graph Cross-Attention Network
2.3.3. Region-Aware Feature Fusion Network
2.4.1. Materials and Preprocessing
2.4.2. Experimental Settings and Evaluation
2.5.2. Computational Complexity
2.5.3. Comparison With the State-of-the-Art Methods
2.5.4. Impact of the Hyperparameters of MGCAN
2.5.5. Impact of Hyperparameters Setting
2.5.6. Most Discriminative Brain Regions
2.5.7. Advantages and Limitations
1. 心得
(1)学校网怎么连着炸几天了
(2)这作者数学表达能力真的应该用魔丸来形容(),有一种混沌邪恶的感觉
(3)所有的多模板fMRI都长得好像...
2. 论文逐段精读
2.1. Abstract
①Limitations in current works: single template
2.2. Introduction
①哈哈哈,大脑疾病“with devastating efects not only on the individual but also the society”好可爱
②Existing templet fusion works failed to capture the deep relationship between templets
2.3. Methods
①Overall framework:
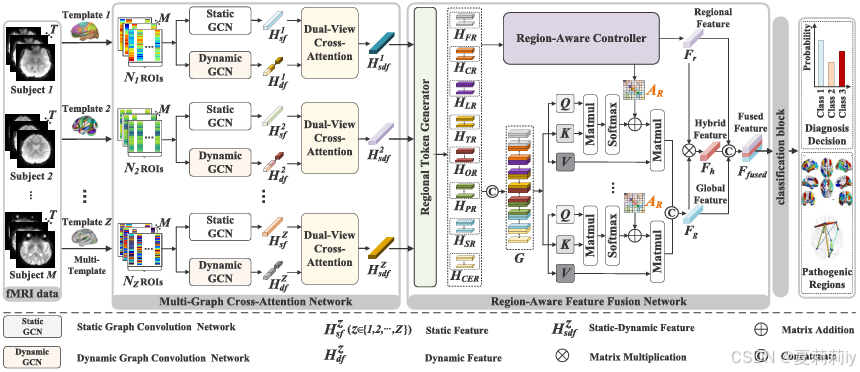
2.3.1. Multi-Template Parcellation
①Atlas chosing: AAL (anatomical), BN (anatomical and connectivity) and Power (hierarchical)
2.3.2. Multi-Graph Cross-Attention Network
(1)MGCAN
○The schematic of MGCAN:
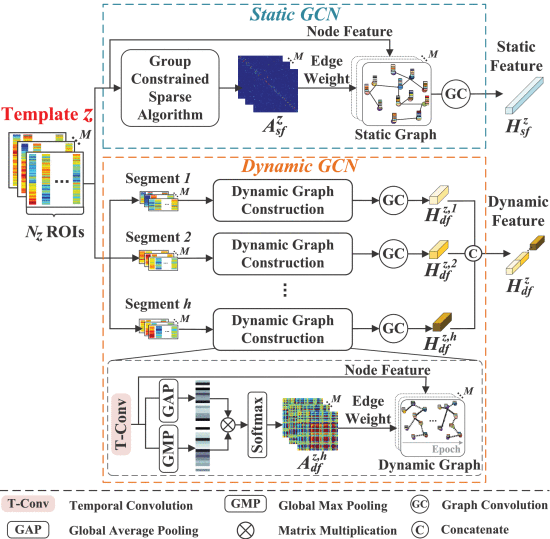
① denotes time series of the templet
, where
is the number of ROIs and
denotes time point
② denotes the time series of the
-th subject,
-th ROI and
denotes transpose operation(这里的定义好混乱...)
③ is the combination of current and previous time series of other ROIs:
where is the order of the time delay and it is set to 1 for fair comparison
④And
and is a residual term
④Then the equation can be:
where ,
(公式这么长,我感觉就是全连接的图神经网络?但是没有自循环,相当于一个节点把上个时间步(或者上个+上上个时间步)所有其他节点特征全部拿过来了)
⑤Removing spurious connections:
where is coefficient matrix set
⑥For time series matrix and its corresponding static adjacency matrix
, the GCN can be:
where denotes degree matrix,
denotes weight matrix,
is ELU(啊,魔改了的GCN吗)
⑦Sliding windows to get dynamic series with length of
. 然后对每个滑窗进行时间卷积Blabla看图吧那一块很明确了。最后的输出是:
(2)DVCA
①Schematic of dual-view cross-attention (DVCA):
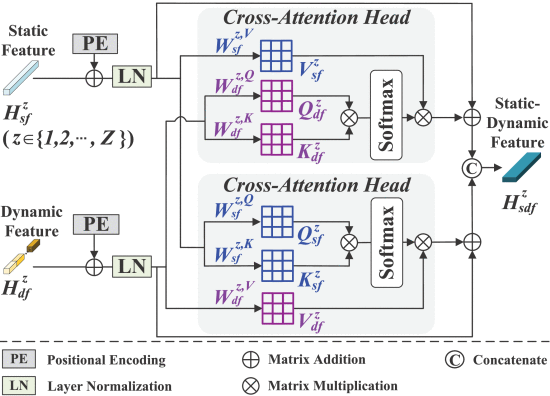
②Positional encoding:
where denotes absolute positional embedding of static and dynamic sequence
③后面的自己看图,已经很明确了
2.3.3. Region-Aware Feature Fusion Network
①Schematic of RAFFNet:
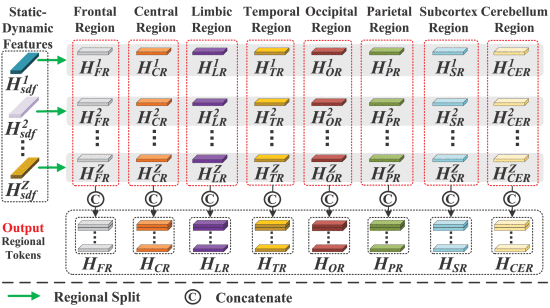
对于不同脑模板提取到的特征,把每个八个脑区的ROI都分出来拼在一起,可能形状不一样
②The schematic of region-aware controller:
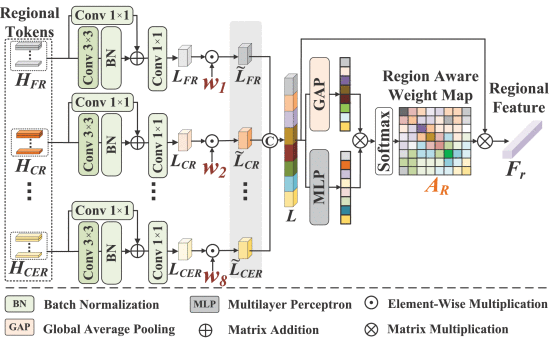
③The region aware attention is calculated by:
2.4. Experiments and Results
2.4.1. Materials and Preprocessing
①Dataset: ADNI-2 and ABIDE
2.4.2. Experimental Settings and Evaluation
①Batch size: 16
②Learning rate: 0.001 with Adam optimizer
③Cross validation: 10 fold
2.4.3. Overall Performance
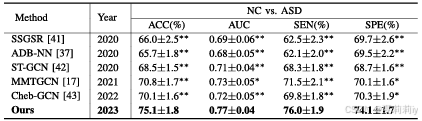
①Comparison performance on ADNI-2:

②Comparison performance on ABIDE I dataset:
2.5. Discussion
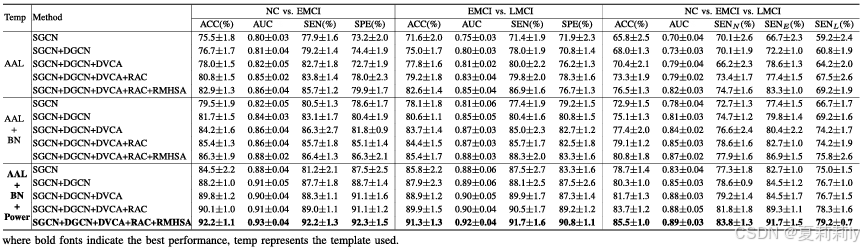
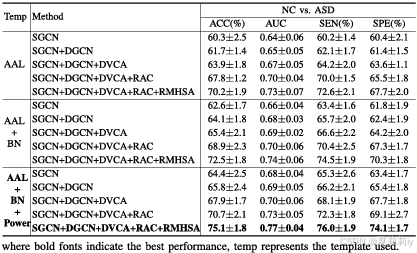
2.5.1. Ablation Study
①Module ablation on ADNI 2 and ABIDE I:
②t-SNE visualization on (a) AAL only, (b) AAL+BN, (c) AAL+BN+Power:

③Region aware weight map ablation:
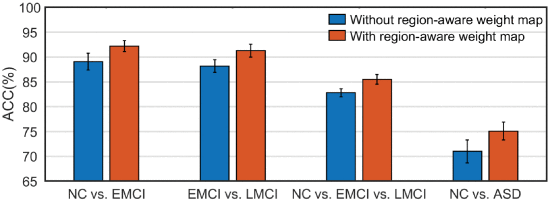
2.5.2. Computational Complexity
①Computational cost:
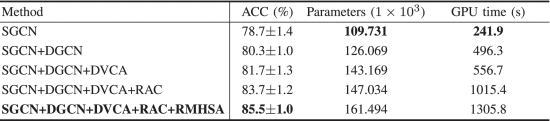
2.5.3. Comparison With the State-of-the-Art Methods
①Comparison table:
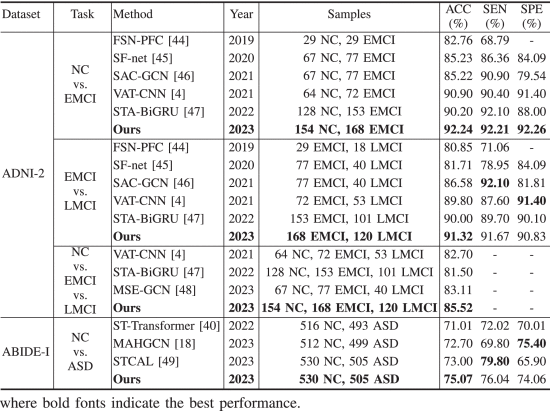
2.5.4. Impact of the Hyperparameters of MGCAN
①Influence of hyperparameters:
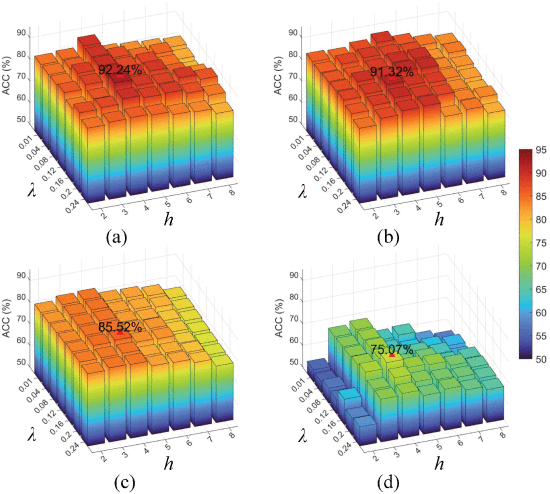
2.5.5. Impact of Hyperparameters Setting
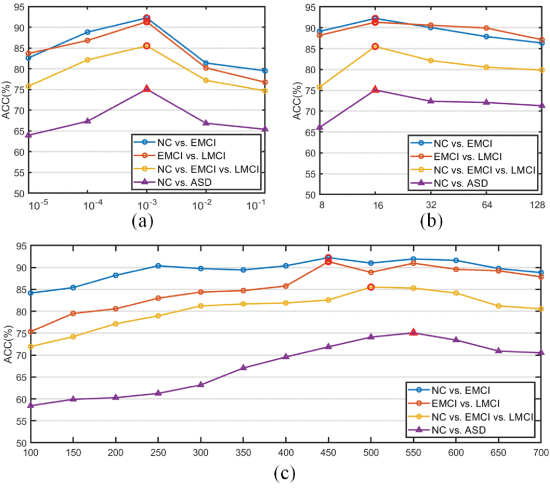
①Impact of (a) learning rate, (b) batch size, (c) epoch:
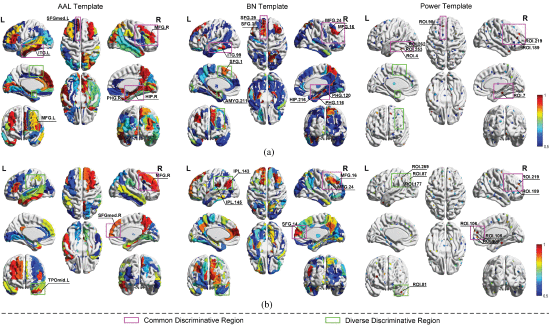
2.5.6. Most Discriminative Brain Regions
①Significant brain regions:
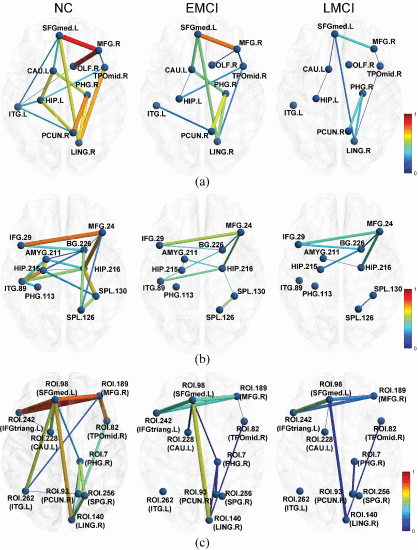
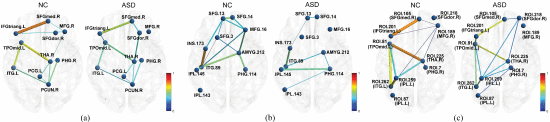
②Significant brain connectivities:
③Table:

2.5.7. Advantages and Limitations
①Limitations: robustness
2.6. Conclusion
~

















 260
260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









