 ClipCap图像字幕生成方法解析
ClipCap图像字幕生成方法解析






论文网址:[2111.09734] ClipCap: CLIP Prefix for Image Captioning
论文代码:GitHub - rmokady/CLIP_prefix_caption: Simple image captioning model
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.2. Language model fine-tuning
2.4.3. Mapping Network Architecture
1. 心得
(1)github维护的很好的样子,而且怎么感觉还有宣传,但论文还是没投出去吗?好可惜
(2)设计上确实很简单,但主旨就是为了快,感觉也不是不行
(3)⭐第一次见到把GPT前缀打印出来的!
2. 论文逐段精读
2.1. Abstract
①They apply CLIP feature as the prefix of text decoder
②They encourage simpler, faster and lighter
2.2. Introduction
①Captioning task:

②Overall framework:
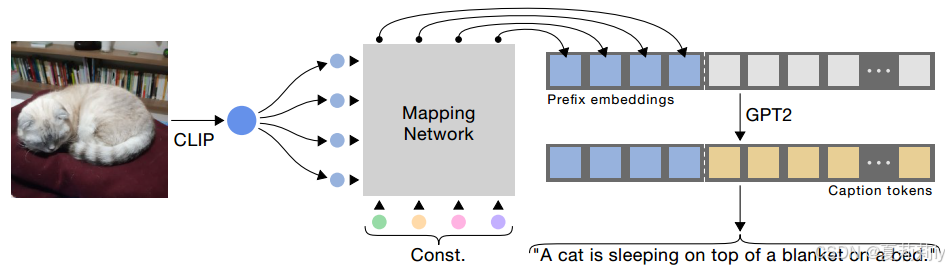
2.3. Related Works
①Introduced CLIP
②Pre trained models do not need to rely on other annotations
2.4. Method
① denotes image and caption pairs
②Training object:
where denotes tokens in caption,
denotes trainable parameter
③Autoregressive prediction goal:
2.4.1. Overview
①Language model: GPT-2
②Extracting image feature by CLIP and mapping network:
where has the same dimension as a word embedding
③Connect embedding and caption(是自回归得到的,是从1开始一个一个生成出来的,不是一开始就是一整句话):
④Cross entropy loss:
2.4.2. Language model fine-tuning
①微调很浪费时间所以作者觉得不微调了
2.4.3. Mapping Network Architecture
①They fed CLIP extracted feature and constants in mapping network
2.4.4. Inference
①For each token, the language model outputs probabilities for all vocabulary tokens, which are used to determine the next one by employing a greedy approach or beam search
2.5. Results
①Datasets: COCO-captions, nocaps, and Conceptual Captions
②Data split: 120,000 images and 5 captions per image (80 categories) of COCO for training, nocaps for validation and testing (new categories) and Conceptual Captions for validation (specific entities are replaced with general notions)
③Performance and ablation study:
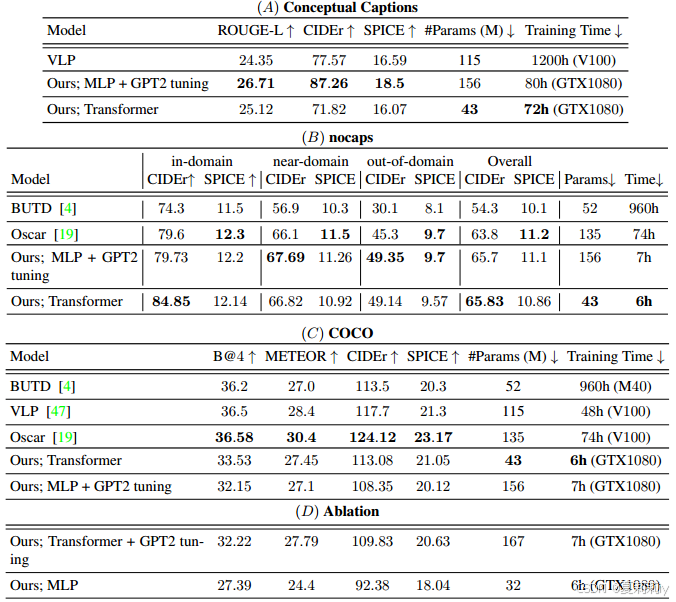
④Captioning results on COCO:

⑤Captioning results on Conceptual Captions:

⑥Generalization on smartphone photos:

⑦Prefix represents(这东西还能是一句话的??):

obtained by the most relevant vocabulary on cosine similarity
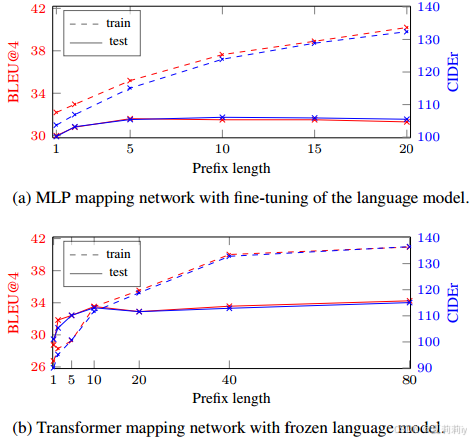
⑧Prefix length ablation:
2.6. Conclusion
~

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









