





论文代码:GitHub - MicroAVA/ChatICD: Prompt Learning for Few-shot ICD Coding through ChatGPT
目录
2.4.1. Data Augmentation with ChatGPT
2.4.2. Prompt-based fine-tuning
2.6.1. Why use ChatGPT for data augmentation?
2.6.2. Why not use ChatGPT directly for ICD coding, but instead use pre-trained models?
2.6.3. Why not use the MIMIC-III-full dataset to validate the method?
1. 心得
(1)方法仅适合类别少的分类,只适合MIMIC-III 50而绝对不适合MIMIC-III full
(2)方法很别致,至于好不好用就不知道了
(3)效果看上去还没人家MIMIC-III-full的好呢
2. 论文逐段精读
2.1. Abstract
①作者提出ChatICD,专注于解决少样本问题
2.2. Introduction
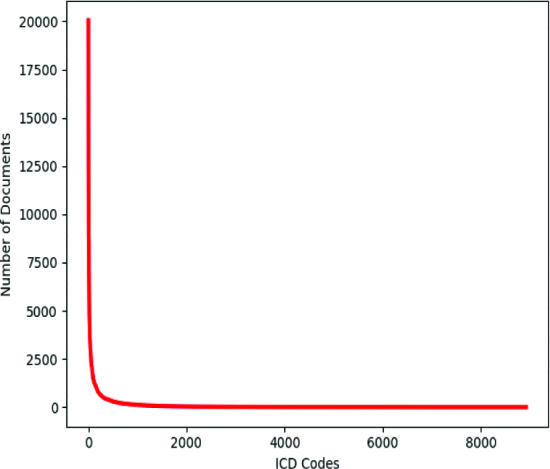
①MIMIC-III数据集的分布:
2.3. Related work
2.3.1. Prompt Learning
①讲了一些提示学习的发展
2.3.2. Few-shot Learning
①介绍一些人怎么解决少样本问题的,如设计特定模型,数据增强或设计特定训练策略
2.3.3. ICD Coding
①介绍了深度学习的发展,从CNN到RNN
2.4. Methods
①模型框架:
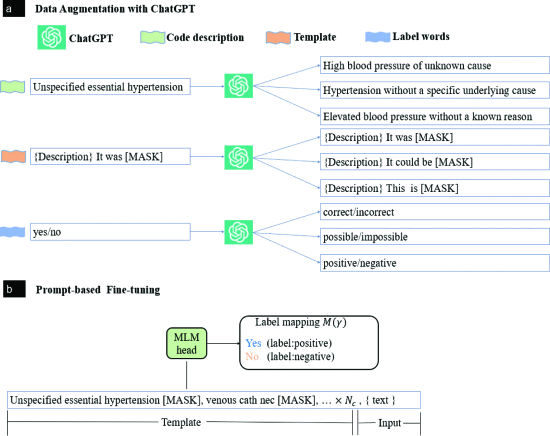
2.4.1. Data Augmentation with ChatGPT
①每个token:
②自回归语言模型ChatGPT的优化目标:已知前面内容,最大化预测内容为正确内容的概率:
其中是可学习参数
③每个token都有词嵌入和位置嵌入:
其中是词向量矩阵,
是位置向量矩阵
④使用个Transformer去提取特征:
⑤预测token:
其中是之前几个Transformer块的输出
2.4.2. Prompt-based fine-tuning
①提示:
类似“一种皮肤病,持续红疹:[yes/no],一种胃病,持续胃疼[yes/no],...,一种传染性疾病,发烧流涕头痛:[yes/no]。发烧流涕”
②标签分类:
其中是输入
的隐藏层
2.5. Experiments
2.5.1. Dataset
①数据集:MIMIC-III-50和MIMIC-III-rare50
②使用样本:对于50个高频代码,训练集有8,066个样本,验证集有1,574个样本,测试集有1,729个样本;对于50个稀有代码,训练集有249个,验证集有20个,测试集有142个样本
2.5.2. Evaluation Metrics
①Micro-F1、Macro-F1、P@k等
2.5.3. Prompt Design
①多轮对话提示:

2.5.4. Baselines
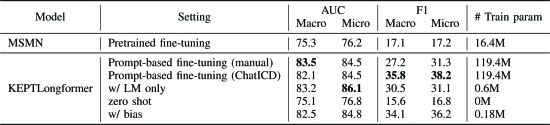
①介绍一些基线:MSATT-KG,MultiResCNN,LAAT和JointLAAT,MSMN,KEPTLongformer
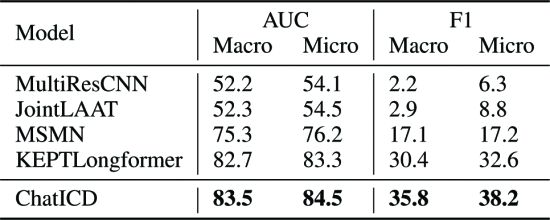
2.5.5. Main Results
①结果:
2.5.6. Ablation Study
①不同模板的实验:
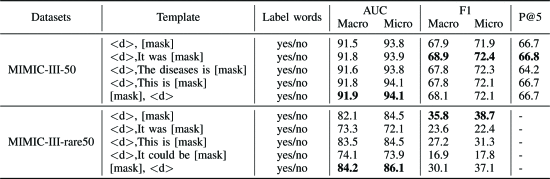
②使用不同预测文本实验:
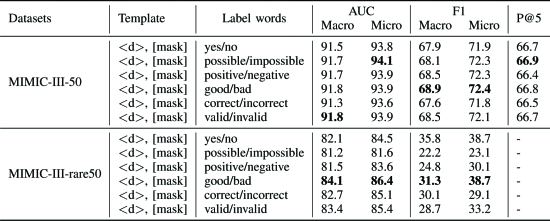
③消融实验:
2.6. Discussion
2.6.1. Why use ChatGPT for data augmentation?
①GPT可以进行数据增强,提供更多的表达风湿,还能补充少数类别(?和这个论文有啥关系)
2.6.2. Why not use ChatGPT directly for ICD coding, but instead use pre-trained models?
①直接用GPT来预测会缺乏医学专业性,隐私性和可解释性
2.6.3. Why not use the MIMIC-III-full dataset to validate the method?
①内存不足....
2.7. Conclusion
........


















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









