








论文代码:NeuroPictor
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4.2. Hign-Level Semantic Feature Learning
2.4.3. Low-Level Manipulation Network
1. 心得
(1)夜间,来到了我最喜欢的ECCV频道
(2)不行了越看越想投ECCV,风格真的好出众啊有种脱口秀的感觉。有一种所有会议都在激战而ECCV独自喝茶的感觉
(3)我rua复旦发个ECCV用了别人整个实验室都不够的卡(手动叠甲(来财来财)
2. 论文逐段精读
2.1. Abstract
①fMRI-to-image process is lack of accuracy on detail reconstruction
2.2. Introduction
①Process of cognition: see it (watching), say it (understanding). And the process of reconstruction: sorted (fMRI)
②Reconstruction steps of NeuroPictor:

③哈哈哈哈哈哈哈哈哈晚间有趣频道,点赞儿。作者说他们可以将一个fMRI的高级特征和另外一个fMRI的低级特征拼起来:

得到了劈叉斑马和扭扭人
2.3. Related Work
①Traditional diffusion model ignores detail reconstruction
②They want utilize conditional diffusion model to control and generate other details
③作者想用多个个体预训练来改善单个个体的解码。emmm,挺反其道而行之的,emm就是感觉训练时间略长?
2.4. Method
①Pipeline of NeuroPictor:
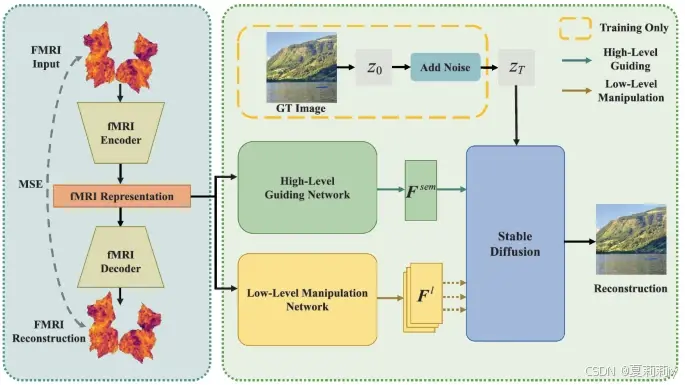
2.4.1. fMRI Encoder
①Pre-processing: inspired by fMRI-PTE, transfering fMRI signal to 2D brain activation with 256×256(就像这样的一个flat map,以下的图来自于fMRI-PTE论文):

②Convert fMRI surface map to latent representation by encoder
:
where , where
denotes the number of token and
denotes the feature dimensions
2.4.2. Hign-Level Semantic Feature Learning
①The pipeline:
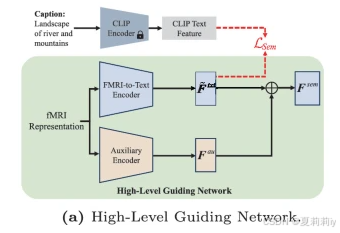
②The fMRI to text encoder is constructed by 2 1D Convs,down sampled original input:
where
③Caption feature loss:
④The auxiliary encoder is constructed by 1D zero conv
⑤The final output:
2.4.3. Low-Level Manipulation Network
①Pipeline:
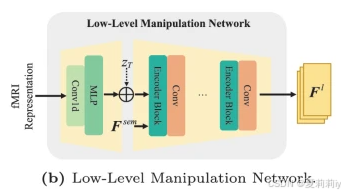
with 2 Conv 1D layers, MLP and U-Net:
②Residual addition:
where is stable diffusion block and
denotes zero conv
2.4.4. Training and Inference
①Input image size: , compress to
②Diffusion object:
where denotes LLMN
③Final loss:
④Dataset: NSD
⑤对数据集把个人的大约六万七千个fMRI图像进行训练???100k迭代??然后对单体进行60k迭代??有点太豪横了
2.5. Experiments
2.5.1. Experimental Setup
①卡:6 个 NVIDIA RTX A6000 GPU
②Batch size: 96
③微调的卡:2 个 NVIDIA RTX A6000 GPU
2.5.2. Main Results
①Performance:
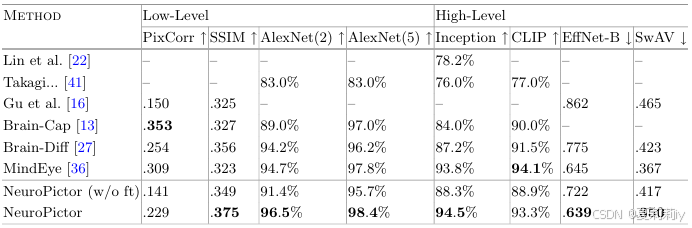
②Reconstruction result:

2.5.3. Ablation Study
①Module ablation:
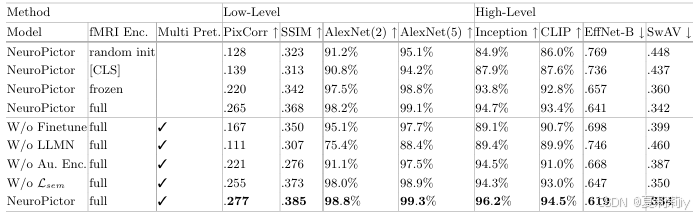
②Trade off of high or low sementic feature:

2.6. Conclusions
~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









