





论文网址:Performance Modelling of Graph Neural Networks | IEEE Conference Publication | IEEE Xplore
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3. Background and Related Work
2.4. GNN Forward Pass Computational Cost
2.6. Conclusion and Future Work
1. 心得
(1)猝死ing
(2)把我读的这么多论文全部献祭给下一篇投的!!!
2. 论文逐段精读
2.1. Abstract
①Evaluation the computational costs of GNNs
2.2. Introduction
①This study calculated the computational cost of forward propagation in GraphConv and GraphSAGE
2.3. Background and Related Work
①Time complexity of standard GCN:
time complexity of standard GraphSAGE:
where is the number of layers,
denotes number of nodes,
denotes number of non-zero values in adjacency matrix,
denotes the number of features,
denotes number of aggregated neighbours per node
2.4. GNN Forward Pass Computational Cost
①Define a graph , where
is the number of vertex,
denotes number of edge
②Node feature: in the
-th layer
③Updating function of GCN:
where denotes learnable matrix(原文写的leamable mamx,看不懂一点,我猜就似乎俩都一起写错了??是什么外文简单表示法吗?), which get:
FLOPs per node per layer
④FLOPs of each GConv layer:
⑤Updating function of GraphSAGE:
where denotes learnable matrix,
is Euclidean norm, and its FLOPs per node per layer is:
and FLOPs per layer is:
⑥FLOPs of two GNNs with 3 layers, ,
and
:
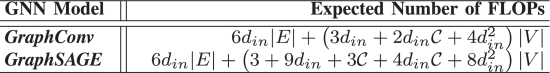
where denotes the number of classes
2.5. Empirical Evaluation
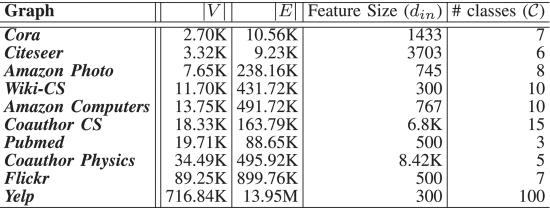
①10 datasets:
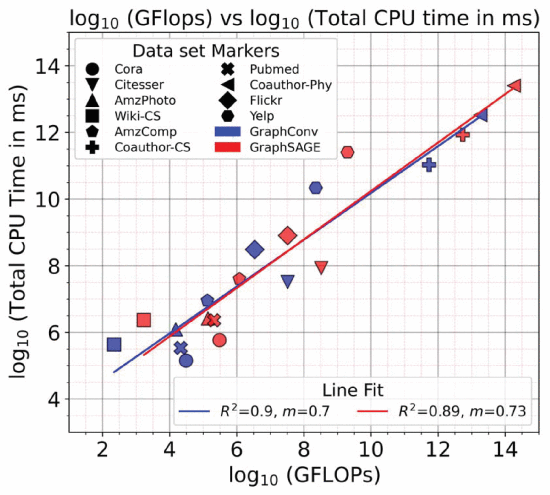
②CPU time of 2 models
2.6. Conclusion and Future Work
~
3. Reference
Naman,P. & Simmhan, Y. (2023) Performance Modelling of Graph Neural Networks, IEEE/ACM 23rd International Symposium on Cluster, Cloud and Internet Computing Workshops (CCGridW). Bangalore, India.

















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









