




英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.3.1. Graph convolution operations
2.4. Empirical and theoretical analysis of deep GNNs
2.4.1. Quantitative metric for smoothness
2.4.3. Theoretical analysis of very deep models
2.5. Deep adaptive graph neural network
1. 省流版
1.1. 心得
(1)有点难评,我觉得是比较简单的东西诶
2. 论文逐段精读
2.1. Abstract
①They proposed a Deep Adaptive Graph Neural Network (DAGNN) to solve the over smoothing problem when the GNN is too deep
2.2. Introduction
①DAGNN adaptively integrates information and learns node representations
2.3. Background and related works
①Graph representation:
②,
,
,
③Adjacency matrix with no weight (0 and 1 only)
④Degree matrix and
⑤Neighbor nodes are represented by
⑥Node feature matrix
2.3.1. Graph convolution operations
①Traditional message passing:
②Convolution operator:
where ,
2.3.2. Related works
①Stacking multi layers might brings indistinguishable problem of nodes in different classes
②Listing some remote capturing models
demystify vt. 使非神秘化;阐明;启发
2.4. Empirical and theoretical analysis of deep GNNs
2.4.1. Quantitative metric for smoothness
①Similarity metric (Euclidean distance) between node and node
:
where denotes Euclidean norm
②Smoothness metric:
(为什么作者认为叶子节点有更大的平滑度度量值?这个n不是节点总数吗,叶子节点不是邻居更少吗?那应该平滑度度量值更小吧?还是说这个n代表邻居个数?我认为不太是后者)
③Smoothness metric of the whole graph :
periphery n. 外围,边缘;圆周;圆柱体表面
2.4.2. Why deeper GNNs fail?
①Datasets: Cora, CiteSeer and PubMed
②t-SNE visualization on different layers on Cora:

③Accuracy on Cora with different layers:
④Over smoothing problems mostly exist in sparse graph
⑤Decoupled transformation formula:
⑥Statistics of datasets, where the edge density is calculated by :

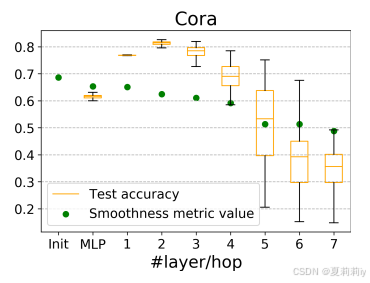
⑦Deeper layer on Cora:

⑧Accuracy and smoothness on Cora:
2.4.3. Theoretical analysis of very deep models
①Two propagation mechanisms:
mostly in GraphSAGE and DGCNN and
in GCN
②They define ,
, and
③They introduce 2 theorem to prove the convergence:

④剩余定理和证明略
2.5. Deep adaptive graph neural network
①Steps of DAGNN:
where is the number of node classes,
denotes feature matrix,
denotes trainable projection vector, they set
to Sigmoid,
is the layer of model
②It's hard to define the hop number, so they designed adaptive projection vector
③⭐There is no fully connected layer in the last layer but only use
④The loss function can be:
where denotes the set of labeled nodes,
stores the real label
⑤Workflow of DAGNN:
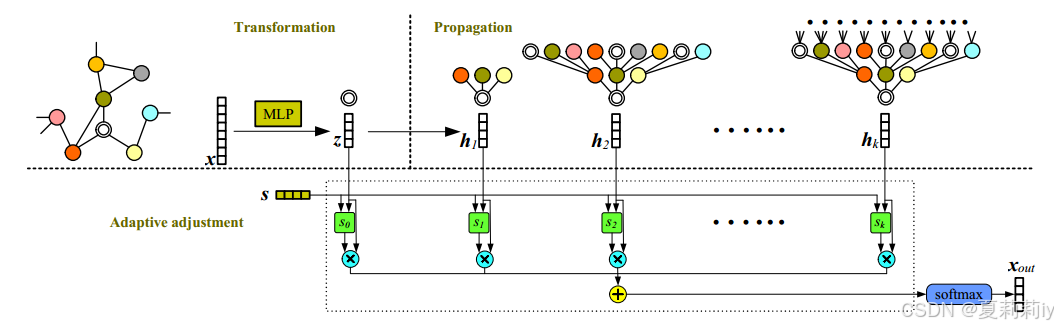
(说句实话,为什么我觉得这玩意儿这么抽象,毕竟感觉每一层都加入了前面所有层,照这样来说对于越深的层就给越低的权重就好了....因为过于平滑....但这样也聊胜于无嘛)
2.6. Experimental strudies
2.6.1. Datasets and setup
①Datasets: Cora,CiteSeer, PubMed, Coauthor CS, Coauthor Physics, Amazon Computers, Amazon Photo:

②Baselines: Logistic Regression (LogReg), Multilayer Perceptron (MLP), Label Propagation (LabelProp), ormalized Laplacian Label Propagation (LabelProp NL), ChebNet, Graph Convolutional Network (GCN), Graph Attention Network(GAT), Mixture Model Network (MoNet), GraphSAGE, APPNP, SGC
③Grid search for hyperparameters: ,
,
2.6.2. Overall results
①Uniform setting on Cora, CiteSeer and PubMed: 20 labeled nodes/class for training, 500 nodes for val and 1000 to test. On co-authorship and co-purchase: 20 labeled/class for training, 30 nodes/class for val and the rest is for test
②Epoch: 100 for fixed and random split respectively
③Performance comparison table on Cora, CiteSeer and PubMed:
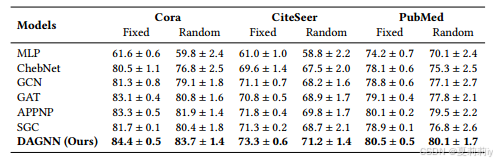
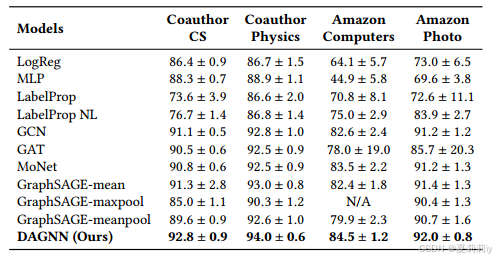
④Performance comparison table on co-authorship and co-purchase:
2.6.3. Training set sizes
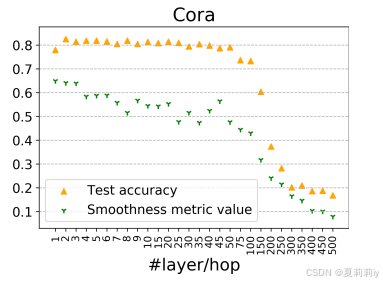
①For comparing the influence of depth, they set the layer in APPNP, SGC and DAGNN to 10 and test them in a relatively large dataset Cora:

2.6.4. Model Depths
①To test how depths/hops influence smoothness:

②It should be fewer hops when facing dense graph
2.7. Conclusion
我其实没太get到作者一直强调的解耦,哪里解耦了?感觉不就像是一个注意力机制或者打分机制啥的
3. Reference
Liu, M., Gao,H. & Ji, S. (2020) 'Towards Deeper Graph Neural Networks', KDD. pp. 338-348. doi: Towards Deeper Graph Neural Networks | Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining

















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









