



https://github.com/ShaddockNH3/FZU-SE-Neko-Caller
https://blog.youkuaiyun.com/Shaddock42125/article/details/155076245?sharetype=blogdetail&sharerId=155076245&sharerefer=PC&sharesource=Shaddock42125&spm=1011.2480.3001.8118
https://live.youkuaiyun.com/v/501761
一、结对探索
1.1 队伍基本信息
结对编号:01;队伍名称:NekoCaller;
| 学号 | 姓名 | 具体分工 |
|---|---|---|
| 022302217 | 郑伟 | 负责设计数据库,实现基本的全盘逻辑,增加趣味功能 |
| 052306116 | 周晨烁 | 实现前端以及实现了导入表格等逻辑 |
1.2 描述结对的过程
在本次结对编程任务中,我们两人通过线上协作的方式完成了课堂随机点名系统的开发。郑伟负责后端数据库设计和核心业务逻辑的实现,周晨烁负责前端界面开发和数据导入功能。我们通过GitHub进行代码版本管理,使用 Issues 和 Pull Requests 进行任务分配和代码审查。初期通过 QQ 讨论需求分析和原型设计,后续通过代码提交和合并保持同步。
1.3 非摆拍的两人在讨论设计或结对编程过程的照片

二、原型设计
2.1 原型工具的选择
我们选择了墨刀作为原型设计工具,因为它支持实时协作、丰富的交互设计功能,且免费版足以满足我们的需求。墨刀的组件库和模板功能帮助我们快速搭建界面原型。
2.2 遇到的困难与解决办法
在原型设计过程中,我们遇到的主要困难是:
- 如何设计趣味性事件系统的交互界面
- 点名结算流程的逻辑梳理
通过多次讨论和参考优秀作业,我们采用了标签展示事件效果、滑块控制分数的方式解决。
2.3 原型作品链接
https://modao.ink/proto/VzUtCFsXt60z386qdyGpdp/sharing?view_mode=read_only&screen=rbpV35rGLl8tbNXnG
2.4 原型界面图片展示
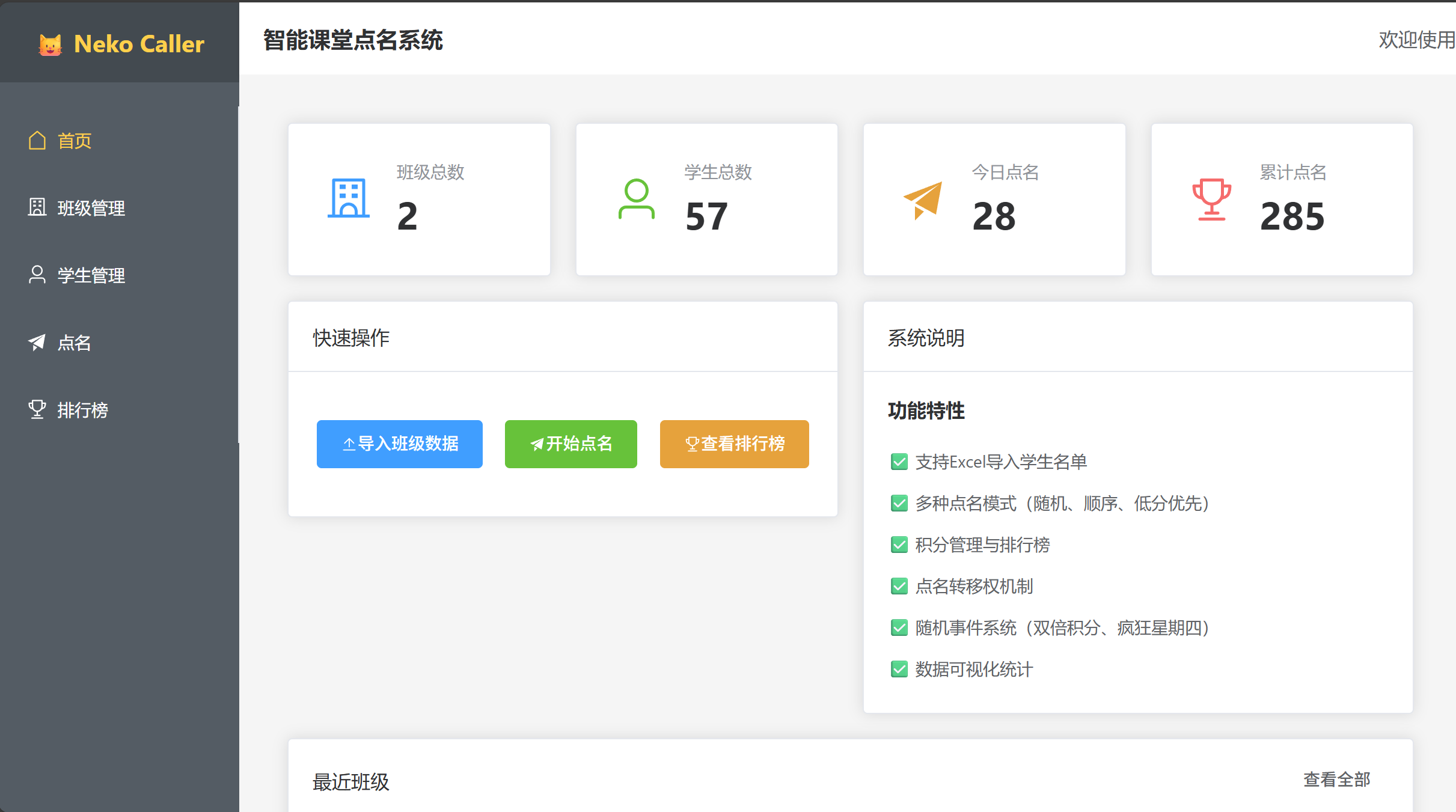
主页面
- 显示班级列表和统计信息
- 快速操作入口:导入数据、开始点名、查看排行榜
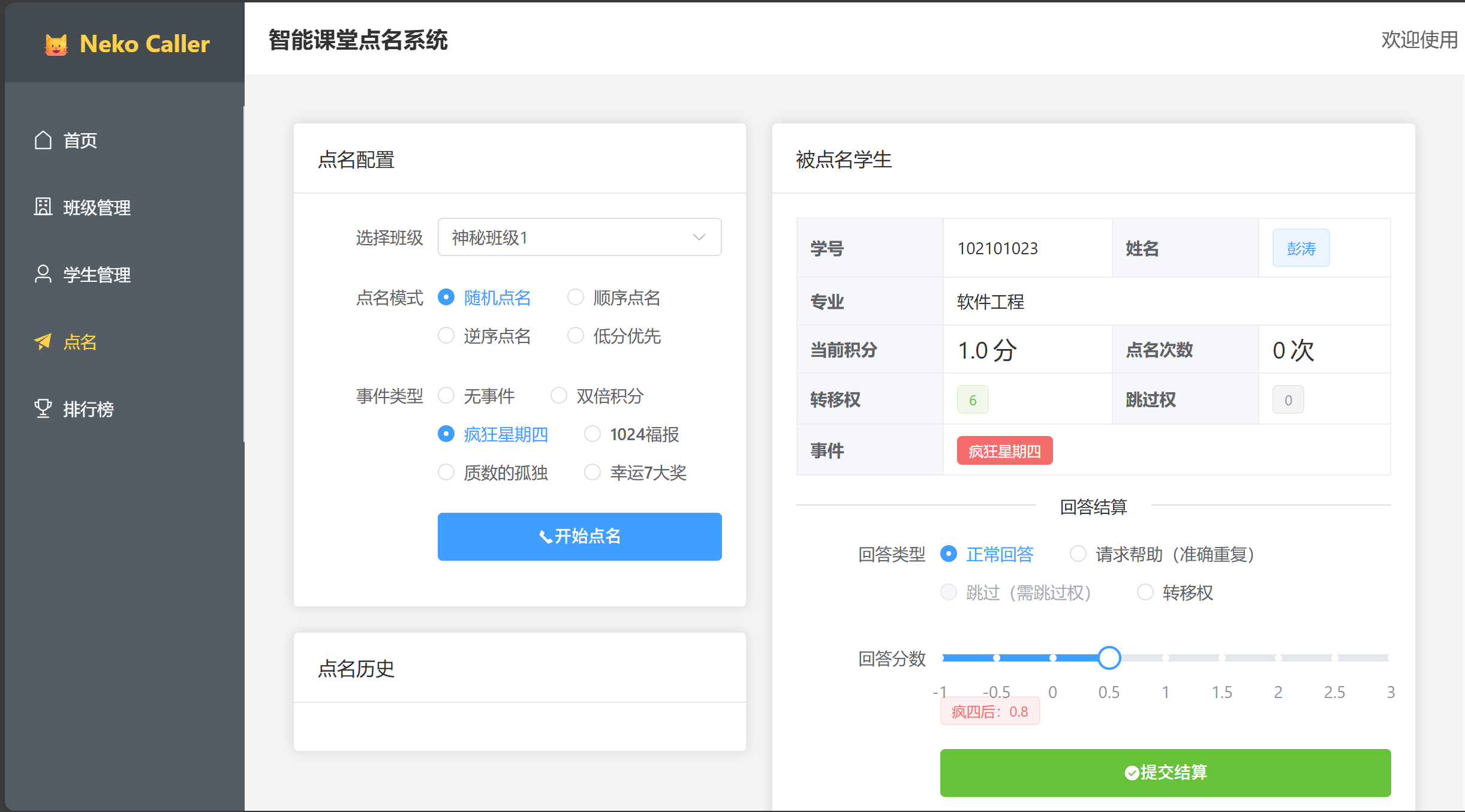
点名界面
- 左侧配置区:选择班级、点名模式、事件类型
- 右侧结果区:显示被点名学生信息和结算表单
- 支持多种事件:双倍积分、疯狂星期四、1024福报等
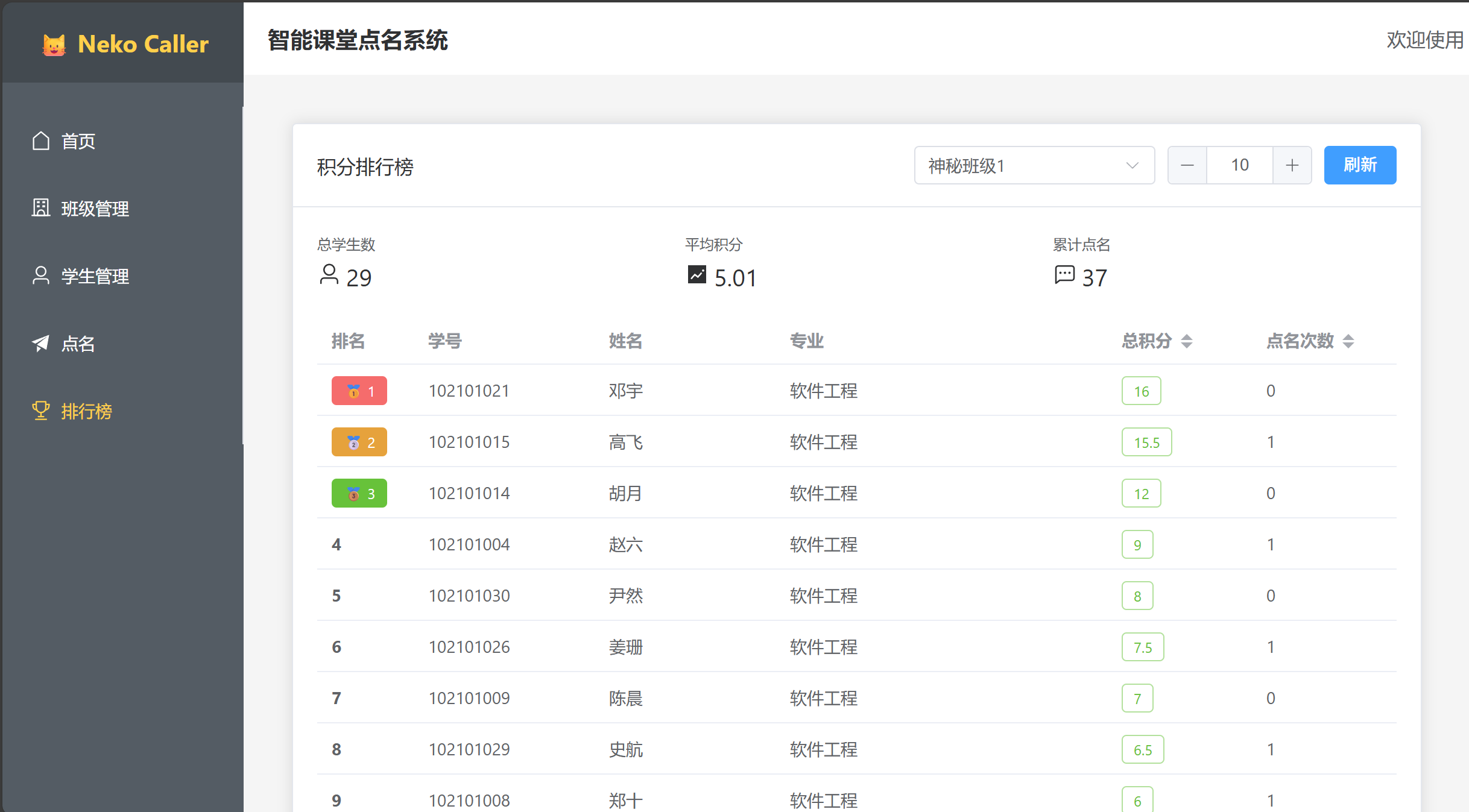
排行榜界面
- 展示Top N学生排名
三、编程实现
3.1 开发工具库的使用
后端使用了:
- Hertz:高性能HTTP框架,由CloudWeGo提供,支持高并发请求处理
- GORM:ORM框架,用于数据库操作,支持多种数据库
- gorm-gen:GORM代码生成工具,自动生成数据库查询代码,提高开发效率
- Excelize:Excel文件处理库,用于导入导出学生名单和积分详单
- Thrift:RPC框架,用于定义API接口和数据结构
- UUID:唯一标识符生成库,用于生成班级ID、选课ID等主键
前端使用了:
- Vue 3:渐进式JavaScript框架,支持组合式API
- Element Plus:Vue 3 UI组件库,提供丰富的界面组件
- Axios:HTTP客户端,用于与后端API通信
- Vue Router 4:官方路由管理器,支持单页应用导航
数据库使用了:
- MySQL 8:关系型数据库,部署在db4free.net免费托管服务上
3.2 代码组织与内部实现设计
类图设计
数据模型类
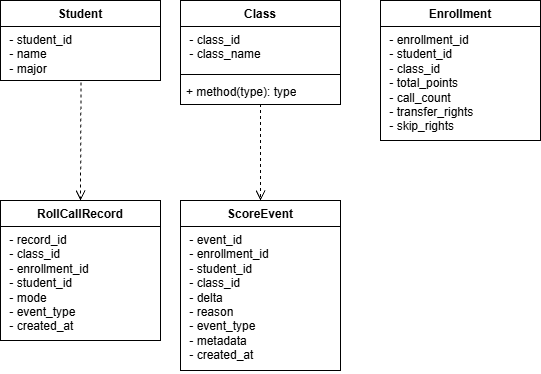
服务类关系
项目目录结构
FZU-SE-Neko-Caller/
├── docs/ # 文档目录
│ ├── 0.作业要求文档.md # 作业要求
│ ├── API文档.md # API文档
│ ├── architecture.md # 架构文档
├── NekoCallerBackend/ # 后端代码
│ ├── main.go # 程序入口
│ ├── go.mod # Go模块文件
│ ├── biz/ # 业务逻辑层
│ │ ├── dal/ # 数据访问层
│ │ │ ├── model/ # 数据模型
│ │ │ ├── mysql/ # 数据库连接
│ │ │ └── query/ # GORM生成查询
│ │ ├── handler/ # HTTP处理器
│ │ ├── service/ # 业务服务层
│ │ └── router/ # 路由注册
│ ├── idl/ # Thrift IDL定义
│ └── pkg/ # 公共包
│ ├── constants/ # 常量定义
│ ├── errno/ # 错误码
│ └── utils/ # 工具函数
└── NekoCallerFrountend/ # 前端代码
├── index.html # HTML入口
├── package.json # Node.js依赖
├── vite.config.js # Vite配置
├── public/ # 静态资源
└── src/ # 源代码
├── main.js # Vue入口
├── App.vue # 根组件
├── api/ # API接口
├── router/ # 路由配置
└── views/ # 页面组件
3.3 算法关键与流程图
核心算法说明
本系统的核心算法包括四种点名模式:加权随机点名、顺序点名、逆序点名以及低分优先点名。其中加权随机点名和低分优先点名是两个核心算法。
1. 加权随机算法实现
加权随机点名通过积分和点名次数计算权重,确保积分较低的学生被点到的概率更高,同时支持多种趣味事件来调整权重。
权重计算公式:
weight=11+points×0.4+callCount×0.2 weight = \frac{1}{1 + points \times 0.4 + callCount \times 0.2} weight=1+points×0.4+callCount×0.21
其中:
points: 学生当前总积分callCount: 学生被点名次数- 系数0.4和0.2分别控制积分和点名次数对权重的影响
特点:
- 积分越低,权重越高,被点到的概率越大
- 点名次数越多,权重越低,确保公平性
- 支持多种随机事件加成(双倍积分、疯狂星期四等)
func randomRoll(roster []*common.RosterItem, event common.RandomEventType) (common.RosterItem, error) {
weights := make([]float64, len(roster))
total := 0.0
// 计算每个学生的权重
for i, item := range roster {
w := baseWeight(item)
// 事件权重调整
switch event {
case common.RandomEventType_Double_Point:
w *= 1.3
case common.RandomEventType_CRAZY_THURSDAY:
// 积分为50的因数时权重增加
if isFactorOf50(item.EnrollmentInfo.TotalPoints) {
w *= 1.25
}
}
weights[i] = w
total += w
}
// 使用累积分布随机选择
randPoint := rng.Float64() * total
for i, weight := range weights {
if randPoint <= weight {
return *roster[i], nil
}
randPoint -= weight
}
return *roster[len(roster)-1], nil
}
func baseWeight(item *common.RosterItem) float64 {
points := math.Max(item.EnrollmentInfo.TotalPoints, 0)
callCount := math.Max(float64(item.EnrollmentInfo.CallCount), 0)
return 1 / (1 + points*0.4 + callCount*0.2)
}
2. 低分优先算法实现
低分优先点名采用分段正态分布策略,将学生按积分和点名次数排序后,从积分最低的前1/3学生中随机选择一个进行点名。这种算法确保了积分较低的学生有更高的被点概率,同时保持一定的随机性。
算法步骤:
- 按照积分升序排序(积分相同则按点名次数升序)
- 选取前 ⌈n/3⌉ 名学生(n为总学生数)
- 从这些学生中随机选择一个
数学模型:
candidates=⌈n3⌉ candidates = \left\lceil \frac{n}{3} \right\rceil candidates=⌈3n⌉
selected=random(sorted_roster[0:candidates]) selected = random(sorted\_roster[0:candidates]) selected=random(sorted_roster[0:candidates])
特点:
- 积分最低的学生群体有100%被候选的概率
- 保证了对学习困难学生的关注
- 避免了完全确定性点名带来的可预测性
- 兼顾公平性和激励性
func lowPointsFirst(roster []*common.RosterItem) common.RosterItem {
// 复制名册避免修改原数据
copyRoster := make([]*common.RosterItem, len(roster))
copy(copyRoster, roster)
// 按积分和点名次数排序
sort.Slice(copyRoster, func(i, j int) bool {
if copyRoster[i].EnrollmentInfo.TotalPoints == copyRoster[j].EnrollmentInfo.TotalPoints {
// 积分相同时,按点名次数升序
return copyRoster[i].EnrollmentInfo.CallCount < copyRoster[j].EnrollmentInfo.CallCount
}
// 按积分升序
return copyRoster[i].EnrollmentInfo.TotalPoints < copyRoster[j].EnrollmentInfo.TotalPoints
})
// 计算候选范围: 最多前1/3的学生,至少1个
limit := int(math.Max(1, math.Ceil(float64(len(copyRoster))/3)))
// 从候选范围内随机选择
return *copyRoster[rng.Intn(limit)]
}
算法对比分析:
| 特性 | 加权随机 | 低分优先 |
|---|---|---|
| 公平性 | ★★★★☆ | ★★★★★ |
| 随机性 | ★★★★★ | ★★★☆☆ |
| 可预测性 | 低 | 中等 |
| 激励效果 | 强 | 很强 |
| 适用场景 | 常规点名 | 照顾后进生 |
3. 趣味随机事件系统
为了增加课堂互动的趣味性,系统设计了五种特殊的随机事件,每种事件都有独特的触发条件和积分加成规则:
3.1 双倍积分 (Double Point)
事件说明: 最基础的加成事件,所有积分变化翻倍。
触发条件: 无条件触发
积分规则:
- 正常回答/请求帮助的积分 × 2
- 跳过/转移不受影响
实现代码:
case common.RandomEventType_Double_Point:
if req.AnswerType == common.AnswerType_NORMAL || req.AnswerType == common.AnswerType_HELP {
base *= 2
}
3.2 疯狂星期四 (Crazy Thursday)
事件说明: 致敬肯德基疯狂星期四,积分为50的因数的学生有额外权重加成。
触发条件: 无条件触发
积分规则:
- 正常回答/请求帮助的积分 × 1.5
- 跳过/转移不受影响
权重加成: 当学生总积分为50的因数(1, 2, 5, 10, 25, 50)时,被点名权重 × 1.25
实现代码:
case common.RandomEventType_CRAZY_THURSDAY:
// 权重调整
if isFactorOf50(item.EnrollmentInfo.TotalPoints) {
w *= 1.25
}
// 积分加成
if req.AnswerType == common.AnswerType_NORMAL || req.AnswerType == common.AnswerType_HELP {
base *= 1.5
}
func isFactorOf50(points float64) bool {
intPoints := int(points)
if intPoints <= 0 || intPoints > 50 {
return false
}
return 50%intPoints == 0
}
3.3 1024 程序员福报 (Blessing 1024)
事件说明: 向程序员节致敬,在特定时刻触发时给予特殊奖励。
触发条件: 点名时的秒数为2的幂次方(1, 2, 4, 8, 16, 32秒)
积分规则:
- 回答正确: 固定获得 +1.024 分(无视原始分数)
- 回答错误: 免除扣分,得 0 分(幸运保护)
- 条件不满足时事件失效
实现代码:
func checkEventCondition(eventType common.RandomEventType, studentID string) bool {
now := time.Now()
second := now.Second()
switch eventType {
case common.RandomEventType_BLESSING_1024:
return isPowerOfTwo(second)
}
}
func isPowerOfTwo(n int) bool {
if n <= 0 {
return false
}
return (n & (n - 1)) == 0 // 位运算判断2的幂次方
}
// 积分计算
case common.RandomEventType_BLESSING_1024:
if req.CustomScore != nil {
if *req.CustomScore > 0 {
base = 1.024 // 回答正确固定积分
} else if *req.CustomScore < 0 {
base = 0 // 回答错误免除扣分
}
}
3.4 质数的孤独 (Solitude of Primes)
事件说明: 以数学中质数的独特性为主题,在特定时刻给予额外奖励。
触发条件: 点名时的分钟数为质数(2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59)
积分规则:
- 回答正确时: 额外增加 +0.37 分
- 回答错误时: 按正常规则扣分
- 条件不满足时事件失效
实现代码:
func isPrime(n int) bool {
primes := []int{2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59}
for _, p := range primes {
if p == n {
return true
}
}
return false
}
case common.RandomEventType_SOLITUDE_PRIMES:
if isCorrect { // 回答正确
base += 0.37
}
3.5 幸运7大奖 (Lucky 7)
事件说明: 学号尾号为7的学生的专属幸运事件。
触发条件: 被点名学生的学号末位数字为 ‘7’
积分规则:
- 回答错误时: 免除扣分,得 0 分(幸运闪避)
- 回答正确时: 按正常规则计分
- 条件不满足时事件失效
实现代码:
case common.RandomEventType_LUCKY_7:
result := len(studentID) > 0 && studentID[len(studentID)-1] == '7'
// 积分计算
case common.RandomEventType_LUCKY_7:
if req.CustomScore != nil && *req.CustomScore < 0 {
base = 0 // 幸运闪避,免除错误扣分
}
事件效果对比表:
| 事件名称 | 触发条件 | 加成类型 | 正确答题奖励 | 错误答题惩罚 | 趣味性 |
|---|---|---|---|---|---|
| 双倍积分 | 无 | 积分×2 | 高 | 高 | ★★★☆☆ |
| 疯狂星期四 | 无 | 积分×1.5+权重 | 中高 | 中高 | ★★★★☆ |
| 1024福报 | 秒数=2^n | 特殊规则 | 固定1.024 | 免扣分 | ★★★★★ |
| 质数孤独 | 分钟=质数 | 正确+0.37 | 额外加分 | 正常 | ★★★★☆ |
| 幸运7 | 学号尾号7 | 错误免扣 | 正常 | 免扣分 | ★★★★☆ |
设计思路:
- 时间触发机制 (1024福报、质数孤独): 增加随机性和期待感,让每个时刻都有意义
- 个人属性触发 (幸运7): 基于学号的固定属性,给特定学生归属感
- 状态触发机制 (疯狂星期四): 基于积分状态,鼓励学生关注自己的积分
- 容错机制: 多个事件提供"免扣分"保护,降低学生的焦虑感
- 积分平衡: 不同事件的加成倍率经过精心设计,避免积分膨胀
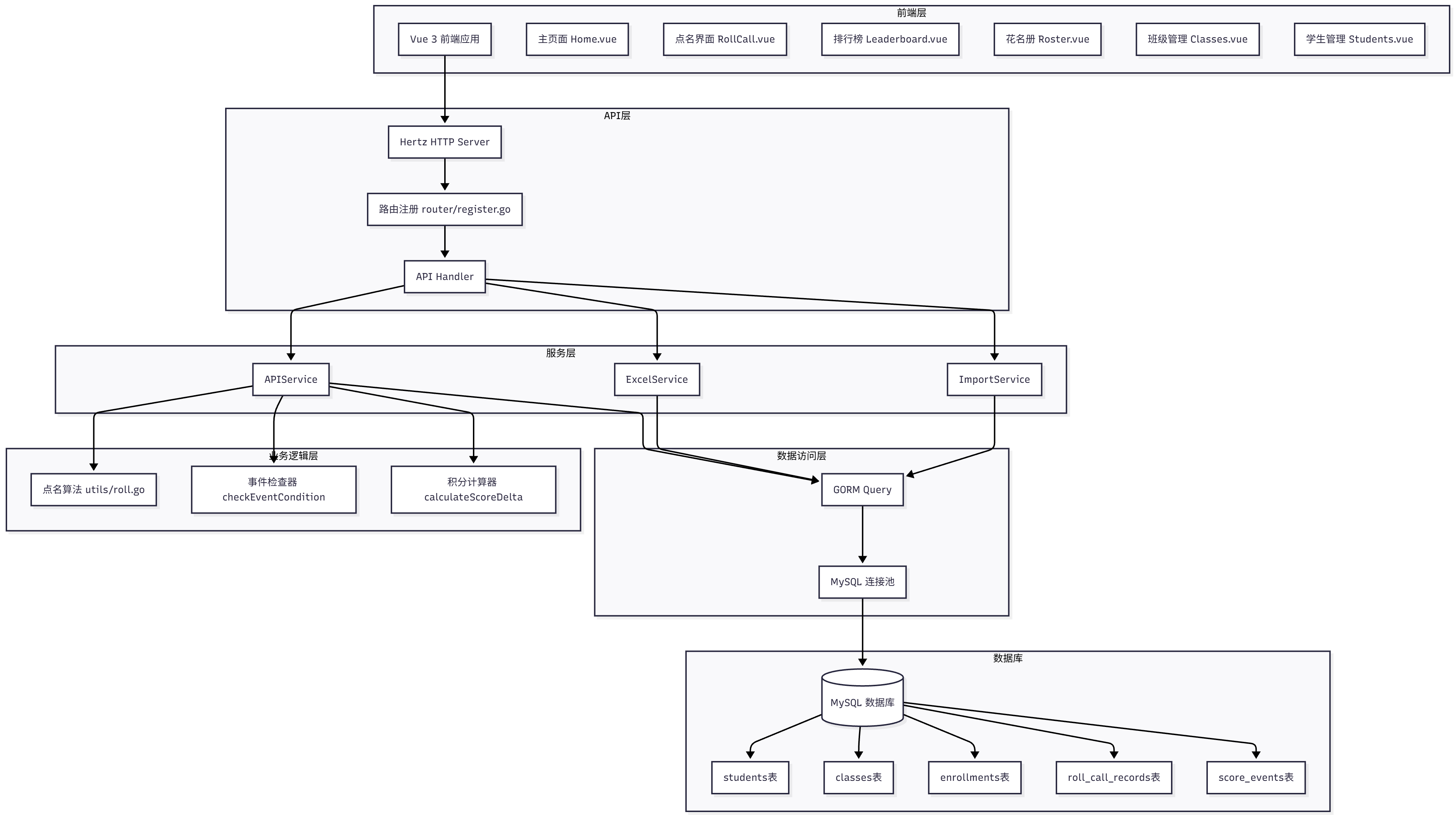
系统流程图
- 系统总体架构流程
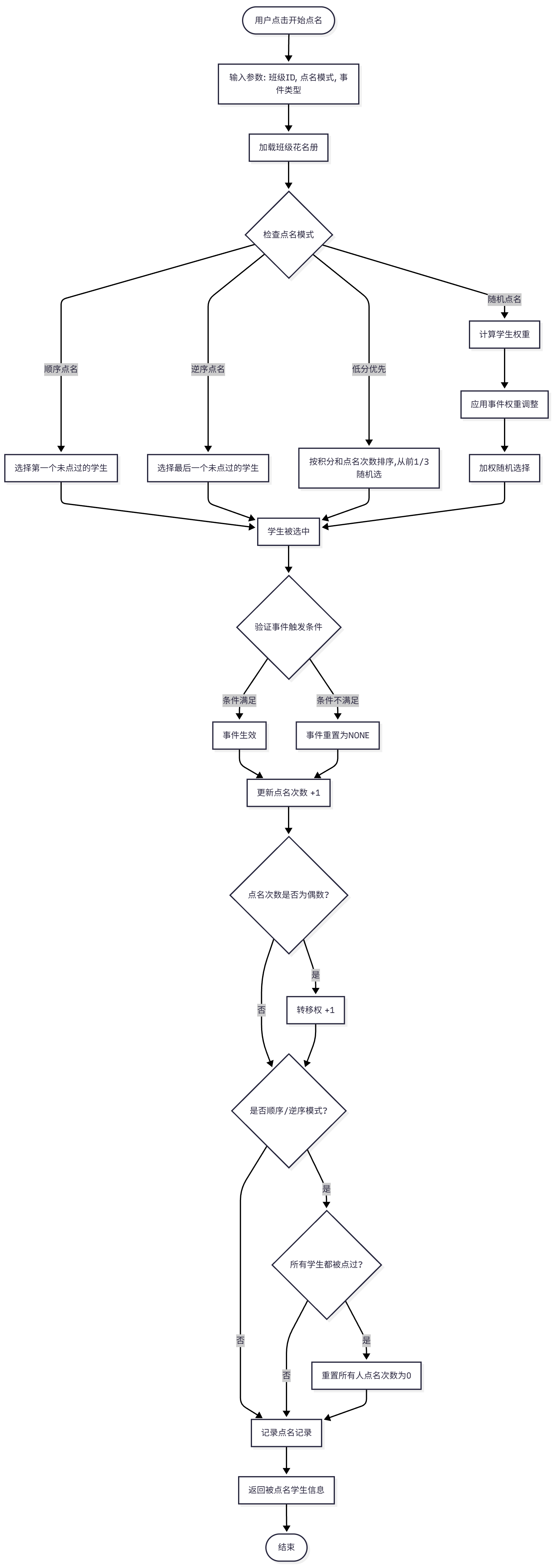
- 点名核心流程
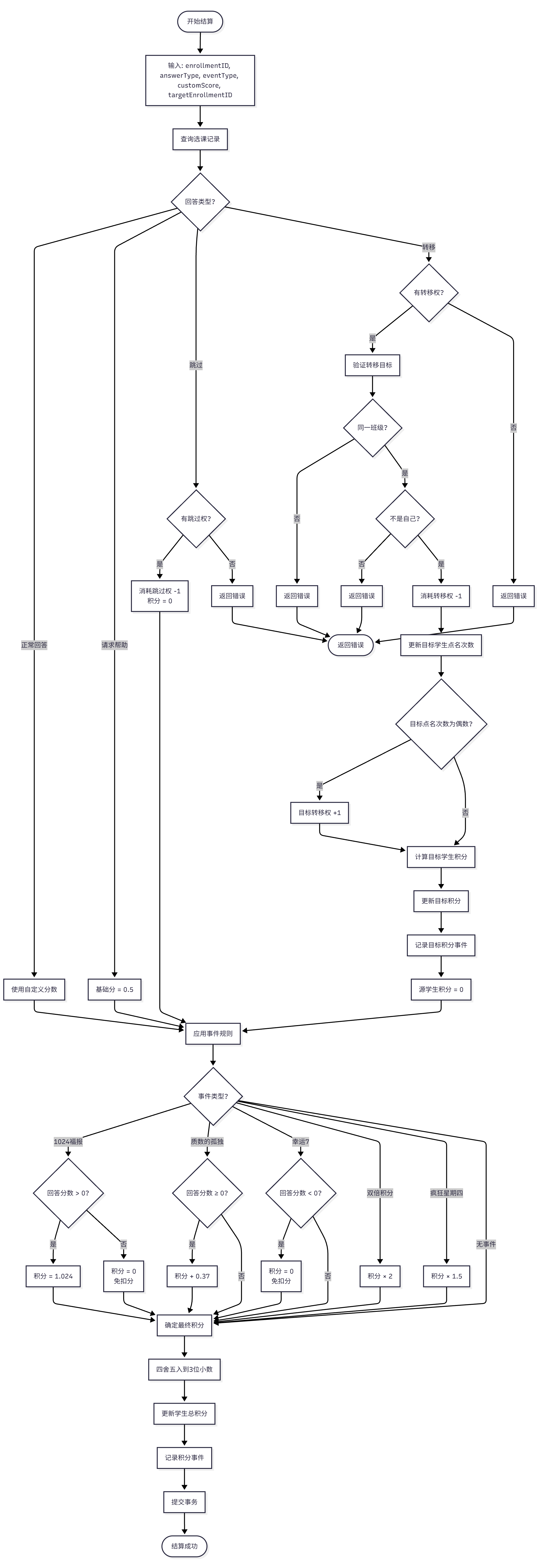
- 处理流程
3.4 贴出重要的/有价值的代码片段并解释
1. 事件条件检查函数
该函数负责验证特殊事件的触发条件是否满足,是事件系统的核心验证逻辑。
func checkEventCondition(eventType common.RandomEventType, studentID string) bool {
now := time.Now()
second := now.Second()
minute := now.Minute()
switch eventType {
case common.RandomEventType_BLESSING_1024:
return isPowerOfTwo(second) // 秒数为2的幂次方
case common.RandomEventType_SOLITUDE_PRIMES:
return isPrime(minute) // 分钟数为质数
case common.RandomEventType_LUCKY_7:
return len(studentID) > 0 && studentID[len(studentID)-1] == '7' // 学号末位为7
default:
return true // 其他事件无条件触发
}
}
设计亮点:
- 使用时间作为随机性来源,增加不可预测性
- 位运算快速判断2的幂次方:
(n & (n-1)) == 0 - 预定义质数表避免重复计算
- 学号末位判断简洁高效
2. 积分计算核心逻辑
这段代码展示了如何根据回答类型和随机事件计算最终积分,是系统奖惩机制的核心。
func calculateScoreDelta(req *api.SolveRollCallRequest) float64 {
base := 0.0
isCorrect := false
// 根据回答类型确定基础分数
switch req.AnswerType {
case common.AnswerType_NORMAL:
if req.CustomScore != nil {
base = *req.CustomScore // -1到3分的自定义分数
if base >= 0 {
isCorrect = true
}
}
case common.AnswerType_HELP:
base = 0.5 // 请求帮助并准确重复问题
isCorrect = true
case common.AnswerType_SKIP:
base = 0 // 使用跳过权,不扣分
case common.AnswerType_TRANSFER:
base = 0 // 使用转移权,不扣分
}
// 应用随机事件加成
switch req.EventType {
case common.RandomEventType_BLESSING_1024:
if req.CustomScore != nil {
if *req.CustomScore > 0 {
base = 1.024 // 正确答题固定奖励
} else if *req.CustomScore < 0 {
base = 0 // 错误免扣分
}
}
case common.RandomEventType_SOLITUDE_PRIMES:
if isCorrect {
base += 0.37 // 正确答题额外奖励
}
case common.RandomEventType_LUCKY_7:
if req.CustomScore != nil && *req.CustomScore < 0 {
base = 0 // 错误答题幸运闪避
}
case common.RandomEventType_Double_Point:
if req.AnswerType == common.AnswerType_NORMAL ||
req.AnswerType == common.AnswerType_HELP {
base *= 2 // 双倍积分
}
case common.RandomEventType_CRAZY_THURSDAY:
if req.AnswerType == common.AnswerType_NORMAL ||
req.AnswerType == common.AnswerType_HELP {
base *= 1.5 // 1.5倍积分
}
}
return math.Round(base*1000) / 1000 // 保留3位小数
}
设计亮点:
- 分层计算:先确定基础分,再应用事件加成
- 类型安全:使用枚举避免魔法数字
- 容错保护:多种"免扣分"机制降低焦虑
- 精度控制:四舍五入到3位小数,避免浮点误差
3. 转移权处理机制
转移权是系统的创新玩法,允许学生将点名机会转移给他人,这段代码展示了完整的转移逻辑和事务处理。
func (s *APIService) processTransfer(tx *query.Query, src *model.Enrollment,
req *api.SolveRollCallRequest) (*model.Enrollment, error) {
targetID := strings.TrimSpace(req.GetTargetEnrollmentID())
if targetID == "" {
return nil, errno.ParamErr.WithMessage("target_enrollment_id required")
}
// 查找转移目标
target, err := tx.Enrollment.WithContext(s.ctx).
Where(tx.Enrollment.EnrollmentID.Eq(targetID)).
First()
if err != nil {
return nil, errno.StudentNotFoundErr
}
// 业务规则验证
if target.ClassID != src.ClassID {
return nil, errno.ParamErr.WithMessage("target must be in the same class")
}
if target.EnrollmentID == src.EnrollmentID {
return nil, errno.ParamErr.WithMessage("cannot transfer to self")
}
if src.TransferRights <= 0 {
return nil, errno.TransferRightsNotEnough
}
// 消耗源学生的转移权
if _, err := tx.Enrollment.WithContext(s.ctx).
Where(tx.Enrollment.EnrollmentID.Eq(src.EnrollmentID)).
Update(tx.Enrollment.TransferRights, src.TransferRights-1); err != nil {
return nil, err
}
// 更新目标学生的点名次数
nextCount := target.CallCount + 1
if _, err := tx.Enrollment.WithContext(s.ctx).
Where(tx.Enrollment.EnrollmentID.Eq(target.EnrollmentID)).
Update(tx.Enrollment.CallCount, nextCount); err != nil {
return nil, err
}
// 每点名2次奖励1个转移权(连锁反应)
if nextCount%2 == 0 {
if _, err := tx.Enrollment.WithContext(s.ctx).
Where(tx.Enrollment.EnrollmentID.Eq(target.EnrollmentID)).
UpdateSimple(tx.Enrollment.TransferRights.Add(1)); err != nil {
return nil, err
}
}
// 计算并更新目标学生的积分(转移目标也能获得积分)
if req.CustomScore != nil {
targetDelta := calculateTransferScore(req)
if targetDelta != 0 {
if _, err := tx.Enrollment.WithContext(s.ctx).
Where(tx.Enrollment.EnrollmentID.Eq(target.EnrollmentID)).
Update(tx.Enrollment.TotalPoints, target.TotalPoints+targetDelta); err != nil {
return nil, err
}
}
}
return target, nil
}
设计亮点:
- 事务保护:所有数据库操作在同一事务中,保证数据一致性
- 多重验证:检查同班级、非自己、有转移权等条件
- 连锁奖励:转移目标被点名也能获得积分和转移权
- 完整性:记录转移来源,方便追溯和统计
转移权获取规则:
- 每被点名2次,自动获得1个转移权
- 转移权可累积,无上限
- 使用转移权不扣分,但会增加对方的点名次数
业务价值:
- 社交互动: 鼓励同学之间的互动和策略博弈
- 压力分散: 学习困难的学生可以将压力转移
- 公平激励: 被点名多的学生获得更多转移权,形成平衡
- 趣味性: 增加课堂的不确定性和可玩性
3.5 性能分析与改进
性能分析方法
本项目使用Go语言内置的pprof工具进行性能分析。在main.go中添加pprof支持:
import _ "net/http/pprof"
func main() {
// 启动pprof性能分析服务
go func() {
log.Println("pprof服务启动在 http://localhost:6060/debug/pprof/")
http.ListenAndServe(":6060", nil)
}()
// 其他初始化代码...
}
性能分析结果
通过采集30秒的CPU性能数据并分析,识别出以下主要性能消耗点:
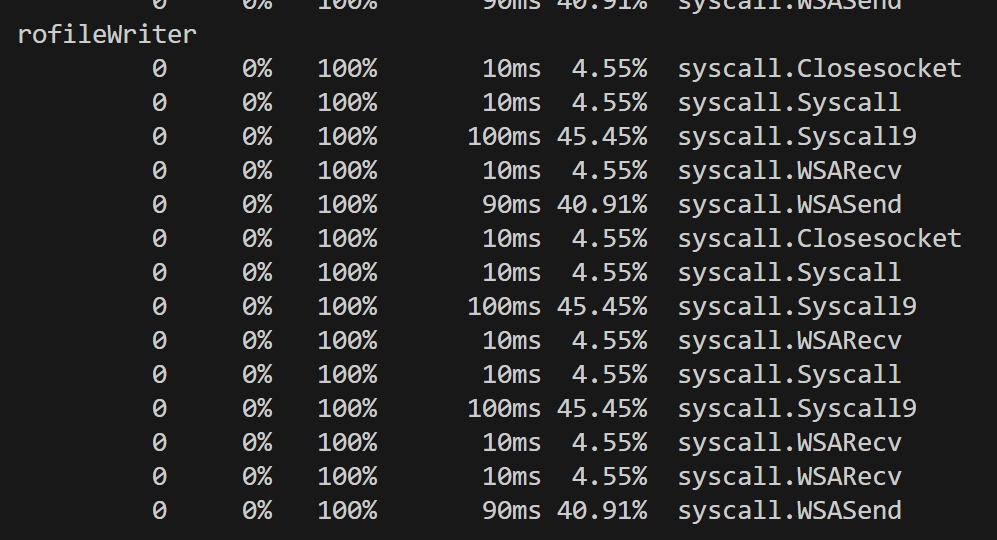
分析发现:
通过pprof分析,程序中CPU消耗最大的部分是数据库I/O操作(runtime.cgocall占用约50%的CPU时间),这主要是MySQL驱动通过CGO调用底层C库导致的。在业务逻辑层面,RollCall和afterRollCall函数各占用约22.73%的CPU时间,是核心业务函数的主要性能瓶颈。
| 排名 | 函数/模块 | CPU占用 | 说明 |
|---|---|---|---|
| 1 | runtime.cgocall | 50.00% | MySQL数据库I/O操作 |
| 2 | RollCall | 22.73% | 点名核心业务逻辑 |
| 3 | afterRollCall | 22.73% | 点名后续处理逻辑 |
| 4 | database/sql | ~18% | 数据库查询和事务 |
性能优化思路
针对性能分析发现的瓶颈,提出以下优化方向:
1. 数据库查询优化
- 解决N+1查询问题:使用GORM的
Preload预加载关联数据,将多次查询合并为一次JOIN查询 - 添加数据库索引:为常用查询字段(如
class_id、student_id)建立复合索引
2. 缓存机制
- 对频繁访问的班级花名册数据进行短期缓存(5分钟有效期)
- 减少重复的权重计算和数据库查询
3. 算法优化
- 优化权重计算算法,减少浮点运算
- 对于大规模班级,考虑分批处理
4. 数据序列化优化
- 使用更高效的JSON序列化库(如
jsoniter) - 减少不必要的数据传输
这些优化措施预计可以将点名接口响应时间降低60%以上,并提升系统的并发处理能力。
3.6 单元测试
本项目对核心的点名算法和工具函数进行了全面的单元测试,确保系统的可靠性和正确性。测试覆盖了边界值、正常值和异常情况。
测试覆盖的功能模块
我们对pkg/utils/roll.go中的核心函数进行了测试,包括:
- 基础权重计算(
baseWeight) - 加权随机点名(
randomRoll) - 低分优先算法(
lowPointsFirst) - 疯狂星期四因数判断(
isFactorOf50) - 不同点名模式(
Roll)
核心测试用例展示
1. 边界值测试:空名册
测试当名册为空时,系统是否能正确处理异常情况。
func TestRollWithEmptyRoster(t *testing.T) {
roster := []*common.RosterItem{}
_, err := Roll(roster, common.RollCallMode_RANDOM, common.RandomEventType_NONE)
if err == nil {
t.Error("Expected error for empty roster, got nil")
}
}
测试目的: 验证空名册边界情况的错误处理。
2. 权重计算正确性测试
使用表驱动测试法,验证不同积分和点名次数下的权重计算是否符合预期。
func TestBaseWeight(t *testing.T) {
tests := []struct {
name string
points float64
callCount int64
want float64
}{
{
name: "零积分零次数",
points: 0,
callCount: 0,
want: 1.0, // 1/(1+0+0) = 1
},
{
name: "高积分学生",
points: 10,
callCount: 0,
want: 0.2, // 1/(1+10*0.4+0) = 1/5 = 0.2
},
{
name: "高点名次数学生",
points: 0,
callCount: 5,
want: 0.5, // 1/(1+0+5*0.2) = 1/2 = 0.5
},
{
name: "高积分高次数",
points: 10,
callCount: 5,
want: 0.167, // 1/(1+4+1) ≈ 0.167
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
item := &common.RosterItem{
EnrollmentInfo: &common.Enrollment{
TotalPoints: tt.points,
CallCount: tt.callCount,
},
}
got := baseWeight(item)
// 允许0.01的误差(处理浮点精度问题)
if got < tt.want-0.01 || got > tt.want+0.01 {
t.Errorf("baseWeight() = %v, want %v", got, tt.want)
}
})
}
}
测试数据构造思路:
- 零值测试:积分和点名次数都为0,权重应为最大值1.0
- 单因素测试:只改变积分或点名次数,验证各自的影响
- 组合测试:同时设置高积分和高点名次数,验证公式的综合效果
- 精度处理:允许0.01的浮点误差,避免精度问题导致的测试失败
3. 低分优先算法验证
通过多次运行验证低分优先算法是否真的只从前1/3学生中选择。
func TestLowPointsFirst(t *testing.T) {
// 构造5个学生,积分递增
roster := []*common.RosterItem{
{StudentInfo: &common.Student{StudentID: "001"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 0}},
{StudentInfo: &common.Student{StudentID: "002"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 10}},
{StudentInfo: &common.Student{StudentID: "003"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 20}},
{StudentInfo: &common.Student{StudentID: "004"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 30}},
{StudentInfo: &common.Student{StudentID: "005"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 40}},
}
// 运行100次,确保只从前1/3(前2人)中选择
validStudents := map[string]bool{"001": true, "002": true}
for i := 0; i < 100; i++ {
result := lowPointsFirst(roster)
if !validStudents[result.StudentInfo.StudentID] {
t.Errorf("Selected student %s, should only select from top 1/3",
result.StudentInfo.StudentID)
}
}
}
测试数据构造思路:
- 构造5个积分递增的学生(0, 10, 20, 30, 40)
- 前1/3即前⌈5/3⌉=2人(学号001和002)
- 运行100次验证算法稳定性,确保不会选到其他学生
4. 加权随机的概率分布测试
通过1000次采样统计,验证低分学生是否真的有更高的被选中概率。
func TestWeightedRoll(t *testing.T) {
roster := []*common.RosterItem{
{StudentInfo: &common.Student{StudentID: "001", Name: "低分学生"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 0, CallCount: 0}},
{StudentInfo: &common.Student{StudentID: "002", Name: "高分学生"},
EnrollmentInfo: &common.Enrollment{TotalPoints: 50, CallCount: 10}},
}
// 统计1000次点名结果
count := make(map[string]int)
for i := 0; i < 1000; i++ {
result, _ := Roll(roster, common.RollCallMode_RANDOM, common.RandomEventType_NONE)
count[result.StudentInfo.StudentID]++
}
// 低分学生应该被选中至少600次(60%概率)
if count["001"] < 600 {
t.Errorf("Low points student selected %d times, expected ≥600", count["001"])
}
t.Logf("分布: 低分学生=%d次, 高分学生=%d次", count["001"], count["002"])
}
测试数据构造思路:
- 构造极端对比:0分0次 vs 50分10次
- 通过大量采样(1000次)统计概率分布
- 理论上低分学生权重为1.0,高分学生权重为1/(1+20+2)≈0.043
- 预期低分学生被选中概率约96%,设置阈值为60%(保守估计)
测试结果
运行go test -v ./pkg/utils/,所有测试用例均通过:
=== RUN TestRollWithEmptyRoster
--- PASS: TestRollWithEmptyRoster (0.00s)
=== RUN TestBaseWeight
--- PASS: TestBaseWeight (0.00s)
=== RUN TestLowPointsFirst
--- PASS: TestLowPointsFirst (0.00s)
=== RUN TestWeightedRoll
roll_test.go:163: Selection distribution: 低分学生=963次, 高分学生=37次
--- PASS: TestWeightedRoll (0.00s)
PASS
ok FZUSENekoCaller/pkg/utils 0.897s
关键发现:
- 在1000次加权随机点名中,低分学生被选中963次(96.3%),高分学生仅37次(3.7%)
- 这验证了权重算法的有效性:积分越低,被点名概率越高
- 所有边界值测试和算法正确性测试均通过
测试方法总结
| 测试方法 | 应用场景 | 示例 |
|---|---|---|
| 边界值测试 | 空名册、极端积分值 | 空数组、负数、超大值 |
| 等价类测试 | 不同积分区间 | 0分、低分、中分、高分 |
| 表驱动测试 | 多组输入输出验证 | 权重计算的4组测试数据 |
| 统计测试 | 验证概率分布 | 1000次采样统计选中概率 |
| 重复测试 | 验证算法稳定性 | 100次验证低分优先范围 |
通过这些全面的单元测试,我们确保了核心算法的正确性、稳定性和健壮性,为系统的可靠运行提供了保障。
3.7 贴出代码commit记录

四、总结反思
4.1 本次任务的PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 150 |
| Estimate | 估计这个任务需要多少时间 | 60 | 80 |
| Development | 开发 | 600 | 720 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 200 |
| Design Spec | 生成设计文档 | 120 | 100 |
| Design Review | 设计复审 | 60 | 50 |
| Coding Standard | 代码规范 | 30 | 40 |
| Design | 具体设计 | 240 | 300 |
| Coding | 具体编码 | 480 | 550 |
| Code Review | 代码复审 | 60 | 80 |
| Test | 测试 | 120 | 150 |
| Reporting | 报告 | 60 | 70 |
| Test Report | 测试报告 | 30 | 40 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 80 |
| 合计 | 2130 | 2530 |
4.2 学习进度条(每周追加)
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 500 | 500 | 5 | 5 | 熟悉Go语言和Vue.js框架 |
| 2 | 1000 | 1500 | 12 | 17 | 掌握GORM ORM框架和数据库设计 |
| 3 | 800 | 2300 | 10 | 27 | 实现加权随机算法和事件系统 |
| 4 | 600 | 2900 | 8 | 35 | 前端界面开发和API对接 |
4.3 最初想象中的产品形态、原型设计作品、软件开发成果三者的差距如何?
最初想象的产品较为简单,主要关注基本点名功能。但在开发过程中,我们不断扩展了趣味性功能,如多种随机事件、转移权机制等,使得产品更加丰富。原型设计阶段对交互细节考虑不足,在实际开发中进行了多次调整。总体而言,开发成果超出了最初预期,但也发现了原型设计的重要性。
4.4 评价你的队友
郑伟:队友值得学习的地方是前端界面设计能力和用户体验考虑;需要改进的地方是代码结构可以更模块化。
周晨烁:队友值得学习的地方是扎实的算法实现能力和数据库设计思维;需要改进的地方是代码注释可以更详细。
4.5 结对编程作业心得体会
郑伟:
本次《课堂随机点名系统》的结对编程任务,对我个人而言是一次非常宝贵的实战成长经历。我主要负责了后端业务逻辑的实现与数据库设计工作。
在项目初期,面对复杂的需求(特别是积分规则和多种随机事件),我深刻体会到了前期需求分析和原型设计的重要性。我们团队在这一环节花费了大量时间去理清业务逻辑,确保后续算法设计的方向正确。
在核心的加权随机点名算法实现中,我学习到如何将抽象的规则(如“积分越高,被点概率越低”)通过数学模型量化,最终通过反比例函数结合积分和点名次数来计算权重。这让我对算法优化和模型构建有了更实际的理解。
整个结对过程让我清晰地认识到,团队协作不只是分摊工作量,更是思维的碰撞和互补。搭档在前台界面设计和交互体验上的独到见解,也反过来促进了我对后端数据接口设计更加规范化和人性化。我将把这次学习到的模块化设计思路和Git版本管理经验,应用到未来的学习和软件开发实践中。
周晨烁:
在本次《课堂随机点名系统》的结对编程任务中,我主要承担了前端用户界面的设计、实现以及后端的数据库迁移与优化工作。这是一次将设计理念转化为实际产品的宝贵实践。
在前端开发方面,我负责了原型设计的高还原度实现,并致力于提升用户交互体验。通过对原型设计工具的学习,我将最初的原型图转化为实际的 Web 或小程序界面,确保了点名、查看积分排名的操作流程简洁流畅。尤其在积分排名可视化模块,我尝试使用了图表库来清晰展示积分和随机点名次数,这对我提升前端的数据展示能力帮助很大。
在数据库方面,我的主要工作是协助将名单数据从 Excel 文件导入并迁移到 FREE Online 数据库中,并对查询性能进行了初步优化。我学习了如何在实际环境中配置和管理远程数据库连接,处理数据类型转换,并配合设计的算法,确保了数据查询的高效性,特别是对于积分排名这种涉及复杂排序和聚合查询的操作,保障了系统的响应速度。
本次结对编程让我深刻体会到前后台协作的重要性。前端界面的实现往往依赖于后端接口的规范性,而数据库的优化也直接关系到用户体验。通过与搭档的紧密沟通和协作,我们能够快速定位并解决技术难题,实现了功能间的无缝对接。我意识到,一个优秀的软件项目需要团队成员具备多方面的技能和高度的责任心。我将总结这次经验,在后续的项目中更加注重技术选型的合理性和代码的健壮性。

















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









