







 本文探讨了使用深度学习中的LSTM模型进行序列预测,并介绍了如何优化LSTM权重初始化以获得与Keras类似的效果。此外,作者还引入了注意力机制,通过self-attention增强模型对序列周期和相似性的捕捉能力。网络结构包括LSTM层和注意力层,其中注意力层通过计算序列元素间的关系并进行归一化来提取关键特征。同时,文章还简要概述了self-attention的工作原理及其矩阵乘法表示,以及multi-head self-attention的概念。最后,提到了位置编码的重要性,以补充attention缺乏的位置信息。
本文探讨了使用深度学习中的LSTM模型进行序列预测,并介绍了如何优化LSTM权重初始化以获得与Keras类似的效果。此外,作者还引入了注意力机制,通过self-attention增强模型对序列周期和相似性的捕捉能力。网络结构包括LSTM层和注意力层,其中注意力层通过计算序列元素间的关系并进行归一化来提取关键特征。同时,文章还简要概述了self-attention的工作原理及其矩阵乘法表示,以及multi-head self-attention的概念。最后,提到了位置编码的重要性,以补充attention缺乏的位置信息。
笔者在重新尝试用深度学习的各个模型对序列进行预测,就LSTM进行一些使用记录
一、一些优化
- 和keras一样的权重初始化
- 有时候我们torch训练的LSTM, 没有keras好,可以将权重按keras的方式进行初始化
- 增加attention 捕捉序列的周期与相似性
- 尝试用self-attention
二、网络结构LSTM+Attention
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import typing as typ
import numpy as np
from tqdm import tqdm
from sklearn.model_selection import KFold
from collections import OrderedDict
class LSTMRegressor(nn.Module):
def __init__(self, input_size, hidden_size=128):
super(LSTMRegressor, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True, bidirectional=False)
self.header = nn.Sequential(OrderedDict([
('fc1', nn.Linear(hidden_size, 32)),
('relu1', nn.ReLU(inplace=True)),
('dropout', nn.Dropout(0.01)),
('fc2', nn.Linear(32, 1)),
('relu2', nn.ReLU(inplace=True)),
]))
self.__weight_init()
# attention
self.attn_ly = nn.Linear(hidden_size, 1)
self.sft = nn.Softmax(dim=1)
def attention_net(self, lstm_output):
# print('lstm_output', lstm_output.shape) # batch_size, time_step, hidden_size * layer_size
attn_tanh = torch.tanh(self.attn_ly(lstm_output)) # batch_size, time_step, 1
sft_res = self.sft(attn_tanh) # batch_size, time_step, 1
attn_output = torch.sum(sft_res * lstm_output, 1) # batch_size, hidden_size
return attn_output
def forward(self, x):
x_out, (hn, cn) = self.lstm(x)
x_out = self.attention_net(x_out)
x_out = self.header(x_out)
return x_out
def __weight_init(self):
"""
Tensorflow/Keras-like initialization
"""
for name, p in self.named_parameters():
if 'lstm' in name:
if 'weight_ih' in name:
nn.init.xavier_uniform_(p.data)
elif 'weight_hh' in name:
nn.init.orthogonal_(p.data)
elif 'bias_ih' in name:
p.data.fill_(0)
# Set forget-gate bias to 1
n = p.size(0)
p.data[(n // 4):(n // 2)].fill_(1)
elif 'bias_hh' in name:
p.data.fill_(0)
elif 'fc' in name:
if 'weight' in name:
nn.init.xavier_uniform_(p.data)
elif 'bias' in name:
p.data.fill_(0)
三、Self-attention
3.1 原理
考虑全部序列
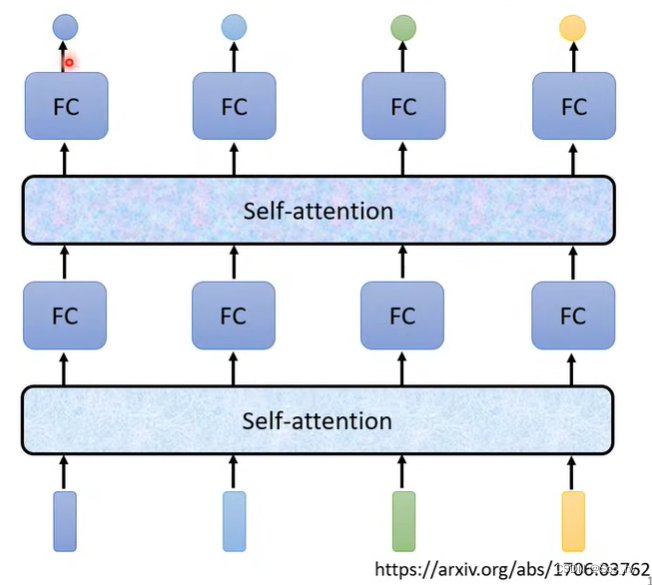
计算序列中元素之间的关系
α
\alpha
α, 存在较多的方法进行计算,一种是直接进行乘积Dot-product,一种是concat后做一个激活函数。在self-attention中使用的是左边的进行乘积Dot-product的方法。

以序列第一个值为例,输入
q
1
=
W
q
a
1
q_1=\bf W^q\bf a^1
q1=Wqa1, 计算每个值和第一个值之间的相关性(用k矩阵抽取核心
K
2
=
W
2
a
2
;
\bf K^2=\bf W^2 \bf a^2;
K2=W2a2; 然后与q矩阵相乘
α
1
,
2
=
K
2
q
1
\alpha _{1, 2}=\bf K^2 q_1
α1,2=K2q1),抽取出相关性后,用soft-max进行归一化,增大值之间的距离。
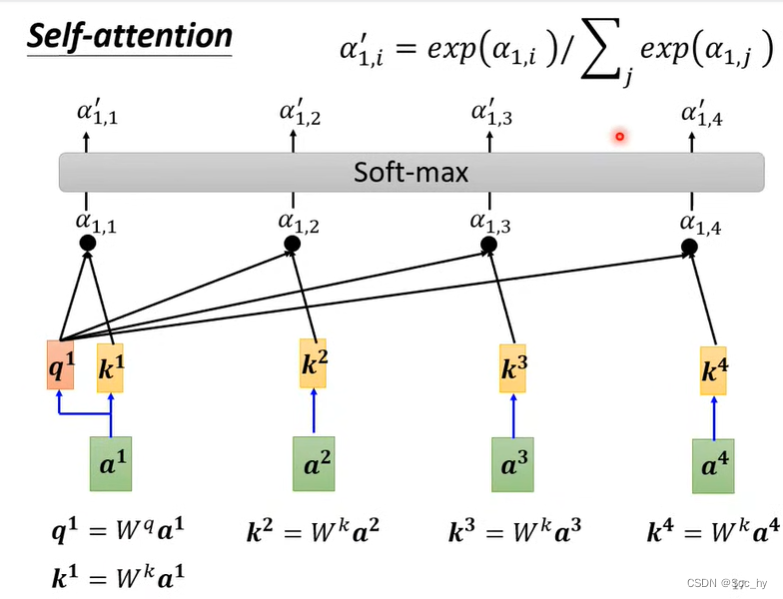
有了相关性之后对每个值(
v
2
=
W
v
a
2
\bf v^2=W^va^2\bf
v2=Wva2)都取相应相关性(
v
2
α
1
,
2
/
\bf v^2 \alpha^/_{1, 2}
v2α1,2/)的特征做累和
(
b
1
=
∑
i
α
1
,
i
/
v
i
b^1=\sum_i{\alpha^/_{1,i}\bf v^i}
b1=∑iα1,i/vi)
然后依次的获取
b
2
b
3
b
4
b^2\ b^3\ b^4
b2 b3 b4
3.2 原理转矩阵乘法
a i a^i ai合并成矩阵 I I I,所以
- K i K^i Ki 可以合并成 K = W k I K=W^kI K=WkI
- q i q^i qi 可以合并成 Q = W q I Q=W^qI Q=WqI
- v i v^i vi 可以合并成 V = W q I V=W^qI V=WqI
- α i , j \alpha _{i, j} αi,j 可以合并成 A = K T Q A=K^TQ A=KTQ
- α i , j / \alpha^/ _{i, j} αi,j/ 可以转换成 A / A^/ A/
- b i b^i bi 最终的输出可以转换成 O = V A / O=VA^/ O=VA/
所以未知参数仅仅 W k W q W v W^k \ W^q \ W^v Wk Wq Wv
3.3 Multi-head self-attention
其实就是多个q去找相关性。
-
q
i
q^i
qi ->
Q
=
W
q
I
Q=W^qI
Q=WqI
- 分别用矩阵乘 Q Q Q以得到两个Q
- Q 1 = W q . 1 Q Q^1 = W^{q.1}Q Q1=Wq.1Q
- Q 2 = W q , 2 Q Q^2 = W^{q, 2}Q Q2=Wq,2Q
-
K
i
K^i
Ki ->
K
=
W
k
I
K=W^kI
K=WkI
- 分别用矩阵乘 K K K以得到两个K
- K 1 = W k . 1 K K^1 = W^{k.1}K K1=Wk.1K
- K 2 = W k , 2 K K^2 = W^{k, 2}K K2=Wk,2K
-
V
i
V^i
Vi ->
V
=
W
v
I
V=W^vI
V=WvI
- 分别用矩阵乘 V V V以得到两个V
- V 1 = W v . 1 V V^1 = W^{v.1}V V1=Wv.1V
- V 2 = W v , 2 V V^2 = W^{v, 2}V V2=Wv,2V
- 算出两个O
- A 1 / = s o f t m a x ( K 1 T Q 1 ) O 1 = V 1 A 1 / A^/_1= softmax({K^{1}}^TQ^1) \ \ \ O^1=V^1{A^1}^/ A1/=softmax(K1TQ1) O1=V1A1/
- A 2 / = s o f t m a x ( K 2 T Q 2 ) O 2 = V 2 A 2 / A^/_2= softmax({K^{2}}^TQ^2) \ \ \ O^2=V^2{A^2}^/ A2/=softmax(K2TQ2) O2=V2A2/
- 然后concat在一起
- O = W O c o n c a t ( O 1 , O 2 ) O=W^Oconcat(O^1, O^2) O=WOconcat(O1,O2)
3.4 位置的Encoding
因为前面attention并没有考虑位置的信息,所以可以加入位置的信息
- 在输入中加入到位置信息
e
i
e^i
ei
- e i + a i e^i + a^i ei+ai
- 原始论文使用的是 c o n c a t ( s i n ( i d x ) , c o s ( i d x ) ) concat(sin(idx), cos(idx)) concat(sin(idx),cos(idx))


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











