



tips
序列到序列模型,在沐神的《动手深度学习》,有一个从零开始手写的例子。额,我之前在RNN中也讲我,对于我这么基础这么差,编码又很菜的人来说,消化起来,可以说是无从下手。所以手搓了现在序列到序列模型的代码,同样的,还是以单个句子为例。
序列到序列模型的核心
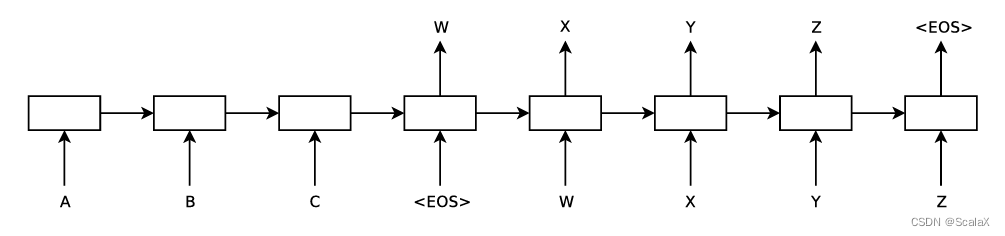
1、在我看来必须先理解encoder、decoder的思维
2、其次本质上它与RNN的方式是很类似的,就算是序列到序列其实也并没有脱离
3、每个单元可以有GRU、LSTM作为长序列的计算,示例中是用的GRU
4、评价该模型的好与不好,此处用了BLEU
Encoder 与 Decoder
关于父类的设计(如果在Transformer、BERT手搓的时候,需要改变父类函数的形式参数,再改就是,反正先把基类的基础打好。)这里是copy的沐神代码, 核心的东西,就是encoder要向decoder传递它结束后的隐藏状态,因此encoder在设计之初,并不考虑设计线性输出。
from torch import nn
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, x, *args):
raise NotImplementedError
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, enc_valid_lens, *args):
raise NotImplementedError
def forward(self, x, state):
raise NotImplementedError
class EncoderAndDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderAndDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_x, dec_x):
enc_outputs = self.encoder(enc_x)
enc_state = self.decoder.init_state(enc_outputs, )
return self.decoder(dec_x, enc_state)
Seq2Seq的单句子训练与预测
这里只编写了大致的代码,训练出来的结果非常感人,有的时候好得很,有的时候驴唇不对马嘴。
import collections
import math
import torch
from torch import nn
from tran_2_processing import read_tokens, Vocab
from tran_1_encoder_decoder import Encoder, Decoder, EncoderAndDecoder
class Seq2SeqEncoder(Encoder):
def __init__(self, vocab_size, embedding_size, num_hidden, n_layers, device, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embedding_dim=embedding_size, device=device)
self.rnn = nn.GRU(embedding_size, num_hidden, num_layers=n_layers, device=device)
def forward(self, x, *args):
x = self.embedding(x)
x = x.permute(1, 0, 2)
y, state = self.rnn(x)
return y, state
class Seq2SeqDecoder(Decoder):
def __init__(self, vocab_size, embedding_size, num_hidden, n_layers, device, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embedding_dim=embedding_size, device=device)
self.rnn = nn.GRU(embedding_size + num_hidden, num_hidden, num_layers=n_layers, device=device)
self.fc = nn.Linear(num_hidden, vocab_size, device=device)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, x, state):
x = self.embedding(x)
x = x.permute(1, 0, 2)
context = state[-1].repeat(x.shape[0], 1, 1)
x_context = torch.cat([x, context], dim=2)
output, state = self.rnn(x_context, state)
output = self.fc(output).permute(1, 2, 0)
return output, state
def bleu(pred_seq, label_seq, k): # @save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
def train_seq2seq(net, inputs, outputs, lr, epochs, device):
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
net.train()
for epoch in range(epochs):
optimizer.zero_grad()
y_hat, _ = net(inputs, outputs)
loss = criterion(y_hat, outputs)
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f"epoch {epoch + 1} / {epochs} --- loss:{loss.item():.4f}")
def predict_seq2seq(model, src_inputs, vocab_inp, vocab_out, num_steps, device):
model.eval()
src_tokens = [src_inputs.split()]
src_inputs = torch.tensor([vocab_inp[item] for item in src_tokens], device=device)
_, state = model.encoder(src_inputs)
src_outputs = [[vocab_out['<bos>']]]
pre_out = []
# while src_outputs[-1] != vocab_out['<eos>']:
for _ in range(num_steps):
y, state = model.decoder(torch.tensor(src_outputs, device=device), state)
src_outputs = torch.argmax(y, dim=1)
pre = src_outputs.squeeze(0).item()
pre_out.append(pre)
if pre == vocab_out['<eos>']:
break
return " ".join([vocab_out.to_tokens(index) for index in pre_out])
if __name__ == '__main__':
device = torch.device("cuda:0")
# en_inp = 'it is a nice day today\t<bos> I think it is not <pad> the weather is so bad <eos>'
en_inp = 'I like apple\t<bos> you are newton <eos>'
input_txt, output_txt = en_inp.split("\t")
en_inp_tokens = [input_txt.split()]
en_out_tokens = [output_txt.split()]
vocab_inp = Vocab(en_inp_tokens, reserved_tokens=[])
vocab_out = Vocab(en_out_tokens, reserved_tokens=['<bos>', '<eos>'])
encoder = Seq2SeqEncoder(len(vocab_inp), 4, 10, 2, device=device)
decoder = Seq2SeqDecoder(len(vocab_out), 4, 10, 2, device=device)
net = EncoderAndDecoder(encoder, decoder)
inputs = torch.tensor([vocab_inp[item] for item in en_inp_tokens], device=device)
outputs = torch.tensor([vocab_out[item] for item in en_out_tokens], device=device)
train_seq2seq(net, inputs, outputs, 0.01, 1000, device=device)
result = predict_seq2seq(net, "I like apple", vocab_inp, vocab_out, 20, device=device)
print(result)
score = bleu(result, output_txt, 3)
print(f"bleu:{score:.4f}")
数据预处理的代码:
import collections
import re
import torch
def get_corpus_from_file(path, token="word"):
lines = read_txt(path)
tokens = tokenize(lines, token)
vocab = Vocab(tokens)
return vocab
# 去掉文本中非文本与空格的内容
def read_txt(path):
with open(path, "r") as f:
lines = f.readlines()
return [re.sub("[^A-Za-z’]+", " ", line).strip().lower() for line in lines]
# 选择以词处理,还是字符处理方式
def tokenize(lines, token="word"):
if token == "word":
return [line.split() for line in lines]
elif token == "char":
return [list(line) for line in lines]
else:
print("未知类别")
return []
# 统计词频
def count_corpus(tokens):
# 如果读取的词频内容长度为0,或者内部是一个列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 如果内部还有列表则继续遍历
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
# 设计文本词库
class Vocab:
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
counter = count_corpus(tokens)
self._token_freq = sorted(counter.items(), key=lambda x: x[1], reverse=True)
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freq:
if freq < min_freq:
break
if token not in self.idx_to_token:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, 0)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, index):
if not isinstance(index, (list, tuple)):
return self.idx_to_token[index]
return [self.idx_to_token[item] for item in index]
def build_array_nmt(lines, vocab, num_steps):
lines = [vocab[l] for l in lines]
lines = [l + [vocab['<eos>']] for l in lines]
array = []
for line in lines:
if num_steps < len(line):
### TODO 不知道为何不能加vocab['<pad>']
line = line[:num_steps]
else:
line = line + [vocab['<pad>']] * (num_steps - len(line))
array.append(line)
valid_len = [(sum(1 for num in line if num != 2)) for line in array]
return torch.tensor(array), torch.tensor(valid_len)
def load_data_nmt(batch_size, num_steps):
lines = read_txt("word.txt")
tokens = tokenize(lines)
is_train = True
vocab_tokens = Vocab(tokens, min_freq=1, reserved_tokens=['<pad>', '<bos>', '<eos>'])
token_array, token_valid_len = build_array_nmt(tokens, vocab_tokens, num_steps)
print(token_array)
print(token_valid_len)
dataset = torch.utils.data.TensorDataset(*token_array)
data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=is_train)
# print([item for item in data_iter][0][2])
return data_iter, vocab_tokens
关于《动手深度学习》序列到序列(Seq2Seq)的一部分笔记:(主要是关于 d2l.load_data_nmt) 希望对后续要学习的人有一定的帮助。
# d2l.load_data_nmt 这个函数主要包含以下几个功能:
# 1、获取原始文本信息,并将其逐行分离、以tab分英法两种文字、以空格分词到src和tgt
# 2、对两个词表进行 tokenize 获取 idx_to_token 和 token_to_idx, 并追加 <eos> 结束 <bos> 开始 <pad> 填充 (包含以前的<unk>)
# 3、将src和tgt进行 token_to_idx 化,并在每行末尾追加<eos>结尾
# 4、通过num_steps 每行只取得前num_steps条信息,如果长度不及,则用<pad>填充
# 5、统计token_to_idx 化后的词表和其每行的有效内容长度 分别是 src,src_len,tgt,tgt_len
# 6、将多组src,src_len,tgt,tgt_len 打包为torch.utils.data.TensorDataset
# 7、再封装为torch.utils.data.DataLoader(此处传递的batch_size为批量样本)
# 8、返回值 为 DataLoader 的train_iter, token_to_idx 化后的词表src_vocab, tgt_vocab


















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言







