




参考视频
模型压缩架构和流程介绍!量化/剪枝/蒸馏/二值化4件套!【推理系统】模型压缩第01篇_哔哩哔哩_bilibili
23年的视频笔记,不知道现在还是否适用,总之就当梳理用
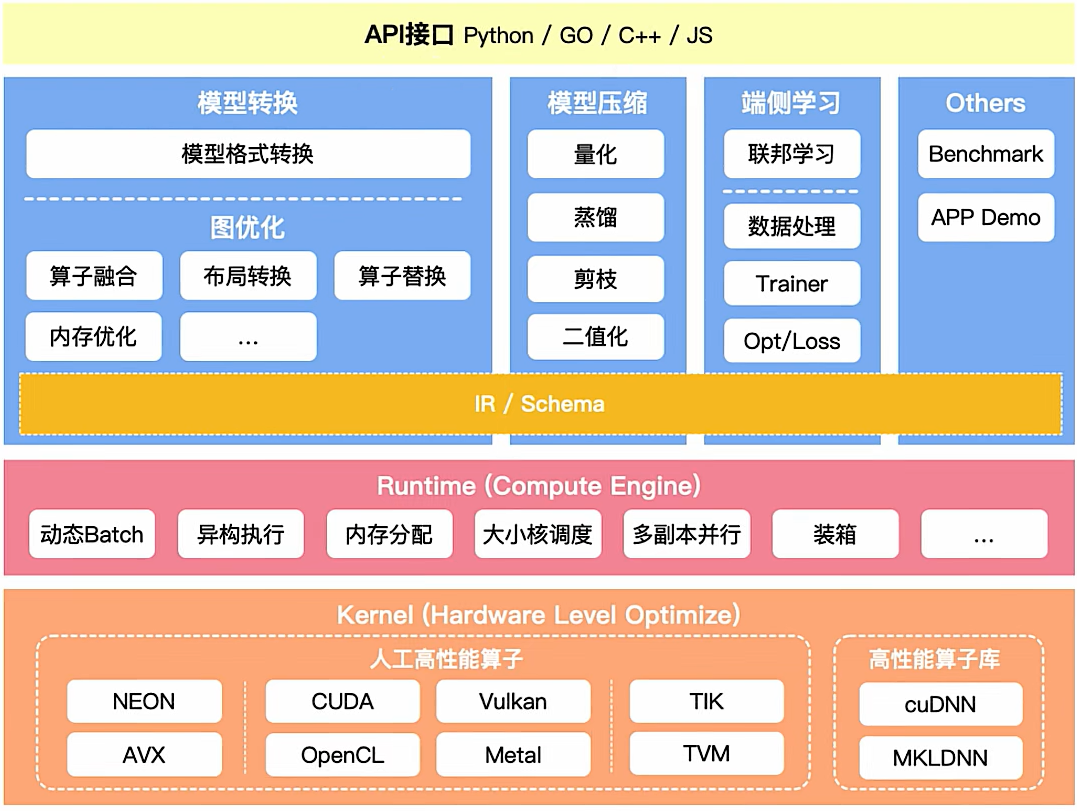
推理流程
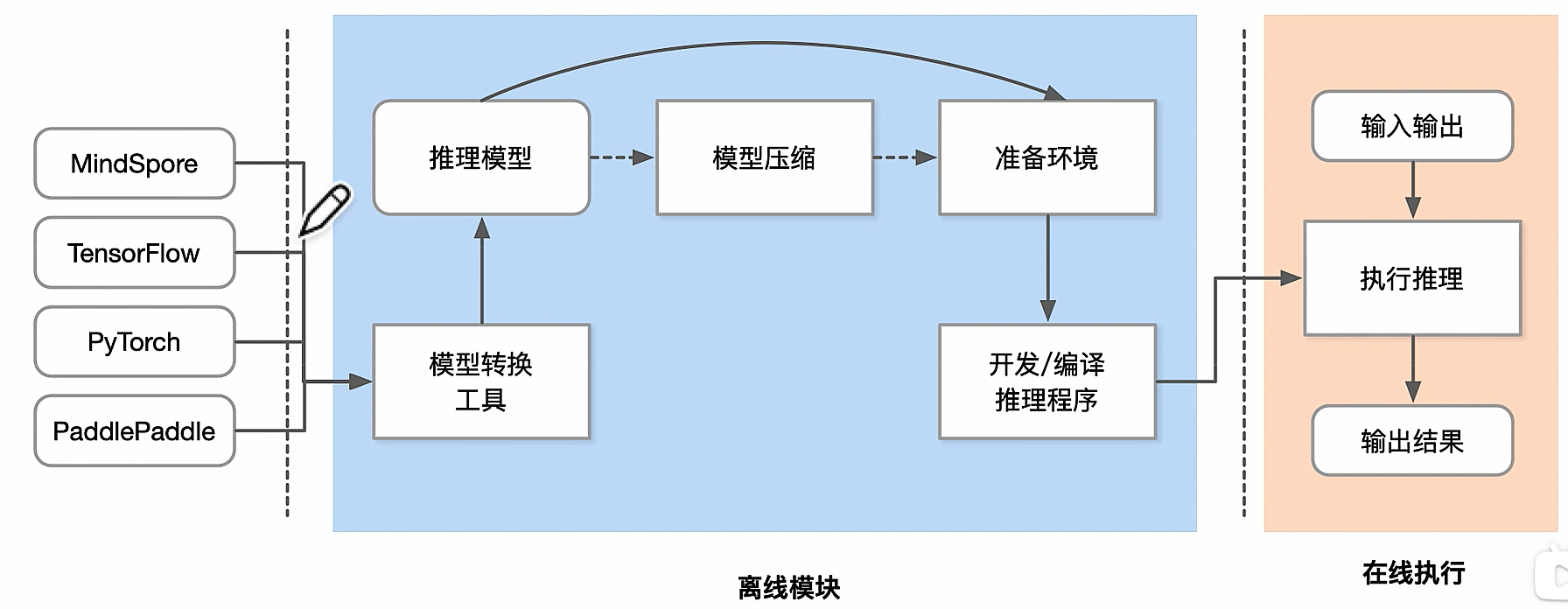
模型小型化
基础参数概念
CNN小型化结构
Transformer 小型化结构
低比特量化(Low-bit Quantization)
低比特量化是一种将神经网络权重和激活值从高精度(如 32-bit 浮点数)降低到较低比特(如 8-bit、4-bit,甚至 1-bit)的技术。这样可以减少存储需求和计算复杂度,提高模型在边缘设备上的运行效率,但往往带来精度损失。
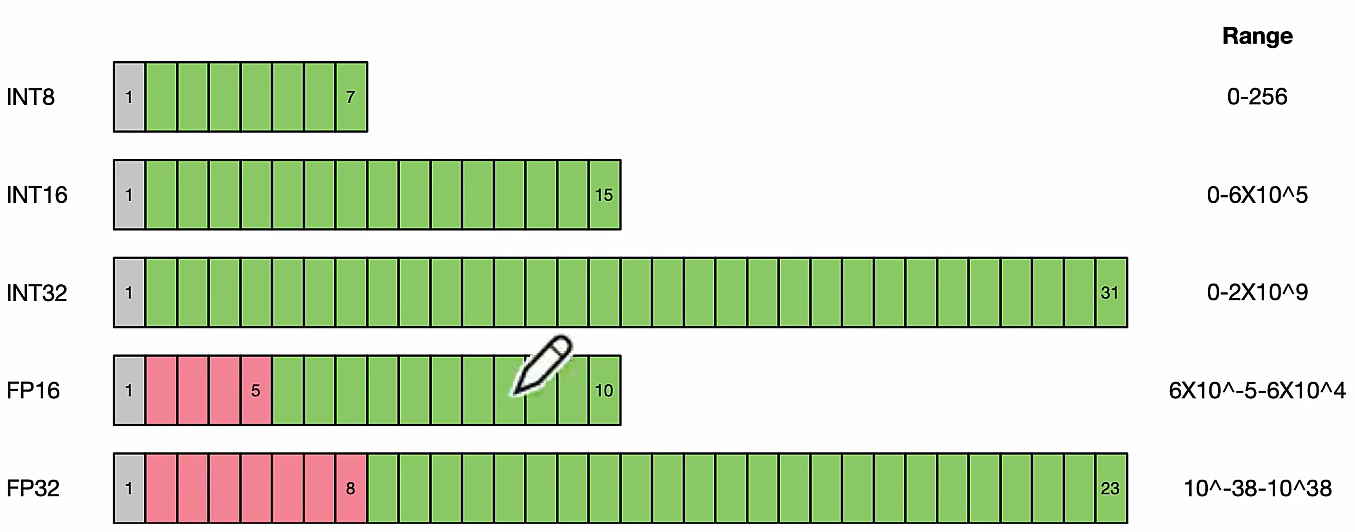
一般情况是FP32和FP1 6的混合精度,但是模型量化一般是降到≤FP16

挑战



原理
模型量化桥接了定点与浮点,建立了一种有效的数据映射关系,使得以较小的精度损失代价获得了较好的收益
主要为线性量化

映射:把一堆数据映射到一个具体的范围(上图中是-127-127)
截断: 设置最小和最大值,不在范围内的丢掉
线性量化可以分为对称量化(int)和非对称量化(uint)
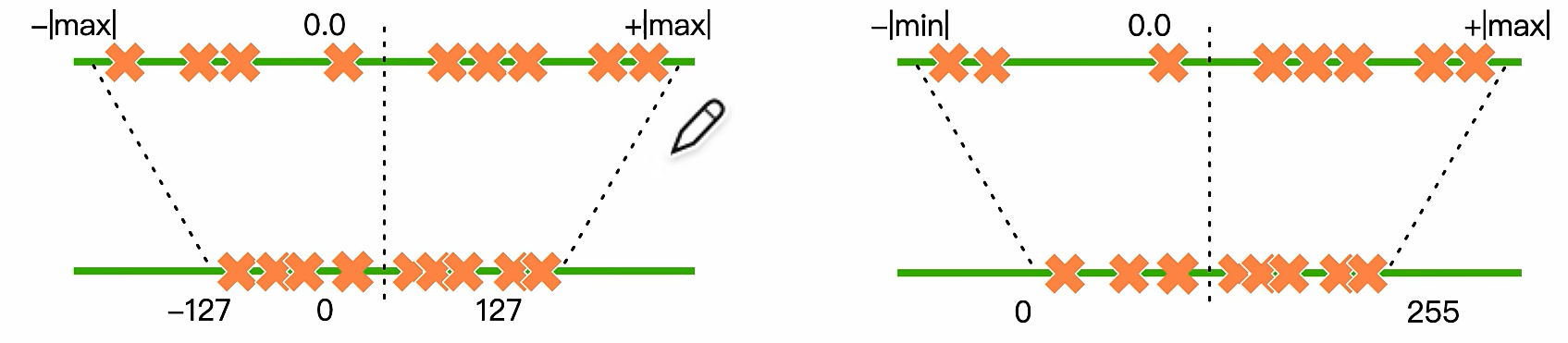
映射转换

R映射到Q叫量化
Q映射到R是反量化
目的:求S和Z


offset就是刚刚的z
分类
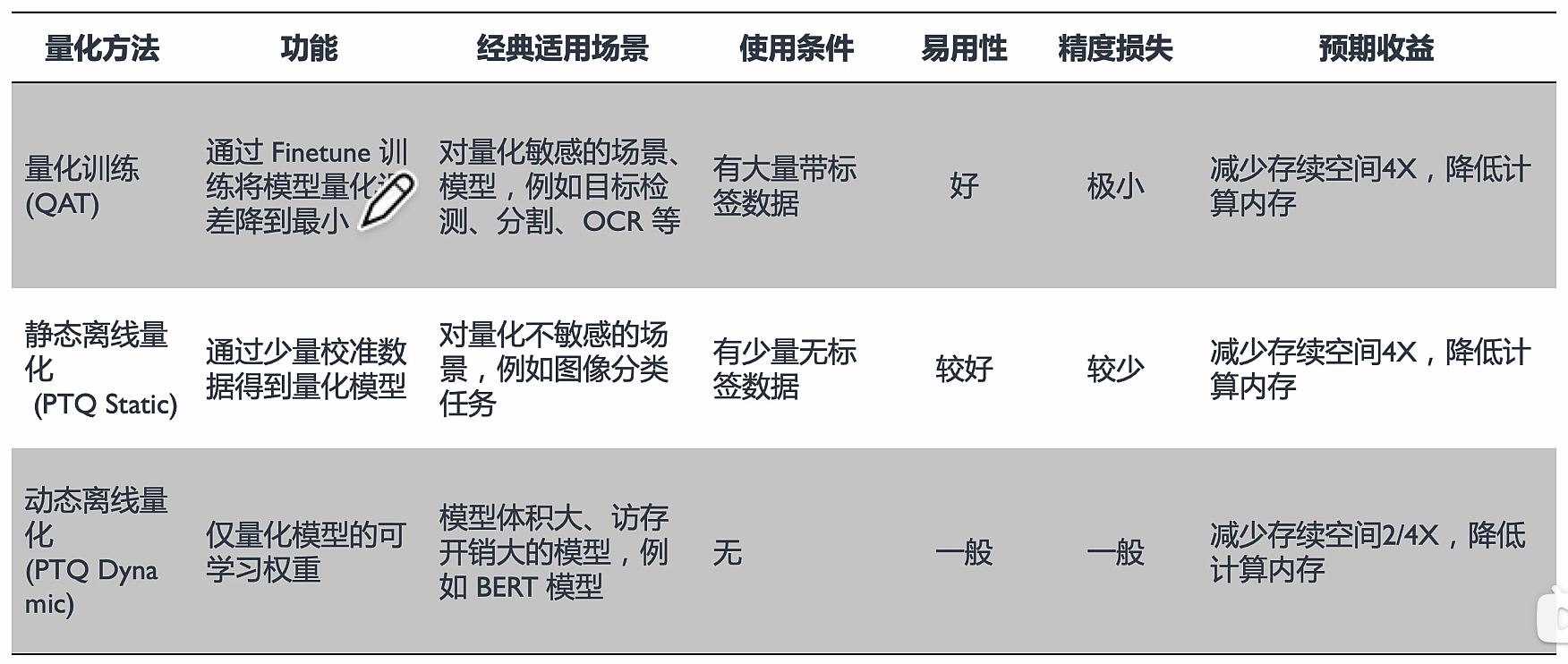
Quantization Aware Training 感知量化 QAT
总之就是学习误差,进而降低误差
量化训练让模型感知量化运算对模型精度带来的影响,通过 finetune 训练降低量化误差。

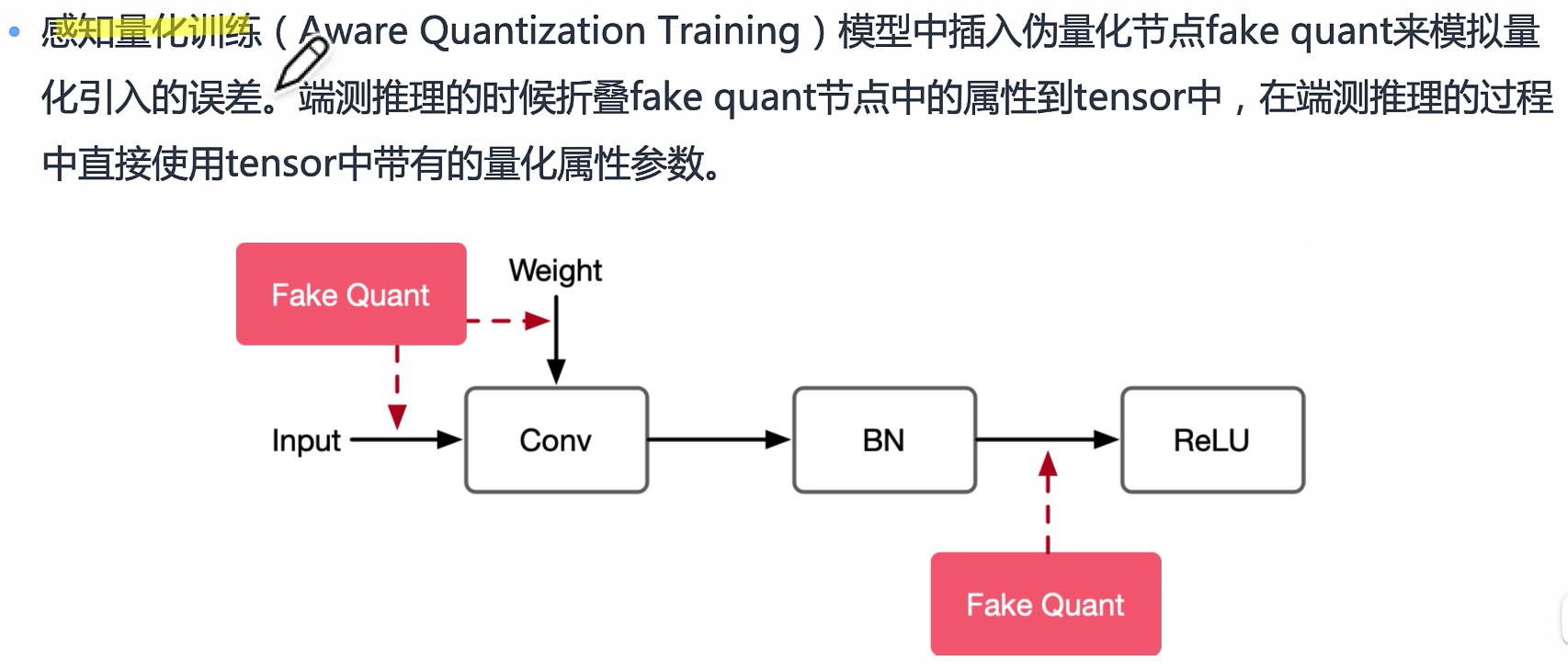
伪量化节点

节点插入地方: 一般会在密集计算算子,激活算子,网络输入输出等地方插入伪量化节点
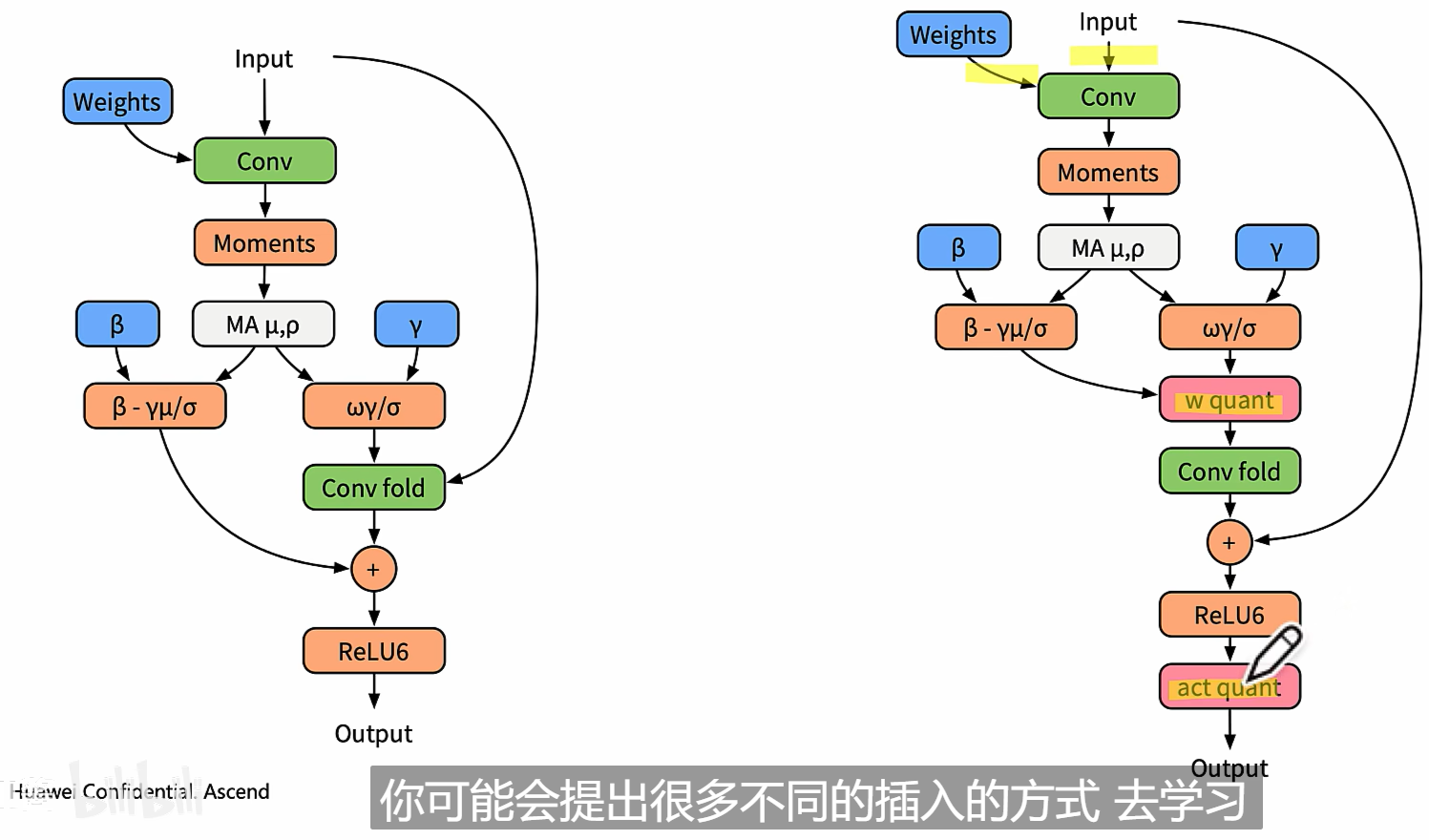 BN量化
BN量化
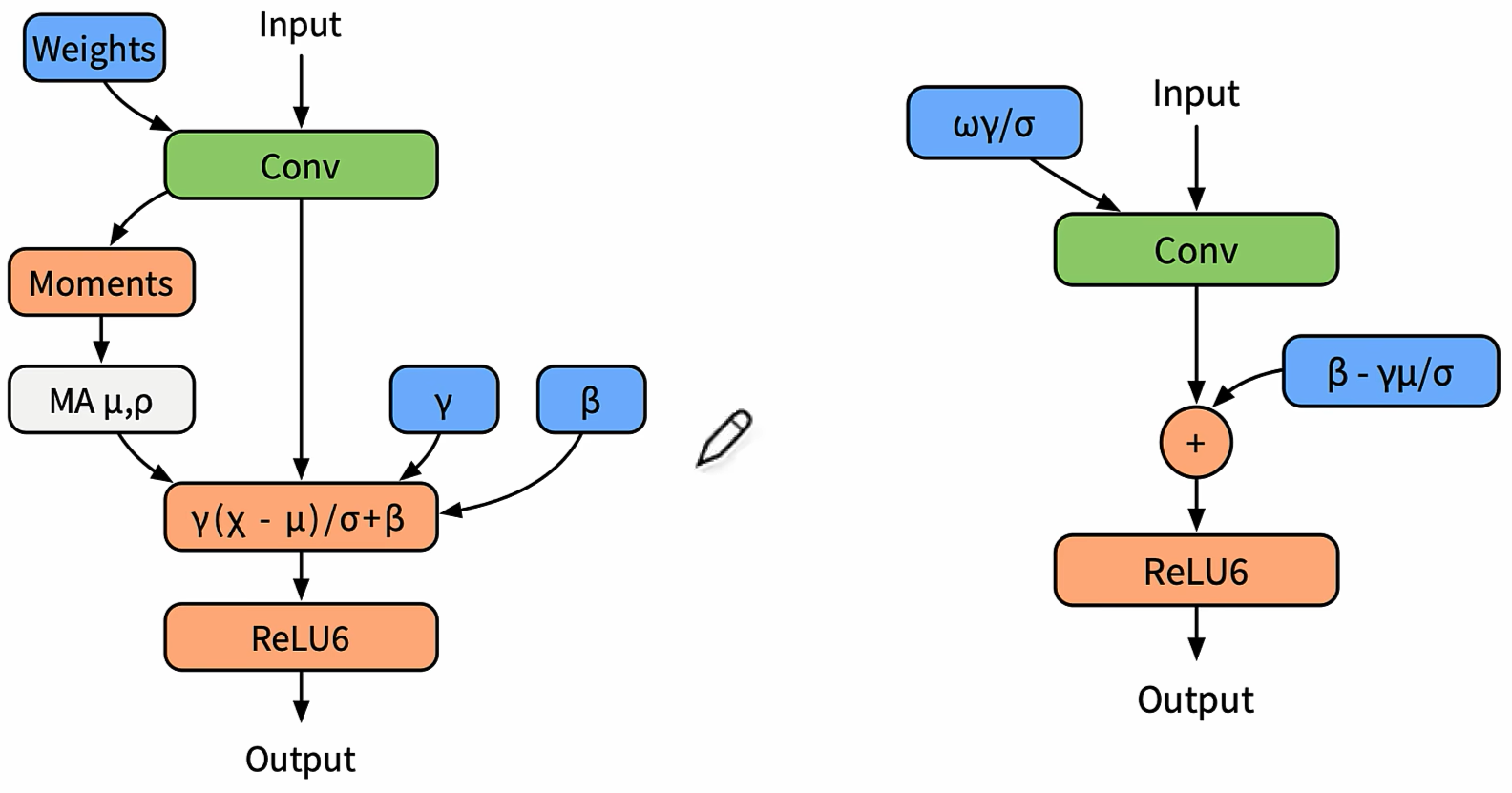
正向传播
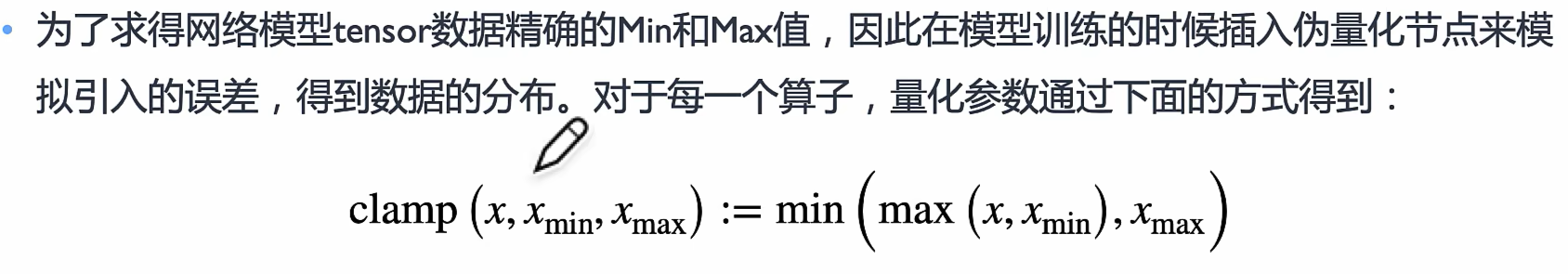
x是输入数据
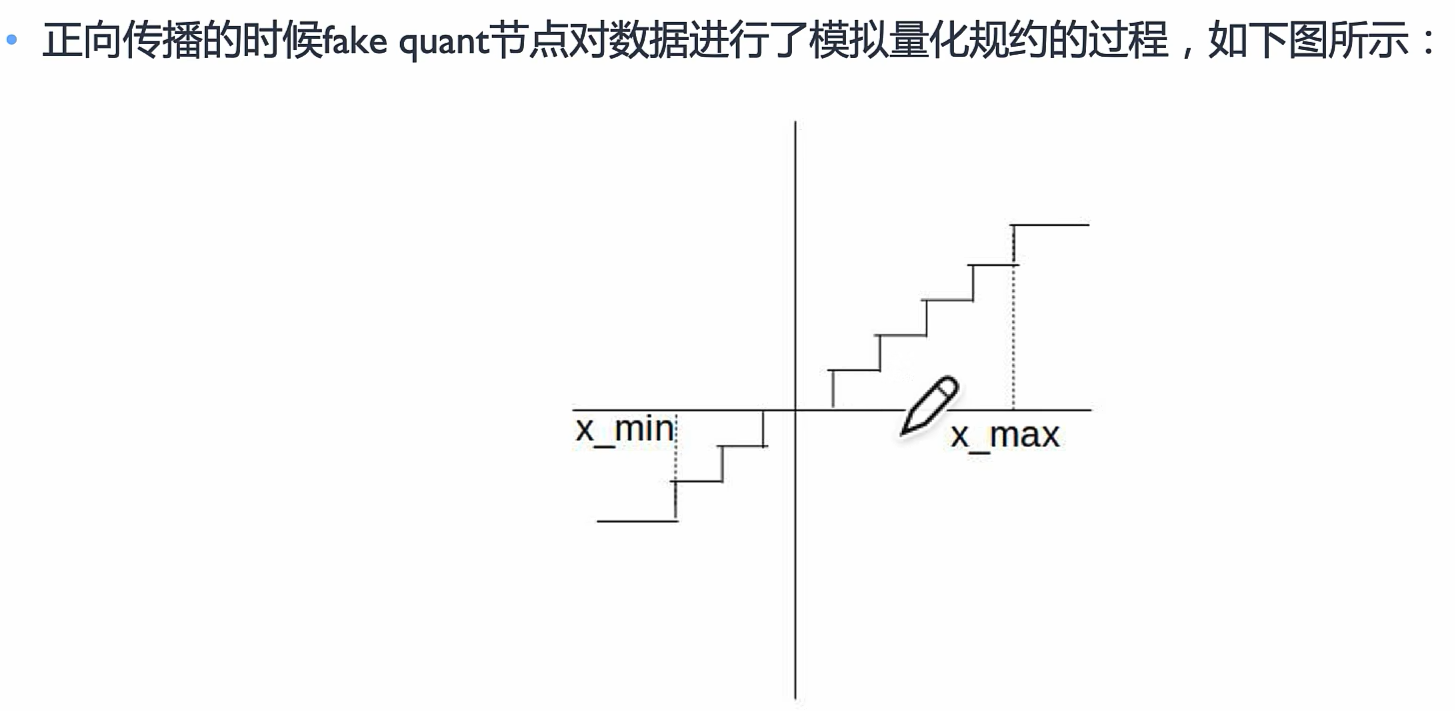
线性数据经过伪量化算子变成阶梯型
反向传播

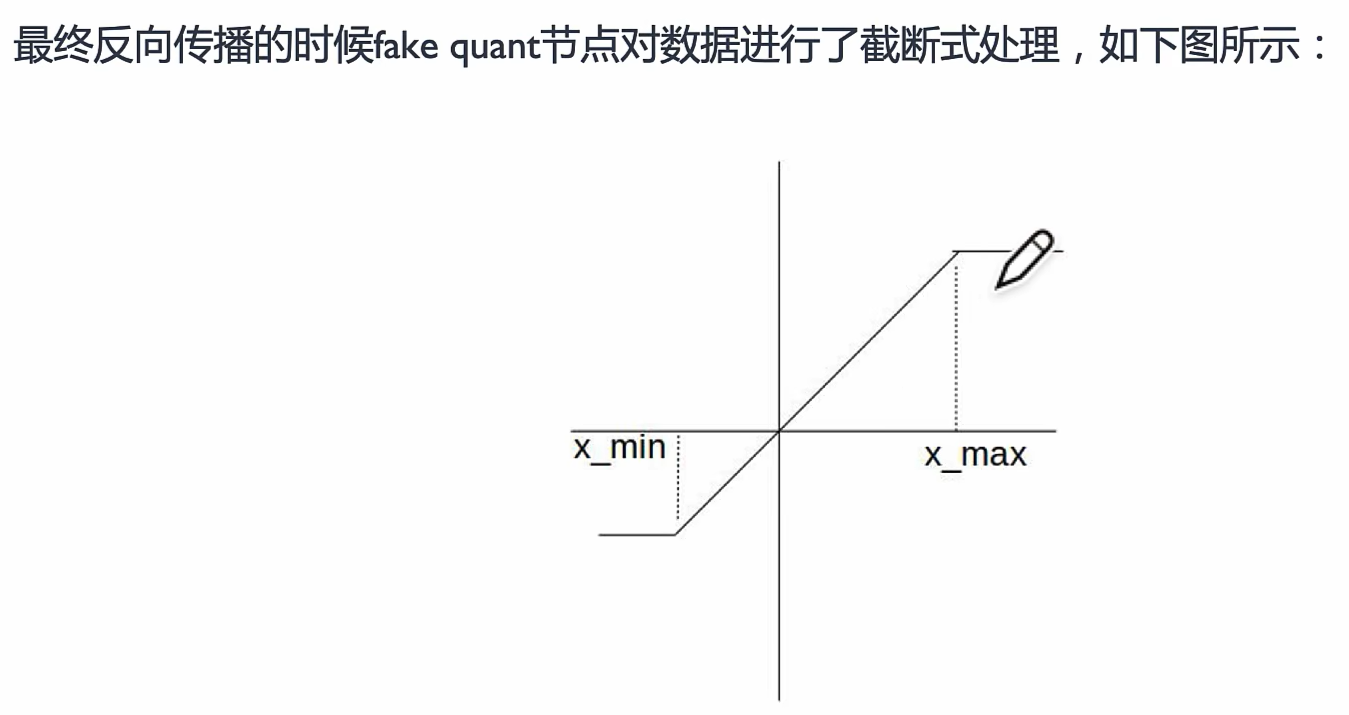
更新Min和Max

训练流程
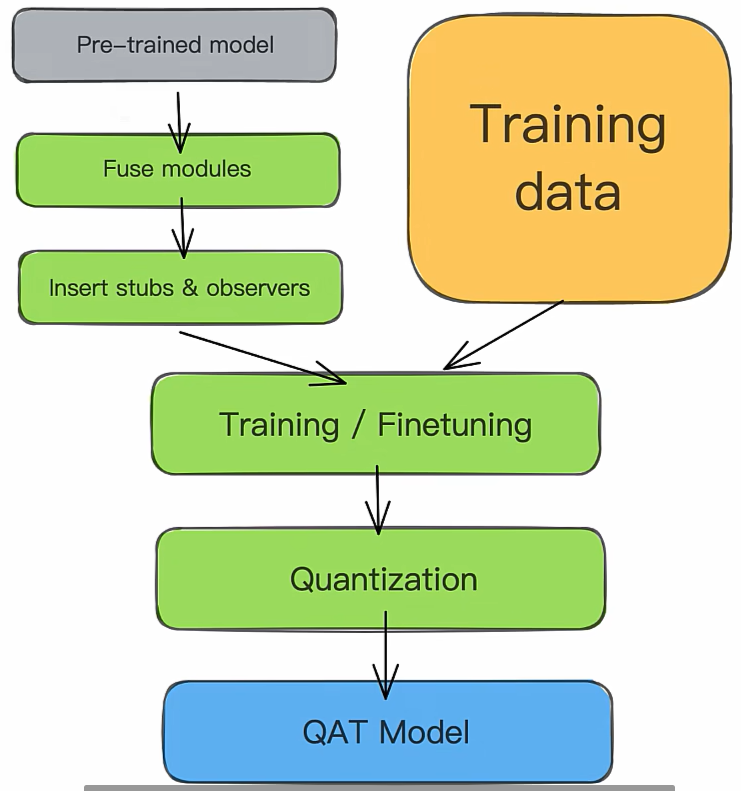
Insert stubs/observers: 伪量化算子
注意! QAT模型要经过转换之后才能执行,去掉冗余伪量化算子

Post-Training Quantization 训练后量化 PTQ
动态离线量化 Dynamic
动态离线量化仅将模型中特定算子的权重从FP32类型映射成 INT8/16 类型。


静态离线量化 Static
现在市面上大部分推理引擎或者框架都采用这个离线量化
静态离线量化使用少量无标签校准数据,采用KL 散度等方法计算量化比例因子。


无标签数据主要用在衡量scale(用真实的数据厂家获取scale的缩放因子)
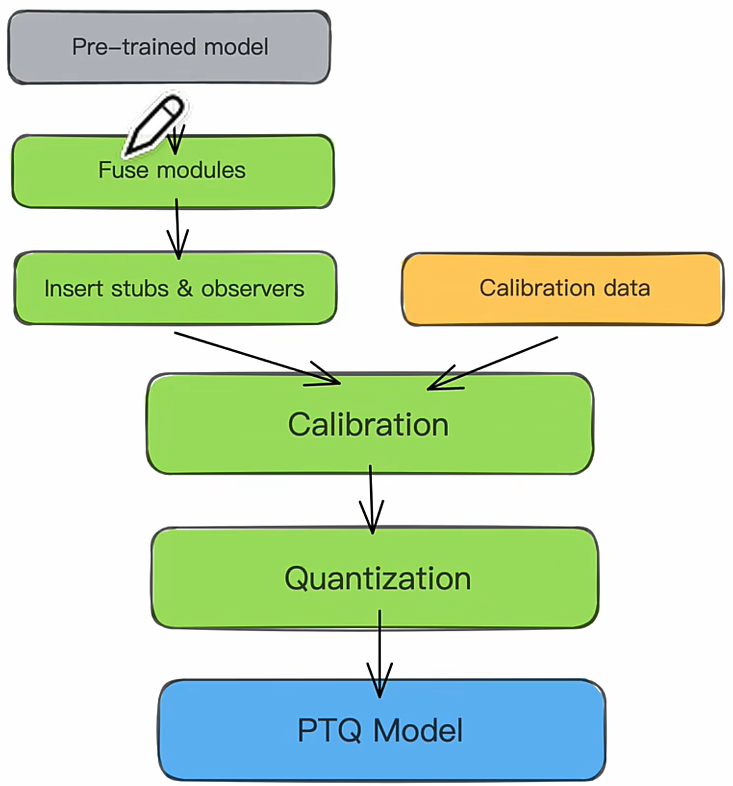
我在想我看的SVD-LLM是不是这种
KL散度校准法

流程



Deployment 端侧量化推理部署
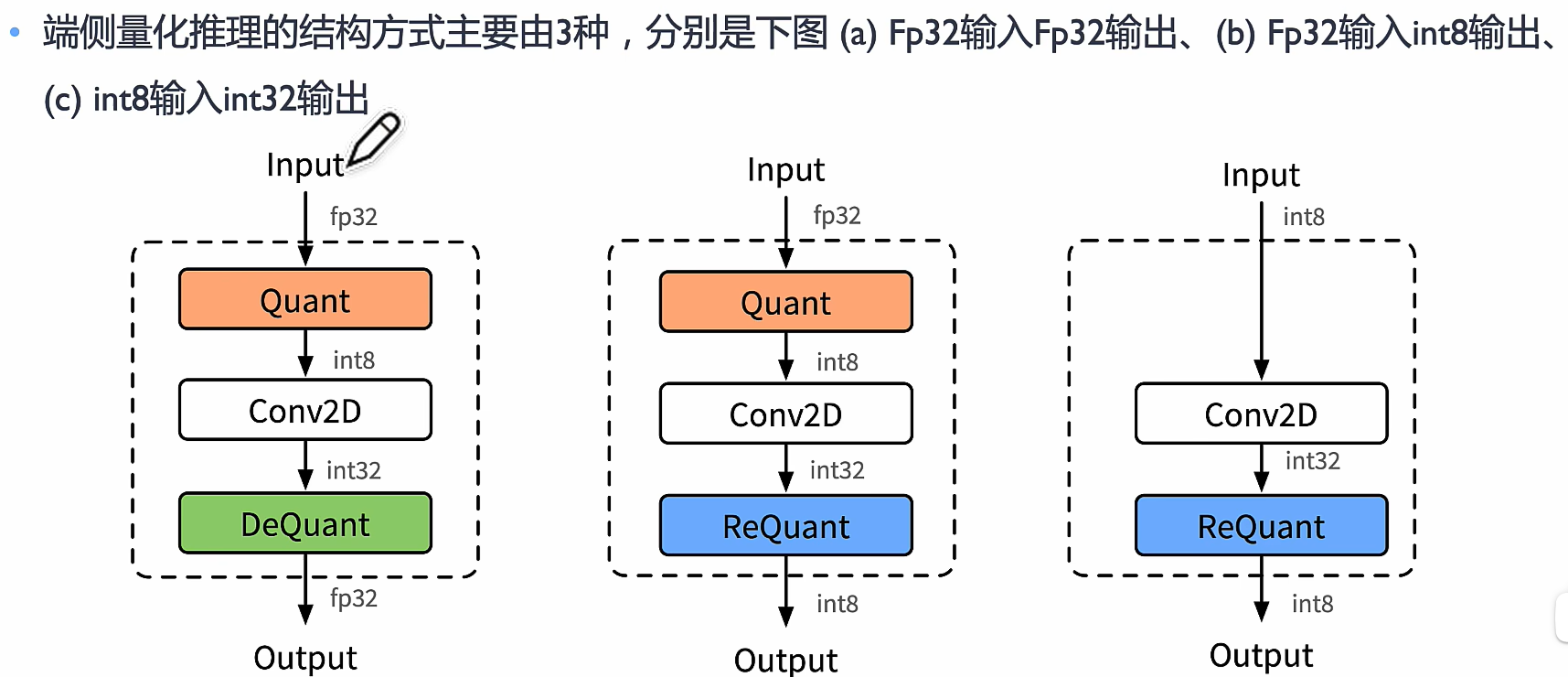
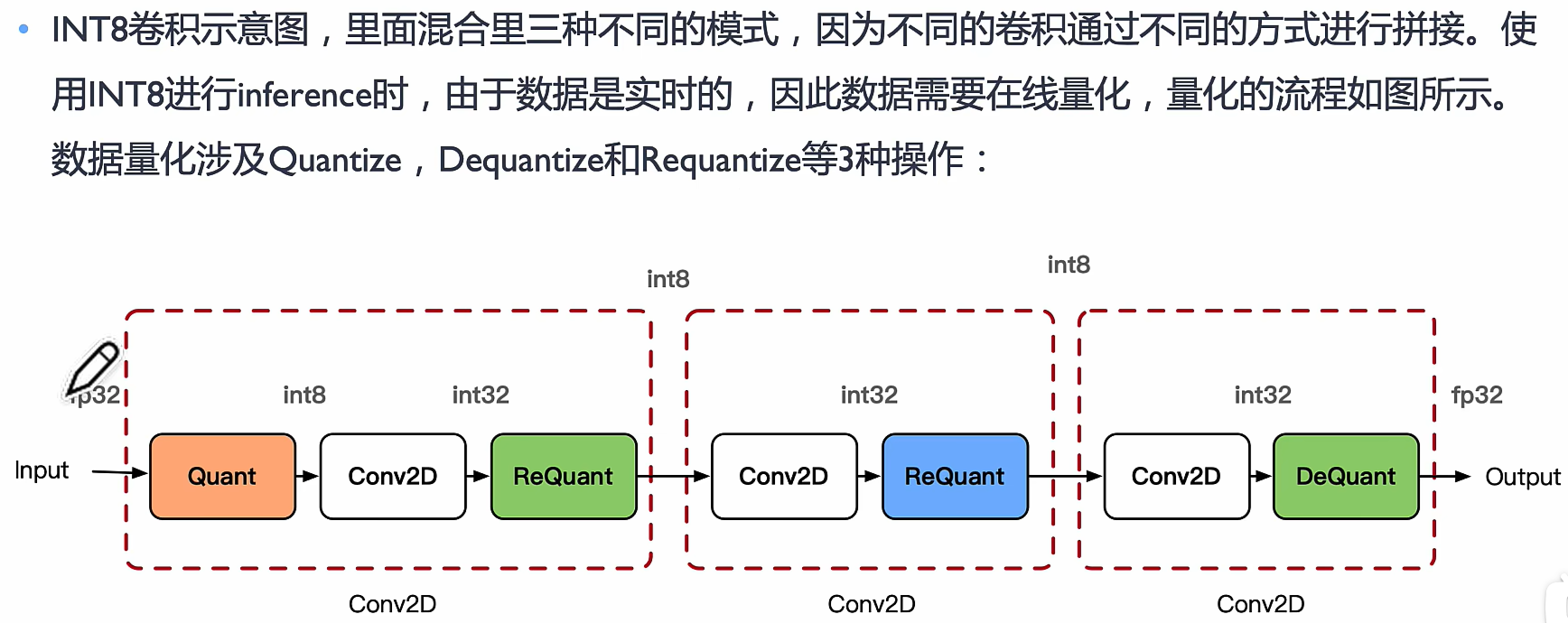
需要有量化和反量化,重量化不一定有
- 量化 → 减少数据精度,提高计算效率。
- 反量化 → 近似恢复原数据,用于推理或解码。
- 重量化 → 进一步优化量化数据以适应不同平台。
quantize 量化

Dequantize 反量化

Requantize 重量化


所以需要全图的信息
二值化网络(Binary Neural Networks, BNNs)
二值化网络是一种极端的量化方法,将神经网络的权重和激活值约束为 +1 和 -1(或 0 和 1),从而大幅减少存储和计算量。BNN 允许用位运算(如 XNOR 和 bit-count)代替浮点运算,提高计算效率,但可能导致精度下降。
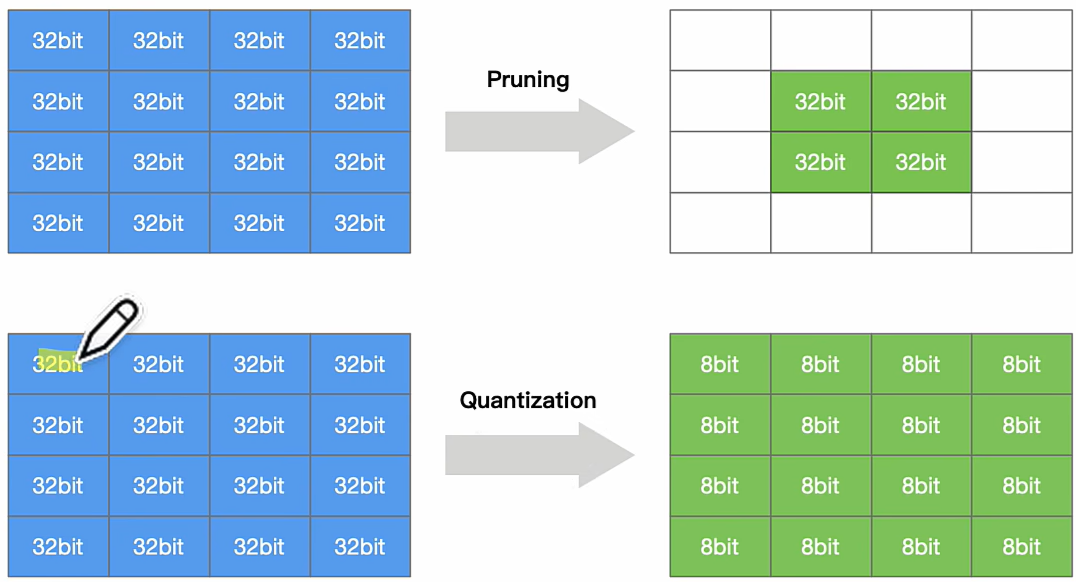
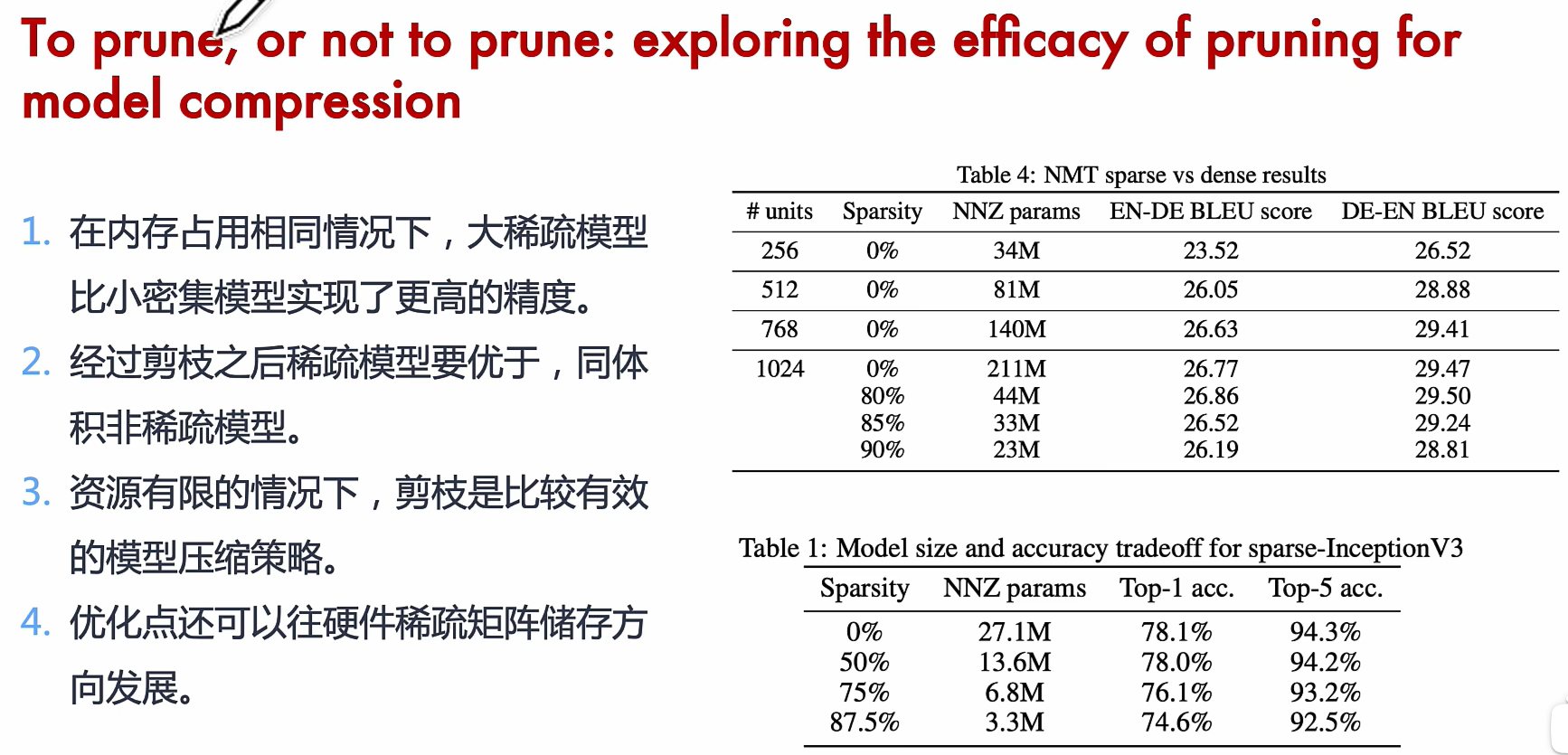
模型剪枝(Model Pruning)
模型剪枝通过去除冗余或不重要的权重、神经元或通道来减少计算量和存储需求。剪枝方法可以分为非结构化剪枝(Unstructured Pruning)(移除单个权重)和结构化剪枝(Structured Pruning)(移除整个卷积核或通道),通常结合再训练(Fine-tuning)以恢复性能。
*量化是通过减少权重表示火激活所需的比特数来压缩模型
*剪枝是研究模型权重中的冗余,并尝试删除/修剪冗余和非关键的权重
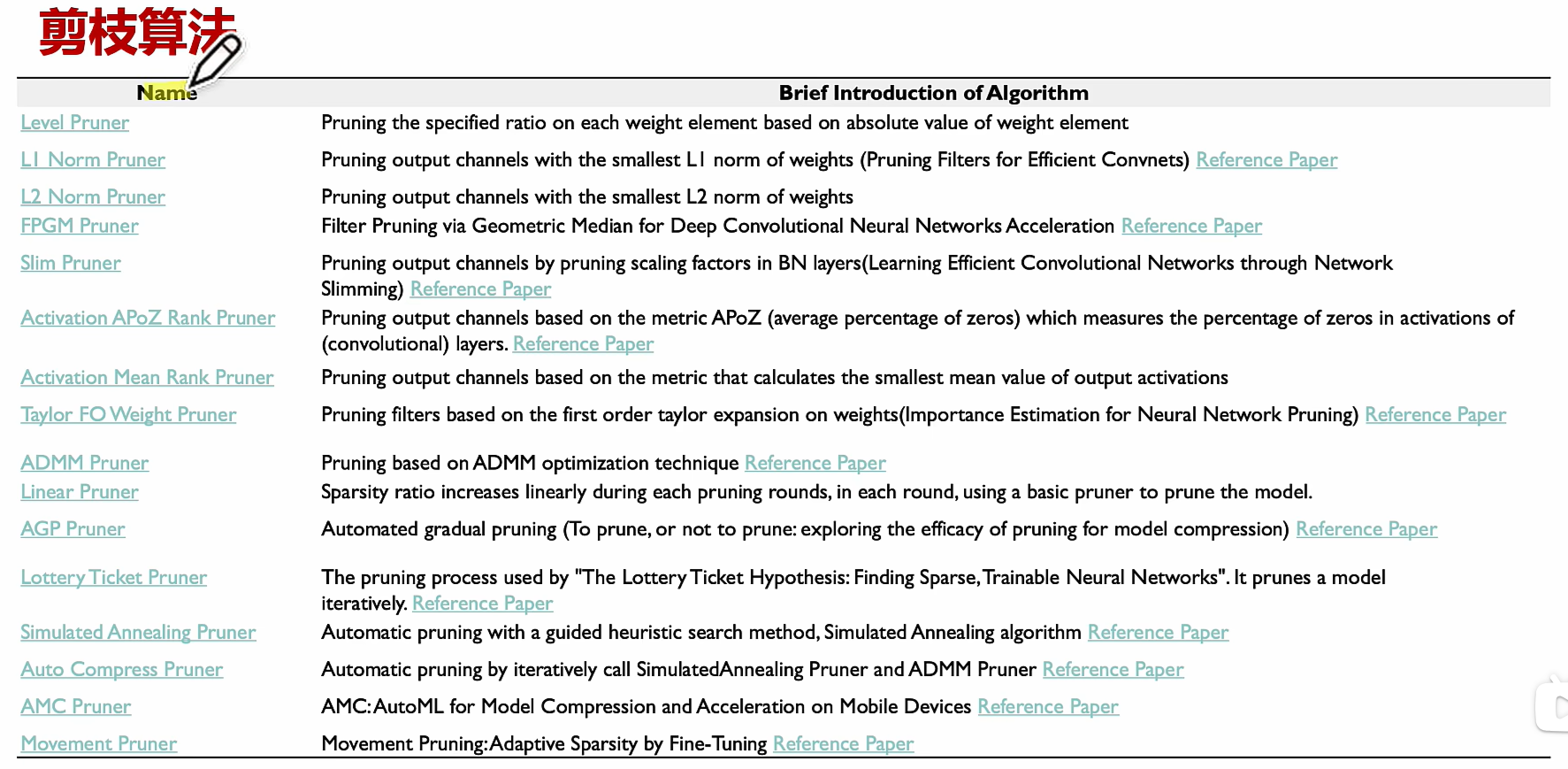
分类
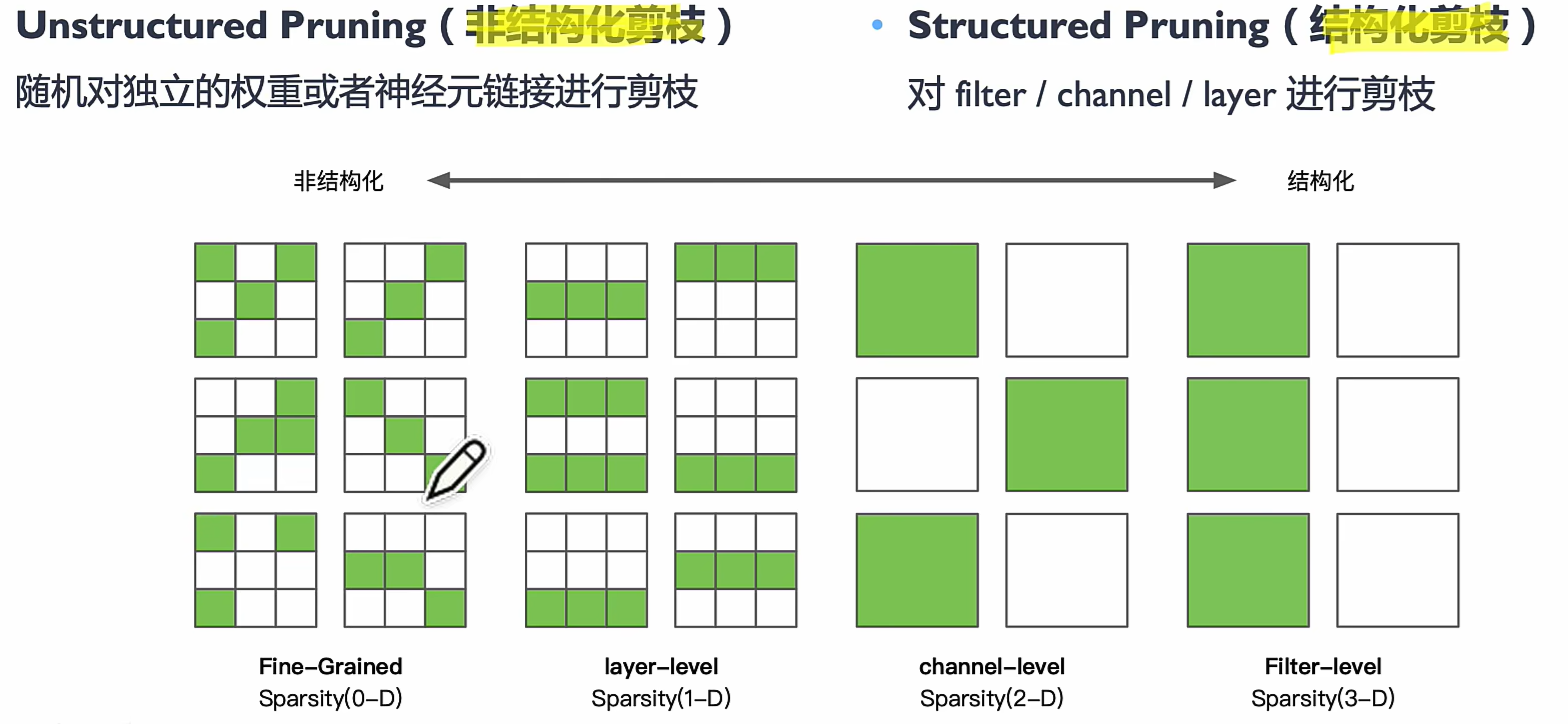
Unstructured Pruning 非结构化剪枝

structured Pruning 结构化剪枝

流 程

主要单元


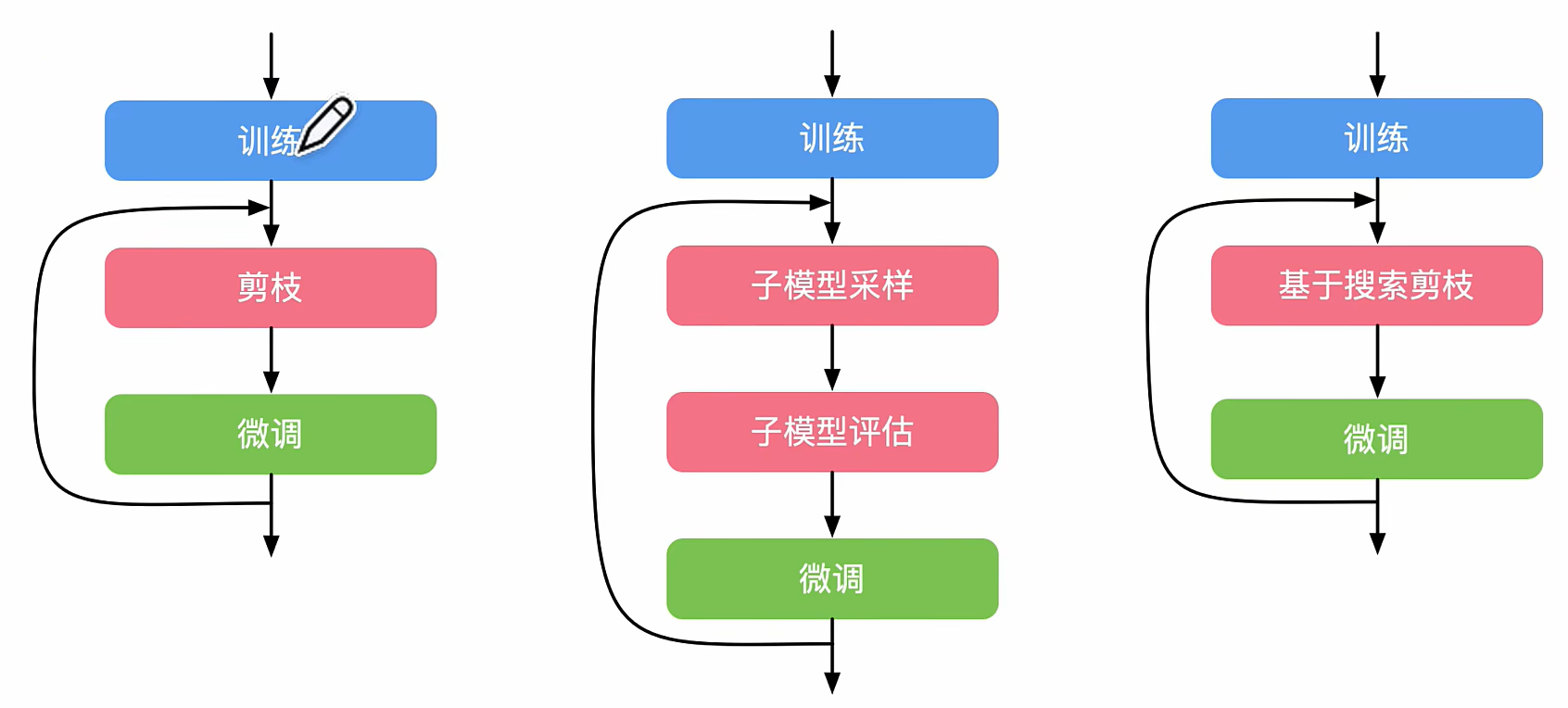
最后一种是用nas自动搜索剪枝(很耗算力
L1-norm based Channel Pruning



知识蒸馏(Knowledge Distillation, KD)
模型蒸馏是一种通过**教师-学生(Teacher-Student)**架构来压缩模型的技术。一个较大的、性能更强的教师模型(Teacher Model)用于指导较小的学生模型(Student Model),通过软标签(Soft Labels)或中间层特征传递知识,使得学生模型能在保持较高性能的情况下减少参数量。

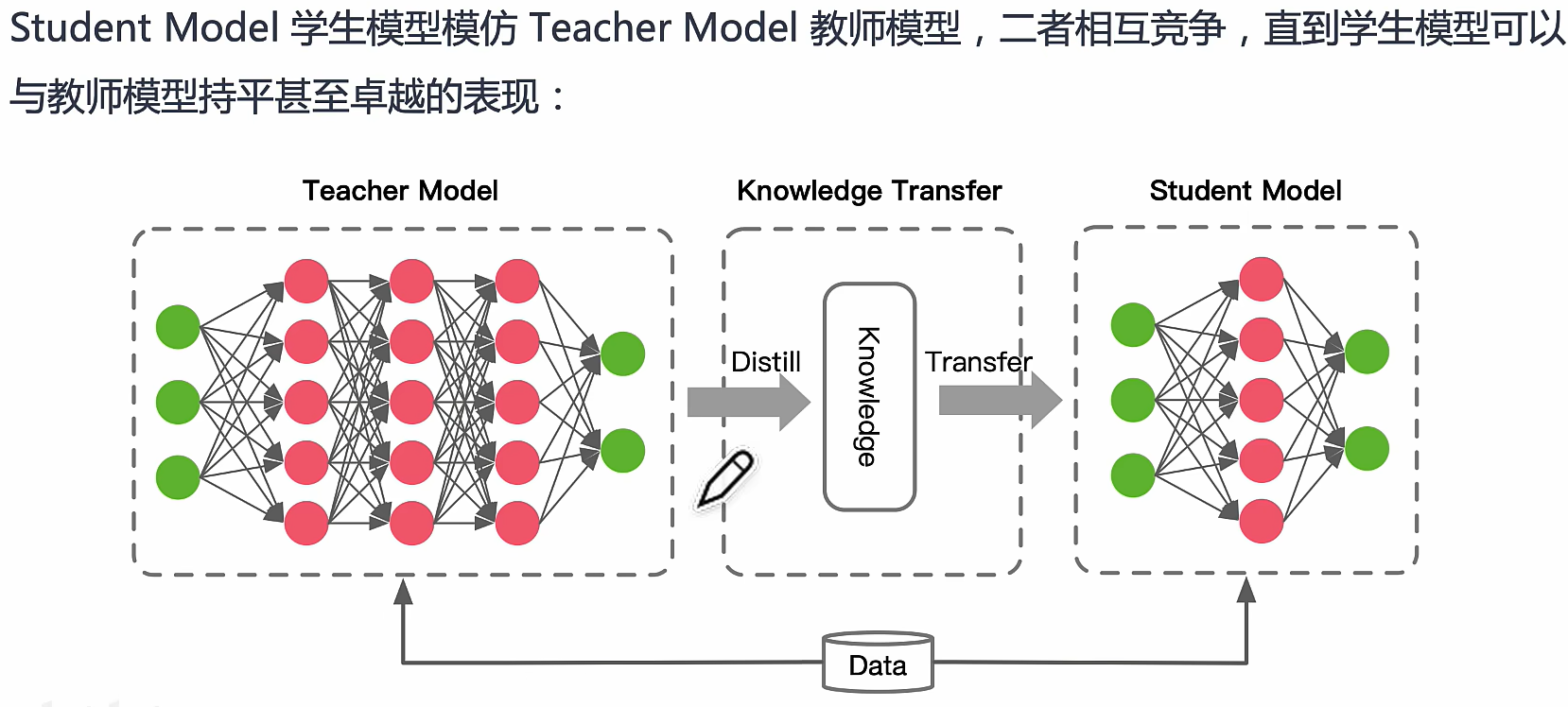 ‘组成:1)知识Knowledge 2)蒸馏算法 Distillate 3)师生架构
‘组成:1)知识Knowledge 2)蒸馏算法 Distillate 3)师生架构
参考文献:Knowledge Distillation: A Survey
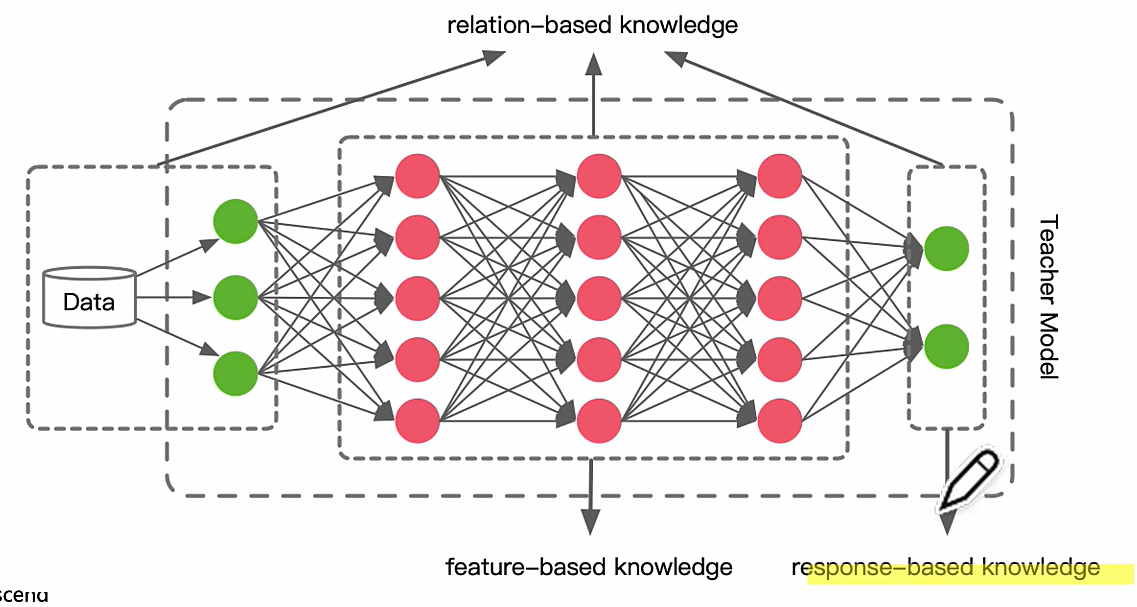
Knowledge Format 蒸馏的知识形式
response-based knowledge

类似于老师学完知识点把结论丢给学生
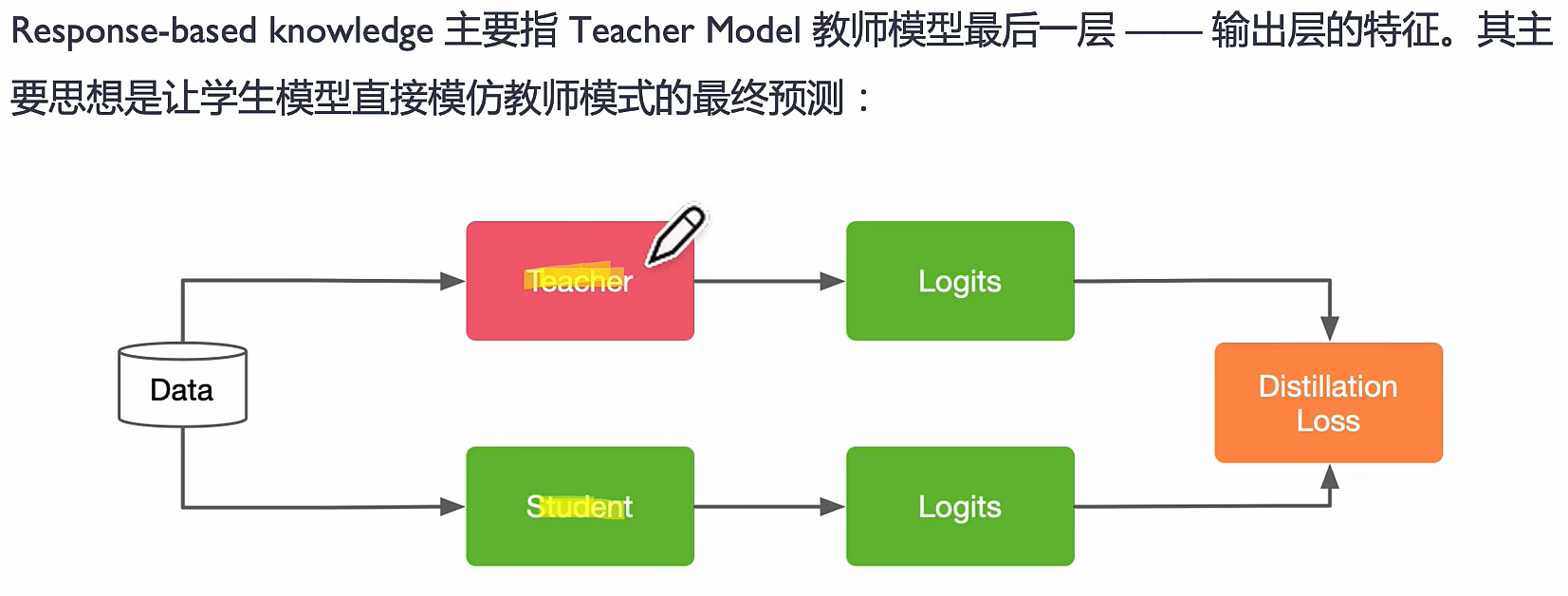
Logits 越小越好
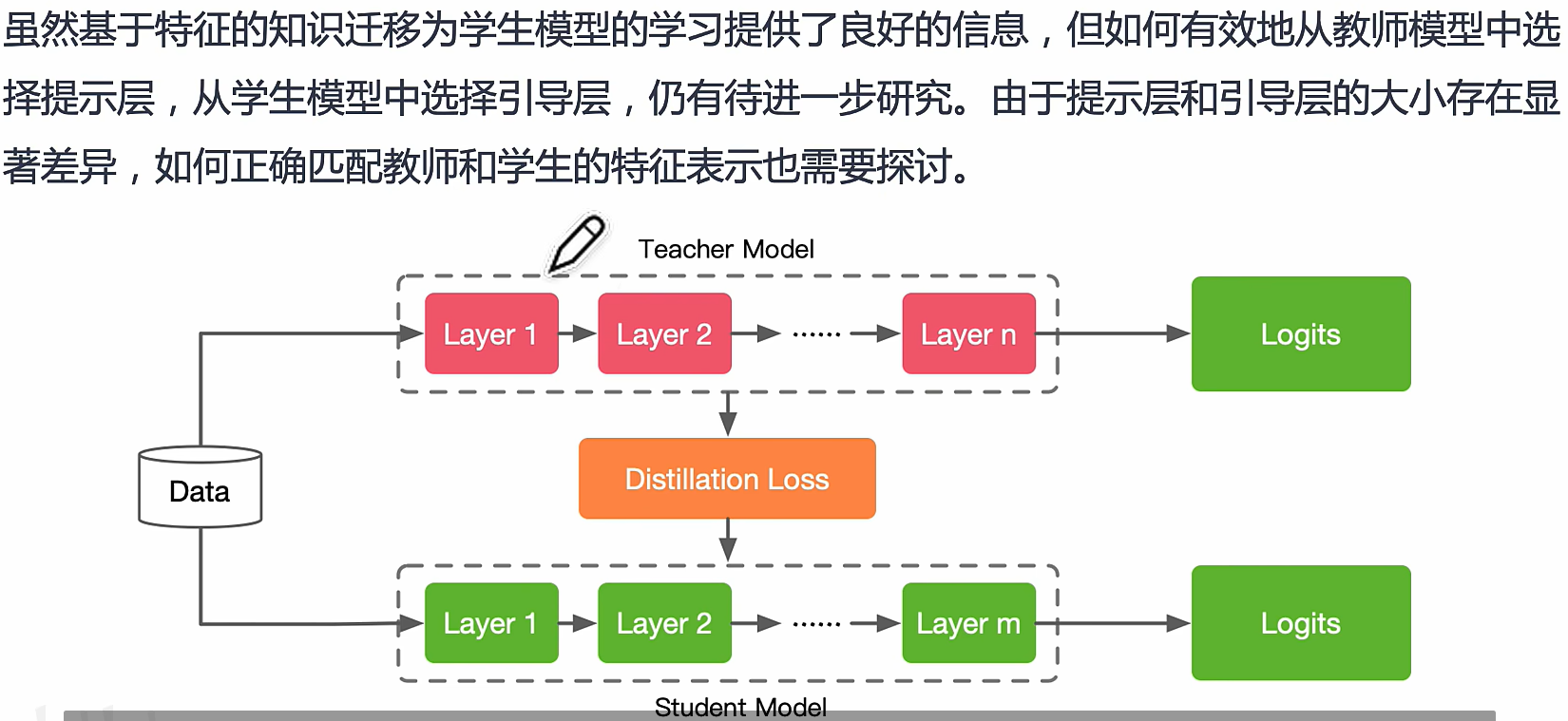
feature-based knowledge

relation-based knowledge

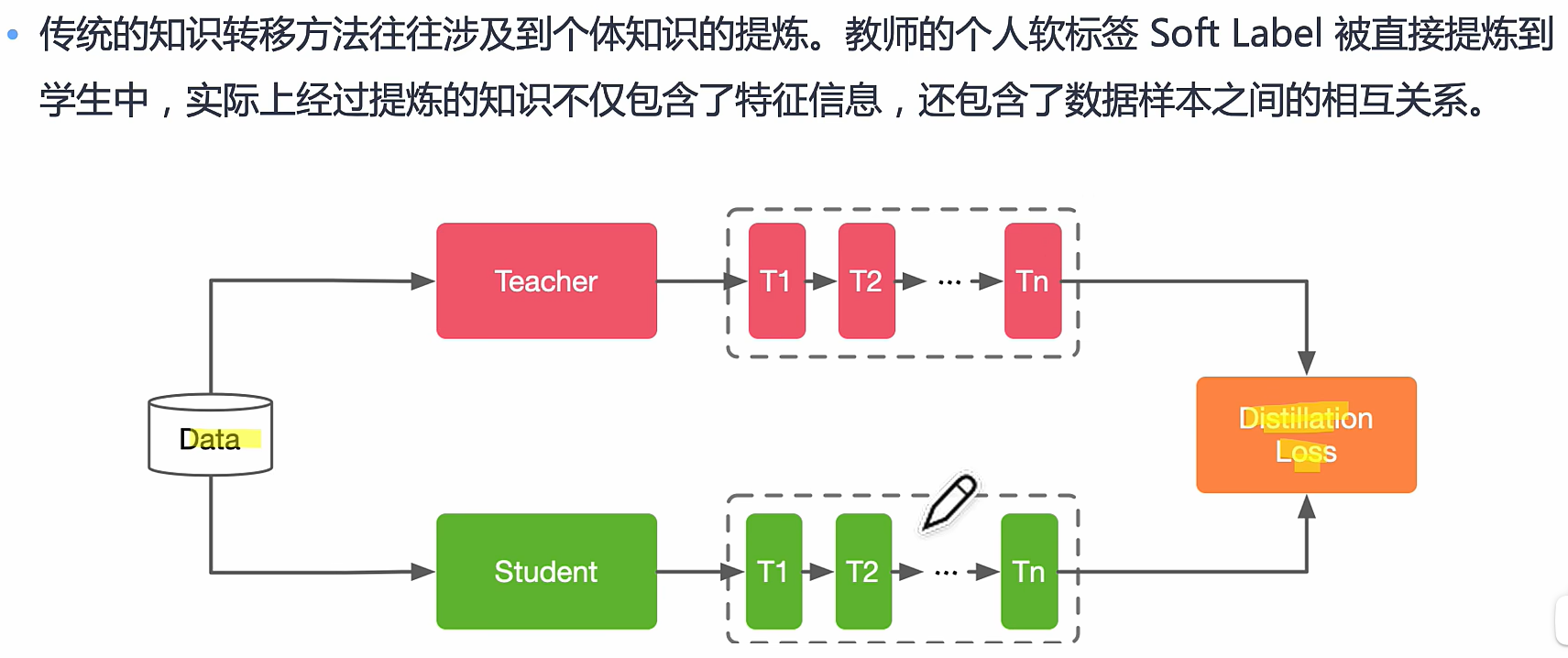
Distillation Schemes 具体方法
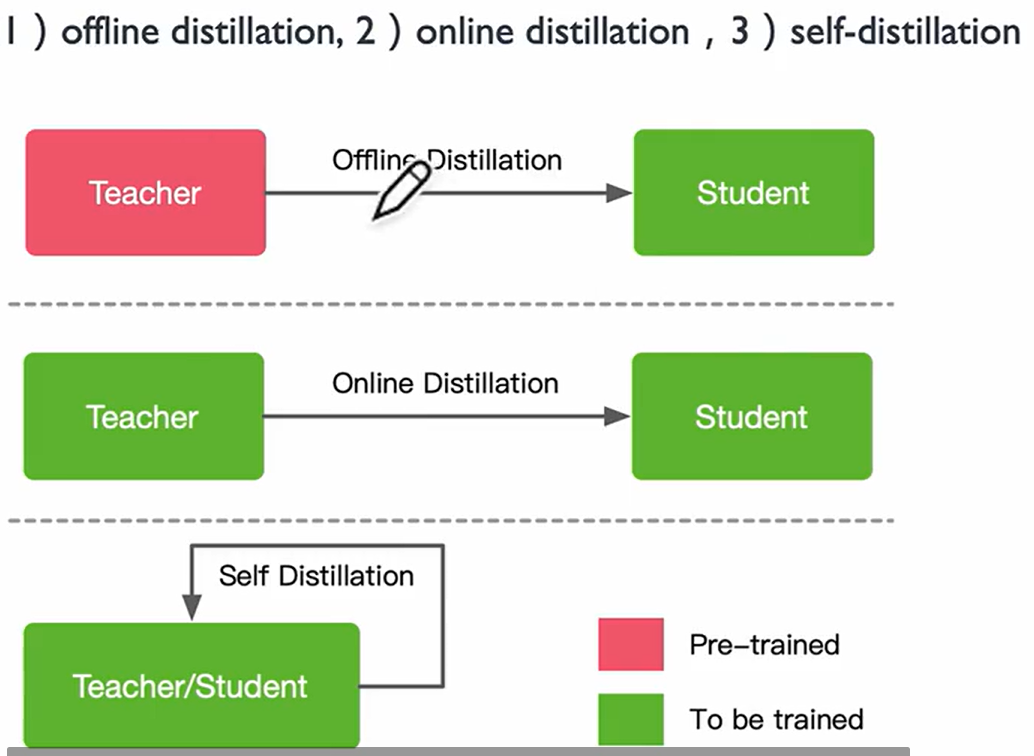
Offline Distillation

提前训练教师模型,知识渊博老师向学生传授知识
Online Distillation
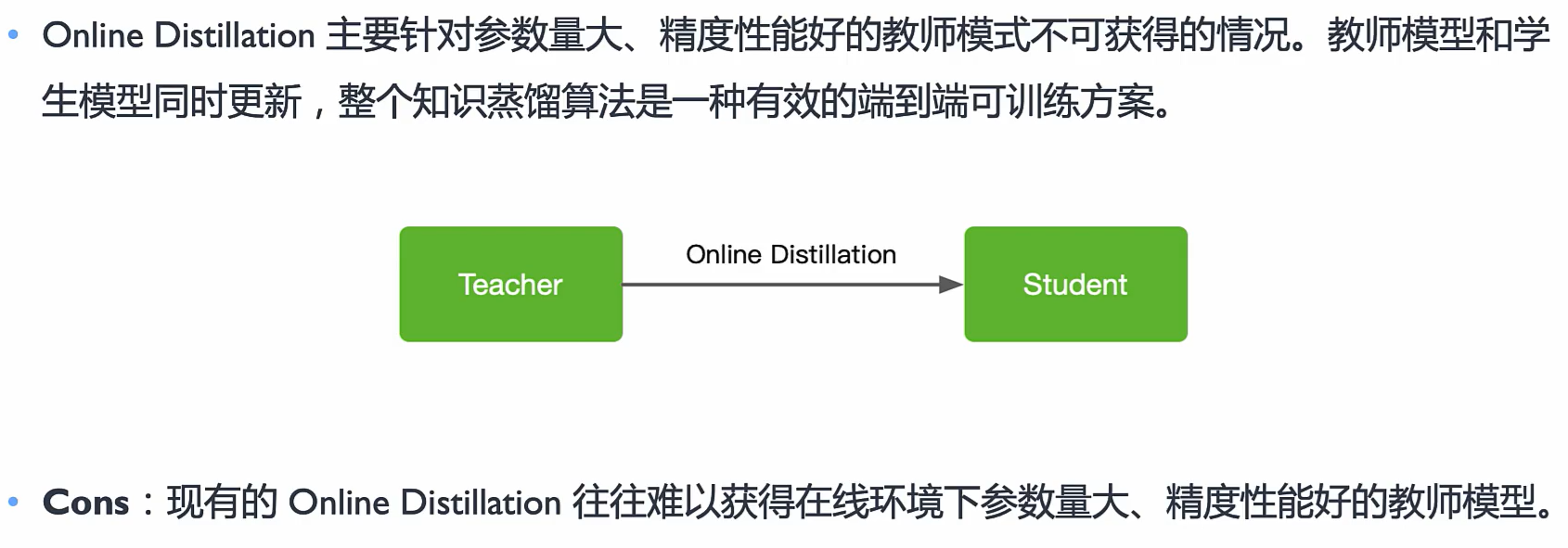
*两个模型都是在线学习的,教师和学生共同学习
Self Distillation
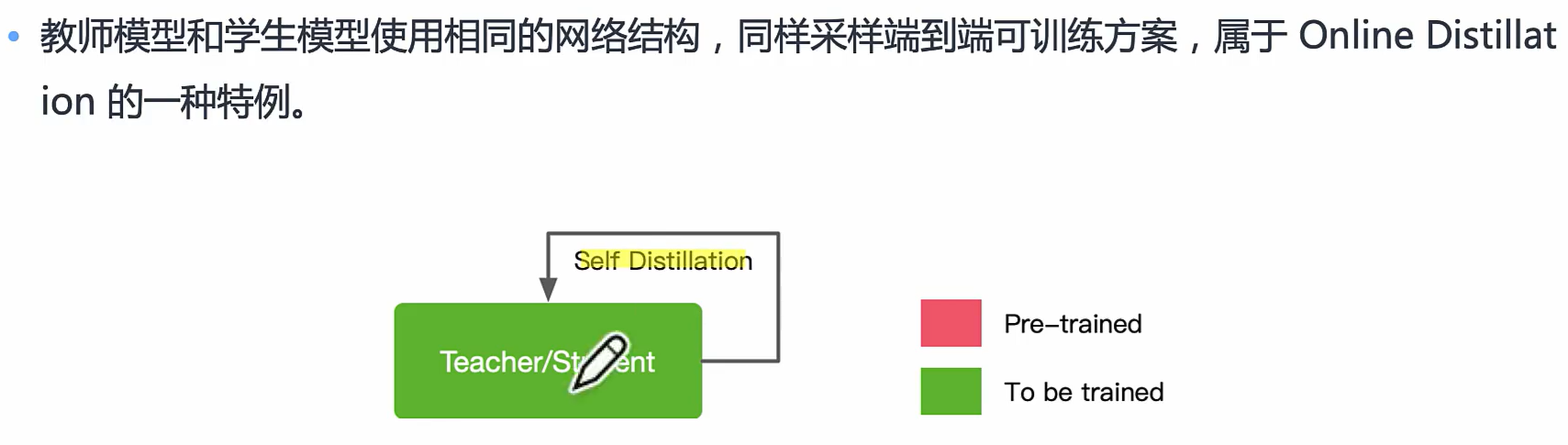
学生自己学习知识
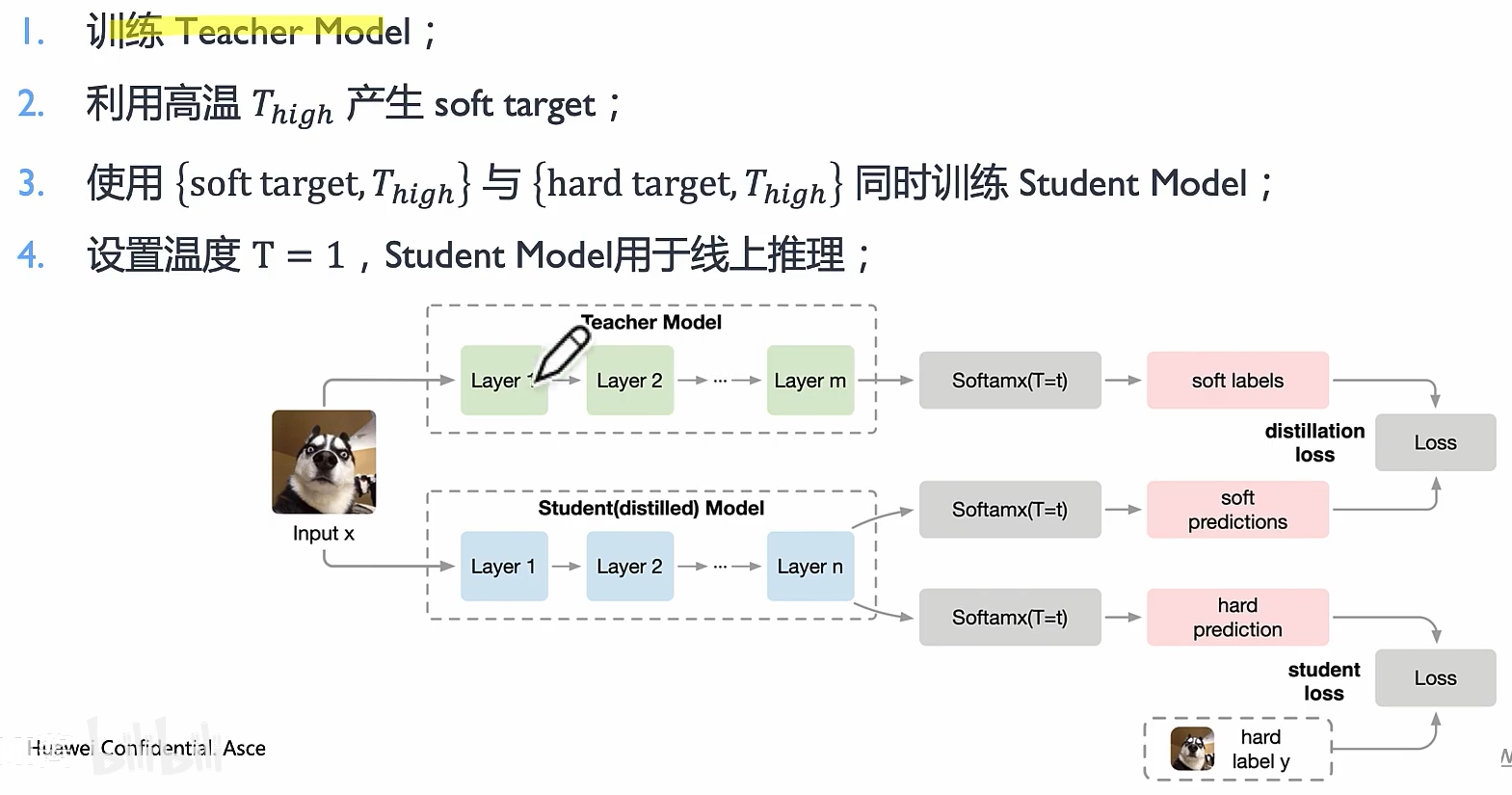
Hinton 算法
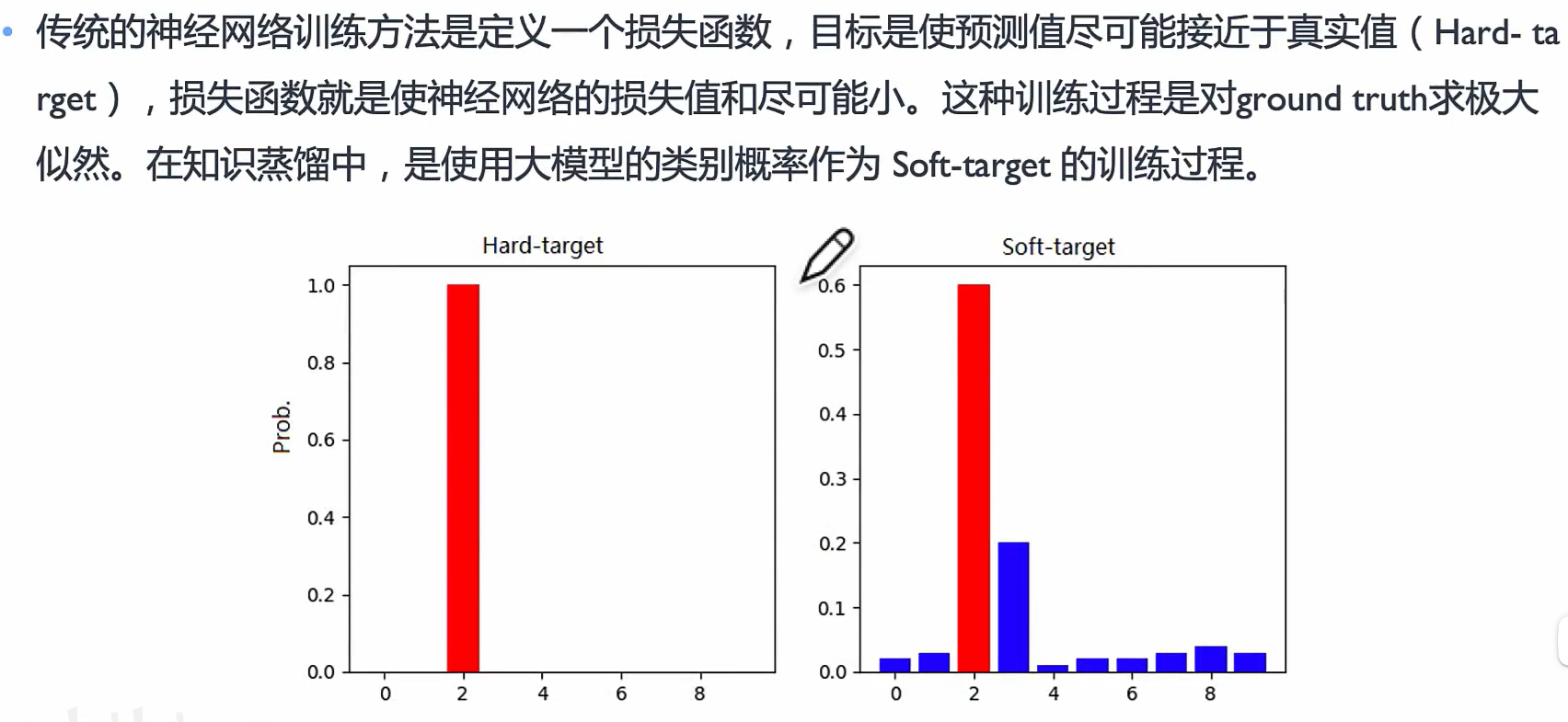
Hard-target 和 Soft-target
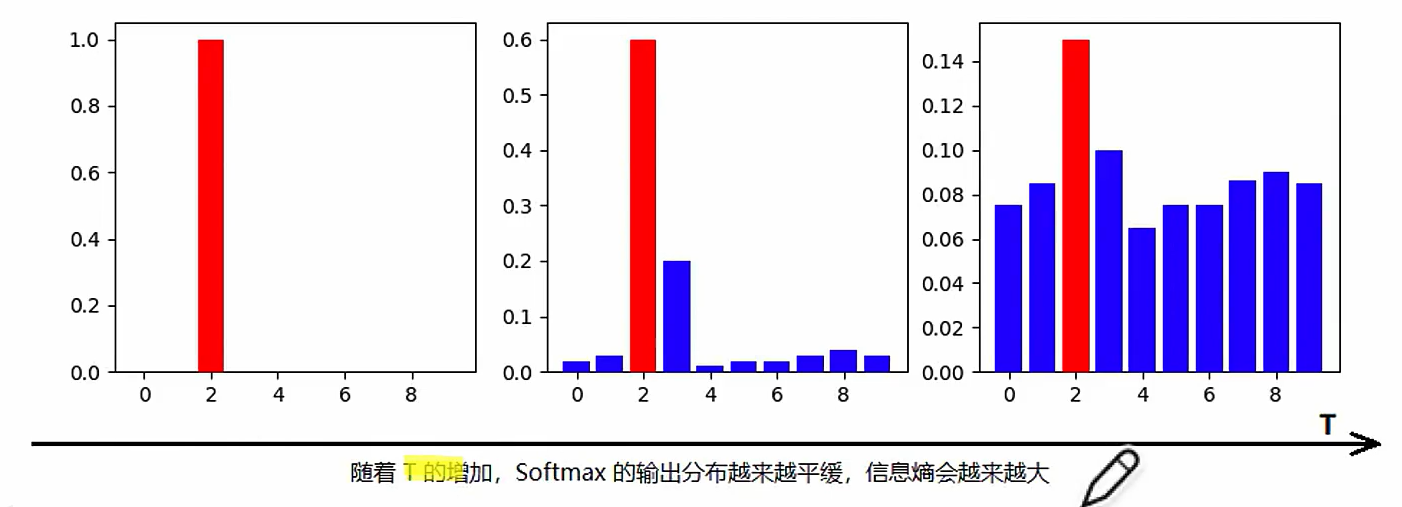
Softmax with Temperature



Distilling the knowledge in a Neural Network
开山之作!






















 46
46

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









