




- 1.基础环境的安装(默认在linux+ubuntu+anaconda)具体细节可以参考我的上一篇博客https://blog.youkuaiyun.com/Sakura_zhl/article/details/144562240,其中的不同点只有causal_conv1d和mamba_ssm两个包的版本不同。
conda create -n VMamba python==3.10.13 conda activate VMamba conda install cudatoolkit==11.8 -c nvidia pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118 conda install -c "nvidia/label/cuda-11.8.0" cuda-nvcc conda install packaging pip install mmcv==2.1.0 -f https://download.openmmlab.com/mmcv/dist/cu118/torch2.1/index.html pip install mmengine==0.10.1 pip install mmdet==3.3.0 mmsegmentation==1.2.2 mmpretrain==1.2.0 pip install causal_conv1d==1.0.0 pip install mamba_ssm==1.0.1 - 核心代码文件的创建与添加。在ultralytics/nn文件夹,建立Addmoudules文件夹,并在该文件夹下建立vmamba.py和__init__.py。打开task.py 文件,导入vmamba模块。task.py 343 行修改,1002行 添加MambaLayer,具体改动参考博客:YOLOv8改进 _ 自定义数据集训练 _ VMamba助力YOLOv8检测(附完整代码 + 修改教程 + 运行教程+个人数据标注教程+半自动标注教程+训练结果可视化教程+部署教程)_YOLO系列模型有效涨点改进-优快云专栏.html
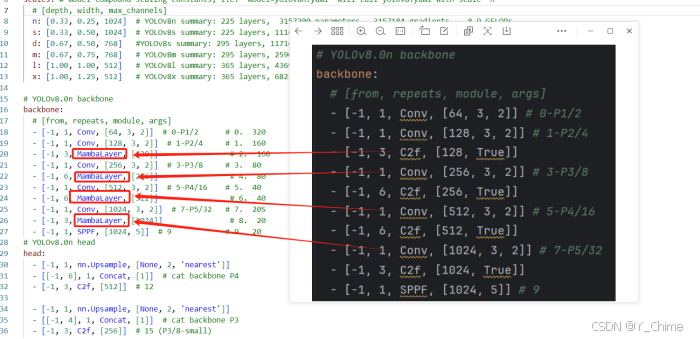
- 构建模型配置文件yolov8-vmambanet.yaml,配置网络结构,主要的变动在于backbone模块,将C2f模块换成mamba,类似于yolo10对于yolo8的改动,yolo10是将C2f替换为C2fCIB。
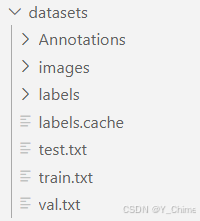
- 数据集配置,我使用的是ddsm数据集,文件结构如下,其中images存放所有的图像,annotations和labels都存放的标注文件,区别在于annotations存放的是xml格式的,labels存放的是yolo格式的,因为我们使用的是yolo模型,所以要提前将标注文件格式从xml—>yolo:
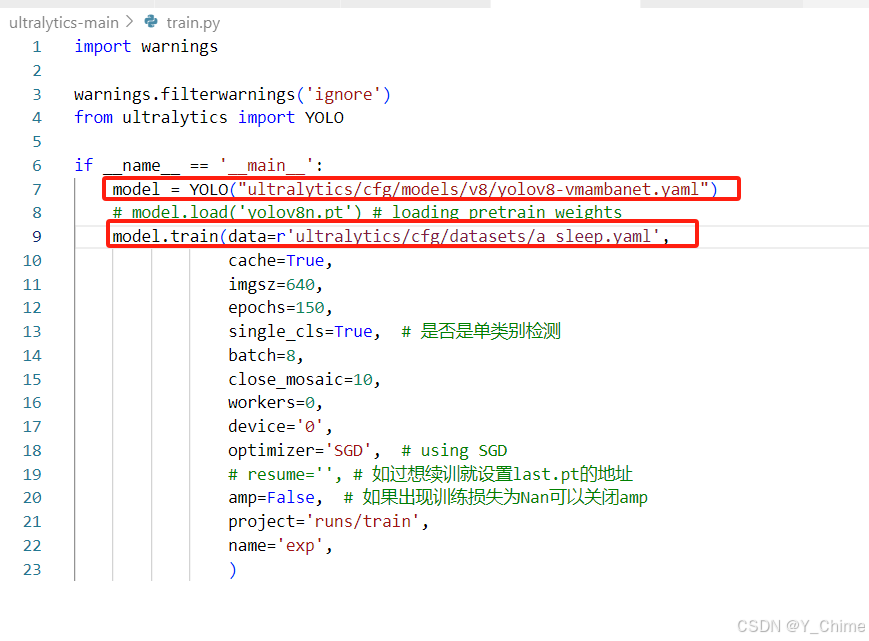
- train.py文件配置,最主要的就是两个文件的加载,其中第一个是yolo8_vmamba模型的配置文件,第二个是数据集载入的配置文件,需要根据自己的情况进行修改,其余参数的话也根据自己的需求进行修改:
- 数据集配置文件,主要就是数据集地址和目标检测类别名称。

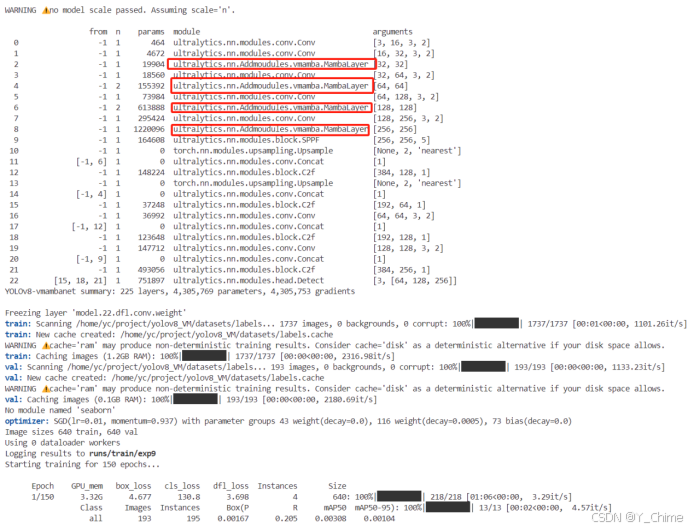
- 第一次训练,epoch = 150,yolov8n + vmamba,加载预训练模型,yolov8n,网络结构成功加载:
-
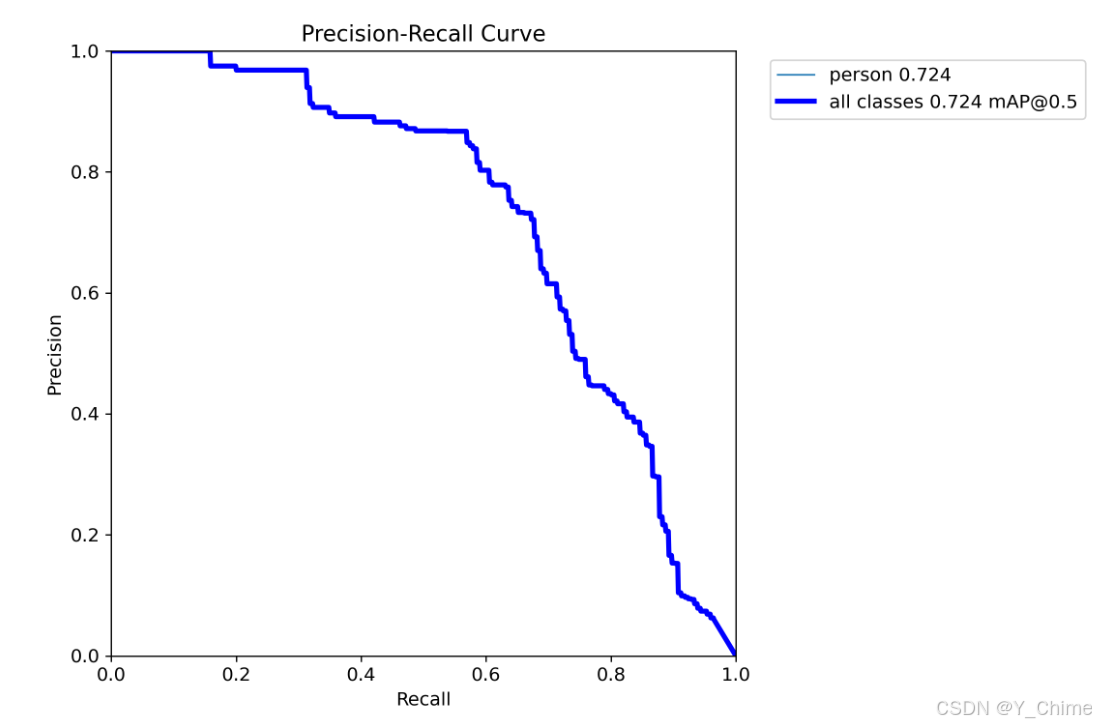
训练结果,mAP 指标达到了0.724,在没有任何调整的情况下直接跑出来这个结果,还是挺不错的:
yolov8结合vmamba,目标检测涨点起飞!
最新推荐文章于 2025-11-05 22:09:38 发布
部署运行你感兴趣的模型镜像
您可能感兴趣的与本文相关的镜像

Yolo-v5
Yolo
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon 和Ali Farhadi 开发。 YOLO 于2015 年推出,因其高速和高精度而广受欢迎

















 7236
7236




 到【灌水乐园】发言
到【灌水乐园】发言







