







 本文介绍了一种利用双向广搜算法解决字符串变换问题的方法。针对特定的字符串转换规则,在限定时间内找出从字符串A转换到B所需的最少步骤。通过双向广搜优化搜索过程,解决了状态空间过大的问题。
本文介绍了一种利用双向广搜算法解决字符串变换问题的方法。针对特定的字符串转换规则,在限定时间内找出从字符串A转换到B所需的最少步骤。通过双向广搜优化搜索过程,解决了状态空间过大的问题。
其实把csdn当成一个写日记的地方也不错啊,最近经历很少但想法很多,突然对恋爱的冲动一下子没多少了,不知道怎么开始也不知道怎么保持,找到一个情投意合的真是不容易…可以说我大学感情生活方面已经寄了呜呜,我要去二次元寻找美好了,米娜桑。
今天学习的算法是双向广搜
题目:
已知有两个字串 A, B 及一组字串变换的规则(至多 6 个规则):
A1→B1
A2→B2
…
规则的含义为:在 A 中的子串 A1 可以变换为 B1、A2 可以变换为 B2…。
例如:A=abcd B=xyz
变换规则为:
abc → xu ud → y y → yz
则此时,A 可以经过一系列的变换变为 B,其变换的过程为:
abcd → xud → xy → xyz
共进行了三次变换,使得 A 变换为 B。
输入格式
输入格式如下:
A B
A1 B1
A2 B2
… …
第一行是两个给定的字符串 A 和 B。
接下来若干行,每行描述一组字串变换的规则。
所有字符串长度的上限为 20。
输出格式
若在 10 步(包含 10 步)以内能将 A 变换为 B ,则输出最少的变换步数;否则输出 NO ANSWER!。
输入样例:
abcd xyz
abc xu
ud y
y yz
输出样例:
3
如果说用单项广搜的话,状态数会有至少6^10=60 466 176这么多状态
题目限制在1s,所以肯定会tle
双向广搜可以优化最高到4000倍!
原因如下
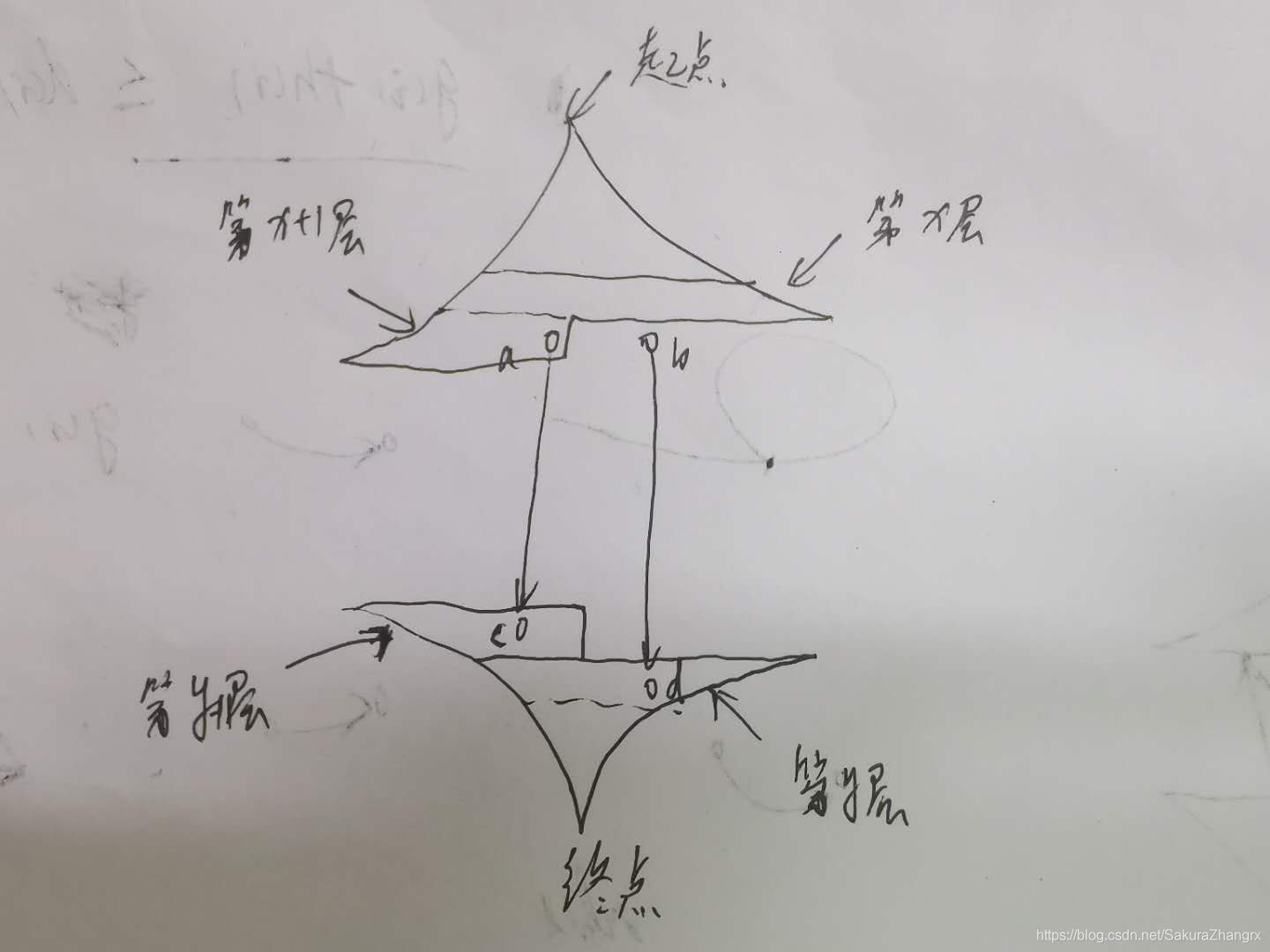
用到我们的双向广搜从重点开始和从起点开始,每次搜索状态数小的一边,这样效率更高!
双向广搜用于最小步长问题
代码:
#include<iostream>
#include<unordered_map>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std;
const int N = 6;
int n = 0;
string a[N], b[N];
int extend(queue<string> &q, unordered_map<string, int> &da, unordered_map<string, int>&db, string a[], string b[])
{
string t;
t = q.front();
q.pop();
for (int i = 0; i < t.size(); i++)
{
for (int j = 0; j < n; j++)
{
if (t.substr(i, a[j].size()) == a[j])
{
string state = t.substr(0, i) + b[j] + t.substr(i + a[j].size());
if (db.count(state))
return da[t] + 1 + db[state];
if (da.count(state))
continue;
q.push(state);
da[state] = da[t] + 1;
}
}
}
return 11;
}
int bfs(string A, string B)
{
queue<string> qa, qb;
unordered_map<string, int> da, db;
qa.push(A); da[A] = 0;
qb.push(B); db[B] = 0;
int t = 0;
while (qa.size() && qb.size())
{
if (qa.size() <= qb.size())
{
t = extend(qa, da, db, a, b);
}
else
t = extend(qb, db, da, b, a);
if(t<10)
return t;
}
return 11;
}
int main(int argc, char const* argv[])
{
string A, B;
cin >> A >> B;
while (cin >> a[n] >> b[n])
{
n++;
}
int step = bfs(A, B);
if (step > 10)
cout << "NO ANSWER!" << endl;
else
{
cout << step << endl;
}
return 0;
}
结束

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









