




目录
一、select from
这个是SQL中基础的查询语句
如一个表中有这些数据 表名是 world
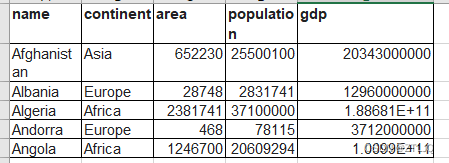
然后我们想查询 name 和 area 语法就是这样写的
select name,area from world查询的结果是这样的
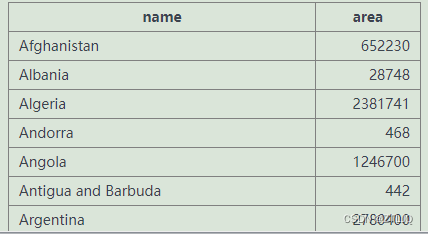
除此之外 这个查询语句是可以使用别名的 也就是as
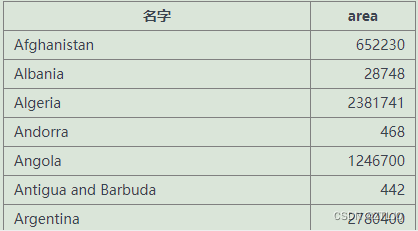
写的方法如下
select name as 名字,area from world结果如下
当然 也可以不使用as 之间空格 然后也默认算是别名的意思
select name 名字,area from world
这里需要记住一个知识点就是 distinct 是用来去重复的 比如一列数据 多个重复值 用distinct 就可以进行去重操作
语法使用如下
select distinct (你要去重的列) from world
二、where
where子句是写在from之后的,where主要是用来筛选数据的。
在使用时格式如下
select 字段名称
from 表
where 字段名称 运算符 值
运算符重点说明一下
大于小于号我就省略不讲
between and 是指在两个值之间
in 可以理解为在什么范围内
not in 就是不在什么范围内
is null 就是空值
is not null 不为空值
and 与
or 或
not 非
and 和 or 可以把两个或多个条件结合起来。若and连接的两个条件对于该数据都成立,就显示该数据,若or连接的两个条件对于该数据只要有一个成立,就显示该数据,否则就筛除该数据。
在此还需要讲一下 like 模糊查询
select 字段名称
from 表
where 字段名称 like '通配符+字符'
这里的通配符共有这些,%用来匹配多个字符可以是零个、一个也可以是多个字符,_仅能用来匹配单个字符
比如匹配以C开头的字符 然后以b结尾的筛选条件就是这样写语法
因为%可以匹配多个字符 条件只是说以C开头所以中间的无所谓是什么 最后结尾是b就可以了
where name like 'C%b'
三、聚合函数
1、聚合函数
首先列举一些常用的聚合函数
| 常用函数 | 作用 |
| SUM() | 是用来返回某列的和 |
| MIN() | 是用来返回某列的最小值 |
| MAX() | 是用来返回某列的最大值 |
| AVG() | 是用来返回某列的均值 |
| COUNT() | 是用来返回某列的行数 |
那么这个聚合函数该怎么使用呢?
比如 要从allworld表中 找到 有多少国家的面积大于50万
就可以这样写
select count(name)
from allworld
where area > 500000
2、group by
首先 group by 是一个分组函数的意思,使用这个会将你选择的列自动进行去重处理,会将重复的值去除。
那么这个是怎么使用的呢?
假如按上面聚合函数的题目基础上 不求面积 求的是 每个大洲 中 国家的数量
就可以这样写
select continent,count(name)
from allworld
group by continent其实可以这样理解
大洲是一个大的圈 在这个大的圈中有很多国家 所以我们是肯定要对大洲进行分组,因为要进行去重处理,否则看起来就非常乱。
其次group by 还需要注意一点,当你的group by 使用了以后 select查询的 就不能查询 group by中没出现过的字段和聚合函数,否则是会报错的。
相当于是 你已经对大洲进行分组了 然后你 多写一个其他的字段,就没法显示,因为另外一个字段并没有分组 就算分组了也许和大洲不一样,这样就会报错。
3、having
这个相当于是对聚合的运算进行筛选,什么意思呢? 其实就是 当你进行分组了以后,可以使用having对组内的数据再进行一次筛选。
比如
查找 人口数至少是5千万的大洲
select continent
from allworld
group by continent
having sum(population) > 50000000
四、order by
首先order by 子句是用来排序的,对最后查询出的结果集进行排序。
asc指定该字段升序排序,desc为降序排序,不写则默认为升序排序。
order by 可以对多个字段按照主字段和次字段排序。
接下来因为上面讲了很多的子句 那么我们讲一下写的顺序是什么样的
select 字段名
from 表格名
where 条件代码
group by 字段名
having 条件
order by 字段名
写下来的顺序是按照上面的这个顺序
那么具体的使用方法是什么样的呢?
查询成绩表格中 学生的姓名 和 学生的成绩 并且按照成绩从高到底排序
select name,score
from grade
order by score desc
五、limit
首先limit可以直接看单词就明白这个是限制用的,意思差不多,比如查询第6行到第10行就会用到limit
这个顺序就是写在order by后面
select 字段名
from 表格名
where 条件代码
group by 字段名
having 条件
order by 字段名
limit 限制值
具体使用方法 举例
查询成绩表中 第3行到第8行的数据
select *
from grade
limit 2,6
limit的公式可以这样记忆
limit x,y
返回x+1行数据 到 x+y行
六、子查询
首先子查询是属于是 SQL中进阶的语法,子查询的魅力就在于可以使SQL语句千变万化。子查询是使用括号()包裹嵌套在主查询语句中。
子查询的执行优先于主查询执行,因为主查询的条件用到了子查询的结果,子查询可以在select,from,where,having子句中使用。
子查询可以分成4类
标量子查询:结果只有一行一列
行子查询:查询结果只有一行
列子查询:结果只有一列
表子查询:结果有多行多列
举例
查询国家的名称,并且这些国家的gdp大于欧洲国家中最大的gdp,其中国家的gdp不为空值
select name
from world
where gdp>(
select max(gdp)
from world
where continent='europe' and gdp is not null
)
这种一般怎么进行分析呢? 首先我们要知道 子查询的优先级是大于主查询语句的,所以我们需要先看子查询。
首先我们分析题目 先写出查询国家的名称
select name
from world
然后我们看 主要是查询的gdp 所以 where gdp
然后看 子查询怎么写
可以看到 需要先找到欧洲国家最大的gdp 所以 可以直接写出聚合函数 max(gdp)
然后看条件 是欧洲国家 所以 continent=europe 然后 gdp不能为空
最后看 主查询的条件是 gdp大于 所以 写上gdp>
这样一道题就被我们分解了


















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











