




 本教程介绍了Python的基础知识,包括数据类型(整型、浮点型、字符串、布尔型)、字符串操作、控制流(比较操作符、if语句、while语句、for循环、break和continue语句)、函数定义与调用、变量作用域以及列表、元组和字典等数据结构的使用。此外,还讲解了如何导入模块、函数返回值、列表的增删改查操作以及字符串的切片、下标和方法。通过这些基础知识,读者将能更好地理解和运用Python编程。
本教程介绍了Python的基础知识,包括数据类型(整型、浮点型、字符串、布尔型)、字符串操作、控制流(比较操作符、if语句、while语句、for循环、break和continue语句)、函数定义与调用、变量作用域以及列表、元组和字典等数据结构的使用。此外,还讲解了如何导入模块、函数返回值、列表的增删改查操作以及字符串的切片、下标和方法。通过这些基础知识,读者将能更好地理解和运用Python编程。
第二章 Python入门基础
整型、浮点型和字符串数据类型
| 数据类型 | 例子 |
|---|---|
| 整型(int) | -2,-1,0,1,2 |
| 浮点型(float) | -1.25,-1.0,0.0,1.0 |
| 字符串(atirs) | ‘a’,‘aa’,‘hello’ |
| 布尔型(bool) | True 和 False |
str='123456789'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第五个的字符
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔一个的字符(步长为2)
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
改变类型
将数据从一种类型转成另一种类型
float() #从一个字符串或者证书创建一个新的浮点数(小数)
int() #从一个字符串或浮点数创建一个新的整数
str() #从一个数(可以是任何类型)创建一个新的字符串
type() #确定一个变量的类型
第三章 控制流
比较操作符
| 操作符 | 含义 |
|---|---|
| == | 等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
此外还有布尔操作符(and、or、not)用于比较布尔值。
两种操作符也可以混合使用:
>>>(4<5)and(5<6) #先求值左边表达式再求值右边最后求布尔值
True
控制流语句
if语句
if condition_1: #如果 "condition_1" 为 True 将执行 "statement_block_1" 块语句
statement_block_1 #如果 "condition_1" 为False,将判断 "condition_2"
elif condition_2: #如果"condition_2" 为 True 将执行 "statement_block_2" 块语句
statement_block_2
elif condition_3: #如果 "condition_2" 为False,将执行"statement_block_3"块语句
statement_block_3
else:
statement_block_4
if嵌套
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
while语句
Temp = 0 #利用while语句可以让代码块重复执行
while Temp < 3:
if Temp == 0:
print('A')
elif Temp == 1:
print('B')
else :
print('C')
Temp = Temp + 1
print('Thank you!')
break语句
Temp = 0
while True:
if Temp == 0:
print('A')
elif Temp == 1:
print('B')
else :
print('C')
Temp = Temp + 1
if Temp == 3:
break #在执行中遇到break语句,就会马上退出while循环子句
print('Thank you!')
continue语句
Temp = 0
while True:
if Temp != 3:
print('Please type your name')
Temp = Temp + 1
continue #continue语句用于循环内部。如果程序执行遇到continue语句,就会马上跳回循环开始处,重新对循环条件求值
else:
print('Jack')
break
print('Thank you!')
for循环和range()函数
如果想让一个代码块执行固定次数。可以通过for循环语句和rang()函数来实现。
for 变量名 in range(最多三个参数):
缩进的代码块
total = 0 #求0到100的和
for num in range(101): #for循环执行100次
total = total + num
print(total)
>>>for i in range(12,15): #多参数调用,第二个参数是上限,但不包含它
print(i)
>12
>13
>14
>>>for i in range(0,6,2): #多参数调用,步长为2(负数也可以作为步长)
print(i)
>0
>2
>4
导入模块
在 python 用import或者 from…import 来导入相应的模块。
将整个模块(somemodule)导入,格式为: import somemodule
从某个模块中导入某个函数,格式为: from somemodule import somefunction
从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
将某个模块中的全部函数导入,格式为: from somemodule import
第四章 函数
def语句和参数
创建或定义函数要使用python的def关键字,然后可以和函数名来使用或调用这个函数。
而参数则能够向函数传递信息,def语句为:def 关键字(参数1,参数2,...):
1.def printMyAddress(myname):
2. print("myname")
3. print("Welcome road")
4. print("Wanfu community")
5. print("Building")
6.printMyAddress("xiaopeng")
代码块的执行顺序为:612345,此时的打印结果为:
xiaopeng
Welcome road
Wanfu community
Building
返回值和return语句
我们可以向函数发送信息(参数),函数也可以向调用者发回信息。从函数返回的值称为结果(result)或返回值(return value)
用defi语句创建函数时,可以用return语句指定应该返回什么值,return语句为:return '函数应该返回的值或表达式'
import random
def getAnswer(answerNumber):
if answerNumber == 1:
return 'it is certain'
if answerNumber == 2:
return 'it is decidedly so'
if answerNumber == 3:
return 'yes'
if answerNumber == 4:
return 'reply hazy try again'
if answerNumber == 5:
return 'ask again later'
if answerNumber == 6:
return 'concentrate and ask again'
if answerNumber == 7:
return 'my reply is no'
if answerNumber == 8:
return 'outlook not so good'
if answerNumber == 9:
return 'vert doubtful'
r = random.randint(1,9)
fortune = getAnswer(r)
print(fortune) #最后三张可以缩成等价的一行代码:print(getAnswer(randon.randint(1,9)))
在这个程序开始时,Python首先导入random模块。然后getAnswer()函数被定义,因为函数是被定义(而不是被调用),所以执行会跳过其中的代码。接下来,random.randint()函数被调用,带两个参数1和9。它求值为1~9之间的一个随机证书(包括1和9),这个值被存在一个名为r的变量中。
getAnswer()函数被调用,以r作为参数。程序执行转移到getAnswer()函数的顶部,r的值被保存到名为answerNumber的变元中。然后,根据answerNumber中的值,函数返回许多可能字符串中的一个。程序执行返回到程序底部的代码行,即原来调用getAnswer()的地方。返回的字符串被赋给一个名为fortune变量,然后它又被传递给print()调用,并被打印在屏幕上。
局部和全局域
变量起作用的范围称为变量的作用域,不同作用域内同名变量之间相互不影响。
在被调用函数内赋值的变元和变量,处于该函数的“局部作用据”,被称为“局部变量”;在所有函数之外赋值的变量,属于“全局作用域”,被称为“全局变量”。
作用域:
全局作用域中的代码不能使用任何局部变量;
局部作用域可以访问全局变量;
一个函数的局部作用域中的代码,不能使用其他局部作用域中的变量;
在不同的作用域中,可以用相同的名字命名不同的变量。
全局变量:
函数内要改变全局变量的值,使用global()声明;
全局变量一般作常量使用;
作用域为定义的模块,从定义位置开始直到模块结束。
尽量少的定义全局变量;
局部变量:
在函数体内声明的变量;
局部变量的引用比全局变量快,优先考虑使用;
如果全局和局部变量同名,则在函数内隐藏全局变量,只使用同名的局部变量。
a = 3 #全局变量
def test01():
b = 3 #局部变量
#如果要在函数内改变全局变量的值,增加globa关键字声明
global a
a = 100
print(b+2+a)
print(a)
print(locals()) #打印输出的局部变量
print(globals()) #打印输出的全局变量
test01()
print(a)
》》》
105
100
{'b': 3}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001511D6C0940>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/Desktop/python/mypython02/mypython19.py', '__cached__': None, 'a': 100, 'test01': <function test01 at 0x000001511D86BB80>}
100
区分变量是出于局部作用域还是全局作用域的四条法则:
如果变量在全局作用域中使用(即在所有函数之外),它就是全局变量;
如果在一个函数中,有针对该变量的global语句,它就是全局变量;
否则,如果该变量用于函数中的赋值语句,它就是局部变量;
但是,如果该变量没有用在赋值语句中,它就是局部变量。
第五章 列表
列表数据类型
列表是一个值,包含多个字构成的序列:[1,2,3] ; ['cat','dog','bear'] ; [](空列表)
创建列表:newList = []
使用列表
列表可以包含任何类型的数据(数字、字符串、对象、其他列表),并且可以是混合类型:my_list = [2,6,8,'hello',myteacher,another_list]
可以按元素的索引(index)号从列表获取单个元素,列表索引从0开始:
>>> letters = ['a','b','c','d']
>>> print(letters[0])
>a
列表“分片”
使用索引从列表一次获取多个元素,这叫做列表分片(slicing)
>>> letters = ['a','b','c','d','e']
>>> print(letters[1:4]) #分片获取元素时会从第一个索引开始到第二个索引之前停止,即取回的项数为两个索引数之差
>['b','c','d'] #对列表分片时取回的是另一个列表,称为原列表的一个分片,这个分片时原列表的部分副本
print(letters[:2]) #表示从列表起始位置一直到(不包括)指定索引之间的所有元素
print(letters[2:]) #表示从指定索引到列表末尾的所有元素
print(letters[:]) #表示得到整个列表
修改元素
>>> letters = ['a','b','c','d','e']
>>> letters[2] = 'z'
>>> print(letters)
>['a','b','z','d','e']
向列表添加元素
向列表增加元素,可以使用append():
>>> friends = ['a','b','c'] #在向列表添加元素之前必须先创建列表
>>> friends.append(['d','e','f']) #python中用对象做某种处理:变量名.对对象做的操作
>>>print(friends)
>['a','b','c',['d','e','f']] #append()会把元素增加到列表末尾
扩展列表,可以使用extend()在列表末尾增加多个元素:
>>> friends.extend(['d','e','f']) #注意extend()和append()的区别
>>> print(friends)
>['a','b','c','d','e','f']
插入一个元素,可以使用insert()在列表的指定位置插入一个元素:
>>> friends.insert(1,'e') #将e增加到列表中索引为1的位置
>>> print(friends)
>['a','e','b','c'] #原来位于索引1位置的b向后移动一个位置
从列表删除元素
从列表中删除所选择的元素,可以使用remove():
>>> letters = ['a','b','c','d','e']
>>> letters.remove('c') #不需要知道元素在列表中的具体位置,只需要知道元素在列表中
>>> print(letters)
>['a','b','d','e']
用索引从列表中删除元素,可以使用del:
>>> del letters[3]
>>>print(letters)
>['a','b','c','e']
搜索列表
查找元素是否在列表中,可以使用in():
if 'a' in letters
print("find 'a' in letters")
else
print("didnt found 'a' in letters")
查找元素位于列表的位置,可以使用index()方法:
print(letters.index('d'))
列表排序
按正序排序,可以使用sort():
>>>letters = ['d','b','c','a','e']
>>>letters.sort() #sort()会按字母(数字)顺序对字符串从小到大排序
>>>print(letters) #sort()会在原地修改列表
>['a','b','c','d','e']
按逆序排序,可以使用reverse():
>>>letters = ['d','b','c','a','e']
>>>letters.reverse() #reverse()会按字母(数字)顺序对字符串从大到小排序
>>>print(letters) #reverse()会在原地修改列表
>['e','d','c','b','a']
或者向sort()增加一个参数,可以让它按逆序排序:
>>>letters = ['d','b','c','a','e']
>>>letters.sort(reverse = True)
>>>print(letters)
>['e','d','c','b','a']
以上方法都会对原来的列表做出修改,可以利用分片的方法建立列表副本再进行修改,也可以使用sorted():
>>>letters = ['d','b','c','a','e']
>>>new_letters = sorted(letters)
>>>print(letters)
>>>print(new_letters)
>['d','b','c','a','e']
>['a','b','c','d','e']
增加的赋值操作
增强的赋值操作符:
| 增强的赋值语句 | 与增强的赋值语句等价的赋值语句 |
|---|---|
| spam += 1 | spam = spam + 1 |
| spam -= 1 | spam = spam - 1 |
| spam *= 1 | spam = spam * 1 |
| spam /= 1 | spam = spam /1 |
| spam %= 1 | spam = spam % 1 |
方法
方法和函数是一回事,只是它是调用在一个值上。
例如,如果一个列表之存储在spam中,可以在这个列表上调用index()列表方法,就像spam.index('hello')一样,方法部分跟在这个值后面,以一个句点分隔。
类似列表的类型:字符串和元组
可以将字符串认为是单个文本字符的列表,对列表的许多操作也可以用于字符串
>>>name = 'Zophie'
>>>name[0]
>'Z'
>>>'Zo' in name
>True
可变和不可变数据类型
列表是“**可变”**的数据类型,它可以添加、删除和改变;字符串是“不可变的”。
“改变”一个字符串的正确释放就是使用切片和连接,构造一个“新的”字符串:
>>>name = 'Zophie a cat'
>>>newName = name[0:7] + 'the' + name[8:12]
>>>newName
>'Zophie the cat'
元组数据类型
元组输入时用圆括号(),而不是用方括号[],且是不可改变的。
如果元组中只有一个值,可以在括号内跟上一个逗号,表明这是一个元组:
>>> type(('hello',))
> <type 'tuple'>
用list()和tuple()函数来转换类型
函数list()和tuple()将返回传递给它们的值的列表和元组版本:
>>>tuple(['cat','dog',5])
>('cat','dog',5)
>>>list(['cat','dog',5])
>['cat','dog',5]
引用
变量保存字符串和整数值:
>>>spam = 42 #42赋值给spam比那辆
>>>cheese = spam #拷贝spam中的值,将它赋给cheese
>>>spam =100 #将spam中的值改变为100时不影响cheese中的值
>100
>>>cheese
>42
变量保存列表:
>>>spam = [0,1,2,3,4,5] #将列表赋给一个变量时,实际上是将列表的“引用”付给了该变量。
>>>cheese = spam #引用是一个值,指向某些数据。
>>>cheese[1] = 'hello'
>>>spam
>[0,'hello',2,3,4,5]
>>>cheese
>[0,'hello',2,3,4,5]
copy模块的copy()和deepcopy()函数
copy.copy()可以用来复制列表或字典这样的可变值:
>>>import copy
>>>spam = ['A','B','C','D']
>>>cheese = copy.copy(spam)
>>>cheesep[1] = 42
>>>spam
>['A','B','C','D']
>>>cheese
>['A',42,'C','D']
第六章 字典和结构化数据
字典数据类型
“字典”是许多值的集合,但字典的索引可以使用不同数据类型。字典的索引被称为“键”,键入其相关联的值被称为“键-值”对。
在代码中,字典输入时带花括号{}:
>>>myCat = {'size':'fat','color':'white','disposition':'quiet'}
>>>myCat['size']
>'fat'
这个字典的键是'size','color','disposition',这些键相应的值是'fat','white','quiet'。
字典与列表
字典不排序,列表排序
>>>spam = ['cats','dogs','sheep']
>>>temp = ['dogs','cats','sheep']
>>>spam == temp
>False
>>>spam = {'cats','dogs','sheep'}
>>>temp = {'dogs','cats','sheep'}
>>>spam == temp
>True
key()、values()和items()方法
key()、values()和items()方法将返回类似列表的值,分别对应字典的键、值和键-值对。这些方法返回的值不是真正的列表,不能被修改,但这些数据(分别是dict_keys、dict_values、dict_items)可以用于for循环。
>>>spam = {'color':'red','age':'42'}
>>>for k in spam.key()
>>> print(k)
>color
>age
>>>for v in spam.values()
>>> print(v)
>red
>42
>>>>for i in spam.values()
>>> print(i)
>('color','red')
>('age',42)
如果想要得到一个真正的列表,可以把这些值传递给list函数:
>>>spam = {'color':'red','age':'42'}
>>>spam.key()
>['color','age']
>>>list(['color','age'])
>['color','age']
检查字典中是否存在键或值
in和not in操作符可以检查值是否存在于列表中,也可以检查某个键或值是否存在与字典中:
>>>spam = {'name':'Zophie','age':7}
>>>'name' in spam.keys()
>True
>>>'Zophie' in spam.values()
>True
>>>'color' in spam.keys()
>False
>>>'color' not in spam.keys()
>True
>>>'color' in spam #简写,相当于'color' in spam.keys()
>False
get()方法
get()方法有两个参数:要取得其值的键,以及如果该键不存在时返回的备用值。
>>>pricnicItems = {'apples':5,'cups':2}
>>>'I am bringing' + str(pricnicItems.get('cups',0)) + 'cups.'
>'I am bringing2cups.'
>>>'I am bringing' + str(pricnicItems.get('eggs',0)) + 'cups.'
>'I am bringing0cups.'
setdefault()方法
setdefault()可以为字典中某个键设置一个默认值,setdefault()有两个参数:第一个参数为要检查的键,第二个参数是如果该键不存在时要设置的值。如果该键确实存在,方法就会返回键的值。
>>>spam = {'name':'Pooka','age':5}
>>>spam.setdefault('color','black') #第一次调用setdefault()时,spam变量中字典变为{'color':'black','name':'Pooka','age':5}
>'black' #该方法返回值为black,因为现在该值被赋给键color
>>>spam
>{'color':'black','name':'Pooka','age':5}
>>>spam.setdefault('color','white') #该键的值没有被改编成white,因为spam变量已经有名为color的键
>'black'
>>>spam
>{'color':'black','name':'Pooka','age':5}
第七章 字符串操作
处理字符串
字符串以单引号开始和结束,如果要在字符串内使用单引号,有以下几种办法:
双引号
字符串也可以使用双引号开始和结束:
spam = "That is Lily's cat."
转义字符
如果在字符串中既要使用单引号也要使用双引号,那就要使用转义字符。
转义字符:让你输入一些字符,它们用其他方式是不可能放在字符串里的。转移字符包含一个倒斜杠(),紧跟着是想要添加到字符串中的字符:
spam = 'Say hi to Bob\'s mother.' #Bob\'s中的单引号有一个倒斜杠,所以它不是表示字符串结束的单引号
| 转义字符 | 打印为 |
|---|---|
| \’ | 单引号 |
| \" | 双引号 |
| \t | 制表符 |
| \n | 换行符 |
| \\ | 倒斜杠 |
如:
>>>print("Hello there!\nHow are you?\nI\'m doing fine.")
>Hello there!
>How are you?
>I'm fine.
原始字符串
可以在字符串开始的引号之前加上r,使它成为原始字符串。
原始字符串完全忽略所有转移字符,打印出字符串中所有的倒斜杠:
>>>print(r'That is Carol\'s cat)
>That is Carol\'s cat
用三重引号的多行字符串
多行字符串的起止是3个单引号或3个双引号,三重引号之间的所有引号、制表符或换行,都被认为是字符串的一部分。
Python的代码块缩进规则不适用于多行字符串。
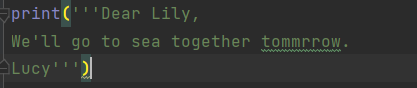
字符串下标和切片
可以将字符串Hello world看成一个列表,字符串中的每个字符都是一个表项,有对应下标:
'H e l l o w o r l d'
0 1 2 3 4 5 6 7 8 9 10
>>>spam = 'Hello world'
>>>spam[0:5]
>'Hello'
字符串切片并没有改变原来的字符串,可以从一个变量中获取切片,记录在并一个变量中:
>>>spam = 'Hello world'
>>>fizz = spam[0:5]
>>>fizz
>'Hello'
用字符串的in和not in操作符
用in和not in连接两个字符串得到的表达式,将求值为布尔值True或False:
>>>'Hello' in 'Hello World'
>True
>>>'HELLO' in 'Hello World'
>False
有用的字符串方法
字符串方法upper()、lower()、isupper()和islower()
upper()和lower()字符串方法返回一个新字符串,其中原字符串的所有字母都被转换为大写或小写,非字母字符保持不变:
>>>spam = 'Hello world!'
>>>spam = spam.upper() #原字符串的所有字母都被转换为大写
>>>spam
>'HELLO WORLD!'
>>>spam = spam.lower() #原字符串的所有字母都被转换为小写
>'hello world'
upper()和lower()字符串方法返回的是新字符串,要想改变原字符串就要将新字符串赋给保存原字符串的变量,即spam = spam.upper()
如果字符串所有字母都是大写或小写,isupper()和islower()方法就会相应地返回布尔值True,否则返回False:
>>>spam = 'Hello world'
>>>spam.islower()
>False
>>>spam.isupper()
>False
>>>'Hello'.isuppper()
>True
>>>'abc12345'.islower()
>True
>>>'12345'.islower()
>False
>>>'12345'.isupper()
>False
也可以在返回的字符串上继续调用字符串方法:
>>>'Hello'.upper()
>'HELLO'
>>>'Hello'.upper().lower()
>'hello'
>>>'Hello'.lower().islower()
>True
isX字符串方法
还有几个以is开始的字符串方法,这些方法返回一个布尔值,描述字符串的特点:
isalpha()返回True,如果字符串只包含字母,并且非空;
isalnum()返回True,如果字符串只包含字母和数字,并且非空;
isdecimal()返回True,如果字符串只包含数字字符,并且非空;
isspace()返回True,如果字符串只包含空格、制表符和换行,并且非空;
istiale()返回True,如果字符串仅包含以大写字母开头、后面都是小写字母的单词。
字符串方法startwith()和endswith()
startwith()和endswith()方法返回True,如果它们所调用的这字符串以该方法传入的字符串开始或结束,否则方法返回False:
>>>'Hello world'.startwith('Hello')
>True
>>>'Hello world'.endwith('world')
>True
>>>'abc123'.startwith('Hello')
>False
>>>'abc123'.endwith('12')
>False
>>>'Hello world'.startwith('Hello world')
>True
>>>'Hello world'.endwith('Hello world')
>True
字符串方法join()和split()
如果有一个字符串列表,需要将它们连接起来,称为一个单独的字符串,可以用join()方法。
join()方法有一个字符串上调用,参数是一个字符串列表,返回一个字符串,返回的字符串由传入的列表中每一个字符串连接而成:
>>>','.join(['cats','rats','bats'])
>'cats,rats,bats' #调用join()方法的字符串呗插入到列表参数中每个字符串的中间
>>>' '.join(['My','name','is','Simon'])
>'My name is Simon'
join()方法是针对多个字符串而调用的,并且传入一个列表值;
split()方法针对一个字符串调用,返回一个字符串列表:
>>>'My name is Simon'.split()
>['My','name','is','Simon']
默认情况下字符串'My name is Simon'按照各种空白字符分割,比如空格、制表符或换行符,这些空白字符不包含在返回列表的字符串中。
也可以向split()方法传入一个分割字符串,指定按照不同的字符串分割:
>>>'MyABCnameABCisABCSimon'.split(ABC)
>['My','name','is','Simon']
用rjust()、ljust()和center()方法对齐文本
rjust()和ljust()方法返回调用它们的字符串的填充版本,通过插入空格来对齐文本,这两个方法的第一个参数是一个整数长度,用于对齐字符串:
>>>'Hello'.rjust(10) #右对齐
>' Hello'
>>>'Hello'.ljust(10) #左对齐
>'Hello '
rjust()和ljust()方法的第二个可选参数将指定一个填充字符,取代空格字符:
>>>'Hello'.rjust(10,'*') #右对齐
>'**********Hello'
>>>'Hello'.ljust(10,'-') #左对齐
>'Hello----------'
center()方法可使对象居中:
>>>'Hello'.center(10,'*') #居中
>'**********Hello*********'
用strip()、rstrip()和lstrip()删除空白字符
strip()、rstrip()、lstrip()能够删除字符串开头或末尾、左边、右边的空白字符(空格、制表符和换行符),返回一个新的字符串:
>>>spam = ' Hello world '
>>>spam.strip()
>'Hello world'
>>>spam.lstrip()
>'Hello world '
>>>spam = rstrip()
>' Hello world'
有一个可选的字符串参数,指定两边的哪些字符应该删除:
>>>spam = 'SpamSpamBaconSpamEggsSpamSpam' #向strip()传输参数ampS
>>>spam.strip('ampS') #删除在两端出现的a、m、p、S,字符顺序不重要
>'BaconSpamEggs'

















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









