




 本文介绍了ChatGPT如何通过结合监督学习和人类反馈强化学习(RLHF)来解决大型语言模型如GPT-3的一致性问题。RLHF通过模拟人类偏好和使用PPO算法微调模型,提高其输出的有用性、真实性和无害性。然而,这种方法也存在局限性,包括依赖于标注者的主观偏好和缺乏对照研究。
本文介绍了ChatGPT如何通过结合监督学习和人类反馈强化学习(RLHF)来解决大型语言模型如GPT-3的一致性问题。RLHF通过模拟人类偏好和使用PPO算法微调模型,提高其输出的有用性、真实性和无害性。然而,这种方法也存在局限性,包括依赖于标注者的主观偏好和缺乏对照研究。
选自Assembly AI,作者:Marco Ramponi,机器之心编译
ChatGPT 是 OpenAI 发布的最新语言模型,比其前身 GPT-3 有显著提升。与许多大型语言模型类似,ChatGPT 能以不同样式、不同目的生成文本,并且在准确度、叙述细节和上下文连贯性上具有更优的表现。它代表了 OpenAI 最新一代的大型语言模型,并且在设计上非常注重交互性。
OpenAI 使用监督学习和强化学习的组合来调优 ChatGPT,其中的强化学习组件使 ChatGPT 独一无二。OpenAI 使用了「人类反馈强化学习」(RLHF)的训练方法,该方法在训练中使用人类反馈,以最小化无益、失真或偏见的输出。
本文将剖析 GPT-3 的局限性及其从训练过程中产生的原因,同时将解释 RLHF 的原理和理解 ChatGPT 如何使用 RLHF 来克服 GPT-3 存在的问题,最后将探讨这种方法的局限性。
大型语言模型中的能力与一致性
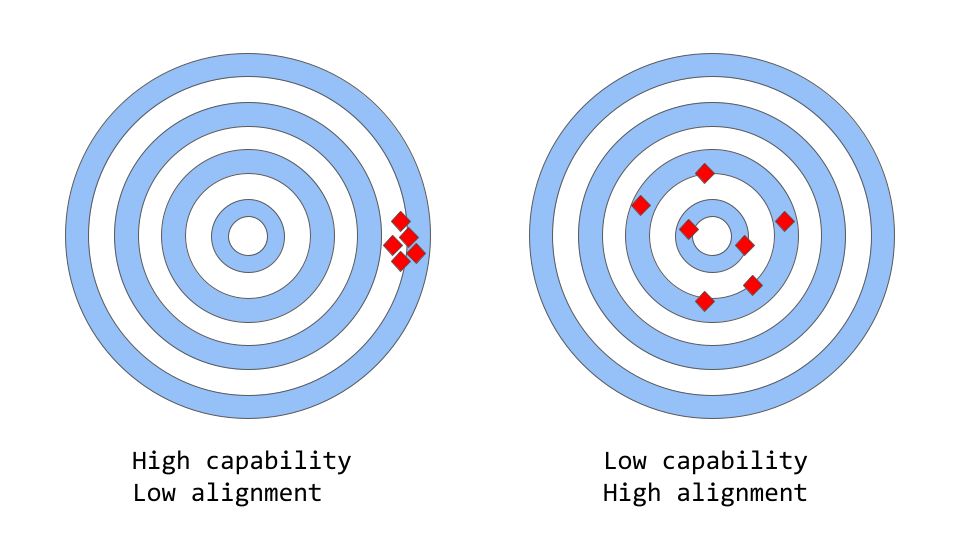
「一致性 vs 能力」可以被认为是「准确性 vs 精确性」的更抽象的类比。
在机器学习中,模型的能力是指模型执行特定任务或一组任务的能力。模型的能力通常通过它能够优化其目标函数的程度来评估。例如,用来预测股票市场价格的模型可能有一个衡量模型预测准确性的目标函数。如果该模型能够准确预测股票价格随时间的变化,则认为该模型具有很高的执行能力。
一致性关注的是实际希望模型做什么,而不是它被训练做什么。它提出的问题是「目标函数是否符合预期」,根据的是模型目标和行为在多大程度上符合人类的期望。假设要训练一个鸟类分类器,将鸟分类为「麻雀」或「知更鸟」,使用对数损失作为训练目标,而最终目标是很高的分类精度。该模型可能具有较低的对数损失,即该模型的能力较强,但在测试集上的精度较差,这就是一个不一致的例子,模型能够优化训练目标,但与最终目标不一致。
原始的 GPT-3 就是非一致模型。类似 GPT-3 的大型语言模型都是基于来自互联网的大量文本数据进行训练,能够生成类似人类的文本,但它们可能并不总是产生符合人类期望的输出。事实上,它们的目标函数是词序列上的概率分布,用来预测序列中的下一个单词是什么。
但在实际应用中,这些模型的目的是执行某种形式的有价值的认知工作,并且这些模型的训练方式与期望使用它们的方式之间存在明显的差异。尽管从数学上讲,机器计算词序列的统计分布可能是建模语言的高效选择,但人类其实是通过选择最适合给定情境的文本序列来生成语言,并使用已知的背景知识和常识来辅助这一过程。当语言模型用于需要高度信任或可靠性的应用程序(如对话系统或智能个人助理)时,这可能是一个问题。
尽管这些基于大量数据训练的大模型在过去几年中变得极为强大,但当用于实际以帮助人们生活更轻松时,它们往往无法发挥潜力。大型语言模型中的一致性问题通常表现为:<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









