




基本情况说明
应用功能:
读取本地文件,向量化后存储到本地文件数据库中。
开发框架:
langchain
嵌入模型:
text-embedding-v4
数据库
chroma
报错全部信息:
ValueError: status_code: 400 code: InvalidParameter message: <400> InternalError.Algo.InvalidParameter: Value error, batch size is invalid, it should not be larger than 10.: input.contents
报错情况说明
参考百炼控制台,最大行数有限制存在。
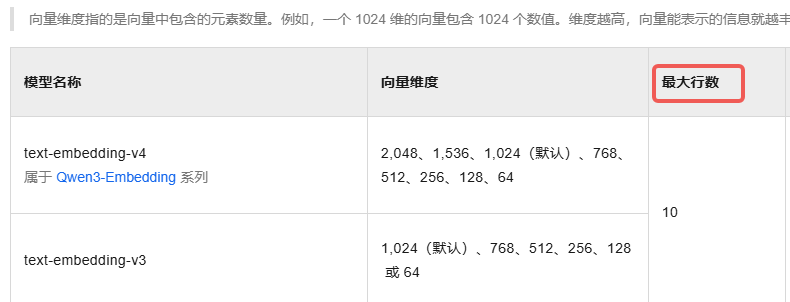
由于整个调用过程未显式传递batch_size参数,且整个调用过程由Chroma内部调用,导致问题不好定位。
解决方案:
将读取的文档内容进行分割,批量入库。
# 分批处理文档
batch_size = 10
for i in range(0, len(split_docs), batch_size):
batch_docs = split_docs[i:i+batch_size]
if i == 0:
# 第一批文档创建数据库
vectordb = Chroma.from_documents(
documents=batch_docs,
embedding=embedding,
persist_directory=persist_directory
)
else:
# 后续批次添加到数据库
vectordb.add_documents(batch_docs)
说到最后
以上。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









