



《A Deep Learning-Based Automatic Data Acquisition System for Medical Monitors》
论文背景:
在医疗手术进行过程中,必须有专业医护人员对病人的生命体征信息进行实时的监测与反馈,以便主刀医生做出输液、输血等决定,然而目前的医疗设备缺乏自动数据采集与记录功能,并且医疗设备的传输接口具有非统一性和专有性,给记录信息带来了极大的挑战。
目前,各种医疗数据显示设备的检测数据主要依靠人工记录和输入。人工记录数据的完整性和正确性很大程度上取决于现场人员的专业水平,长期的重复性工作会导致操作人员注意力分散,影响数据的真实性。
本文方法:
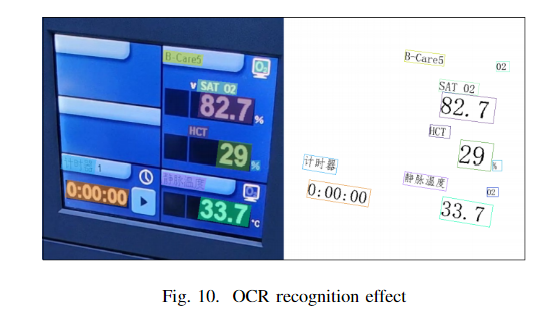
本文介绍了一种基于计算机视觉的屏幕分割和文本识别系统。该系统允许手术设备医生佩戴头戴式摄像头捕捉实时视频,并通过 RTSP(实时流协议)在 PC 端提取摄像头的视频流,之后对摄像头捕捉到的视频流利用 YOLO算法和 OCR(光学字符识别)技术作为主要工具来进行屏幕分割和文本识别,通过此方法,清晰图片的 OCR 识别准确率也可达到 95% 以上。最后,采集的数据将被格式化并传输到医院的数据记录系统。
面临的挑战:
1. 动态摄像头会带来比静态摄像头更多的困难,如操作人员佩戴摄像头导致的画面角度不当、画面经常旋转、画面抖动导致的模糊、手术室干扰噪音等因素,这给我们系统的稳定性和可靠性带来巨大挑战。
2. 深度学习在实时视频处理方面面临挑战,需要对摄像头传输的视频流进行分割、跟踪、校正、文本识别等处理。
3. 信息传输和选择正确的传输方式与医院系统交互面临挑战。
算法细节:
1. YOLOv8的损失函数使用BCE,回归损失用CIOU;
2. OCR:
图像进入文本位置检测模型后,该模型将识别并输出可能存在文本的多个区域的轮廓。在输出这些轮廓的同时,还会以百分比的形式输出置信度推断。删除置信度低的参数后,收集剩余的轮廓线并与原始图像进行比较和切割,从而获得一组可能包含文字的图像。图像集分类后将被发送到文本内容识别模型进行文本检测。检测结果将包括文本 ID 和置信度。同样,置信度低的信息会被删除,剩下的文本 ID 会与预先存储的字典文件进行比较,以还原文本内容。最后,结合文本内容信息和文本位置信息,将识别出的文本打印在原始图像的相应位置,方便用户查看,从而实现对屏幕的识别和检测.
文本位置检测使用DBNet算法。与常见的基于分割的文本检测算法相比,DBNet 最大的不同在于其阈值图。它不使用固定值,而是通过网络预测图像每个位置的阈值,从而更好地分离文本背景和前景。
文本内容识别使用SVTR算法。 首先,采用渐进式重叠补丁嵌入技术将图像划分为多个重叠补丁进行特征提取。然后,混合块用于特征混合,包括全局混合以评估所有字符成分之间的依赖关系,以及局部混合以评估预定义窗口内各成分之间的相关性。接下来是合并,将多个特征合并为更高级别的特征。最后,在组合和预测阶段,所有特征被合并为一个特征向量,并使用线性分类器进行预测,以获得字符序列。


















 3765
3765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









