










1. 如何评价一个系统的性能
在文章的开始,我们需要明白几个问题
1. 为什么要进行系统性能测试评估 2. 什么是性能测试 3. 评价一个系统的性能的指标有哪些
0x1: 为什么要进行系统性能测试评估
性能测试的目的是验证系统(或者软件)是否能够达到预期提出的性能指标,同时发现系统中存在的性能瓶颈,最后起到优化系统的目的。包括以下几个方面
1. 评估系统的能力 测试中得到的负荷和响应时间数据可以被用于验证所计划的模型的能力,并帮助作出决策 2. 识别体系中的弱点 受控的负荷可以被增加到一个极端的水平,并突破它,从而修复体系的瓶颈或薄弱的地方 3. 系统调优 重复运行测试,验证调整系统的活动得到了预期的结果,从而改进性能 4. 检测系统中的问题 长时间的测试执行可导致程序发生由于内存泄露引起的失败,揭示程序中的隐含的问题或冲突 5. 验证稳定性(resilience)可靠性(reliability) 在一个生产负荷下执行测试一定的时间是评估系统稳定性和可靠性是否满足要求的唯一方法
0x2: 什么是性能测试
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。从目的来看,性能测试可以分为2种:
//这两者可以结合进行 1. 负载测试 通过负载测试,确定在各种工作负载下系统的性能,目标是测试当负载逐渐增加时,系统各项性能指标的变化情况 2. 压力测试 压力测试是通过确定一个系统的瓶颈或者不能接受的性能点,来获得系统能提供的最大服务级别的测试
0x3: 评价一个系统的性能的指标有哪些
在每种不同的系统架构的实施中,开发人员可能选择不同的性能测试实现方式,造成实际情况纷繁复杂。由于工程和项目的不同,所选用的度量,评估方法也有不同之处。不过仍然有一些通用的步骤帮助我们完成一个性能测试项目。步骤如下
1. 制定目标和分析系统 2. 选择测试度量的方法 3. 学习的相关技术和工具 4. 制定评估标准 5. 设计测试用例 6. 运行测试用例 7. 分析测试结果
在本文中,我们将着重了解如下几个维度的指标
1. 系统吞度量 2. 用户并发量 3. 网络上下行数据量 4. 客户端-服务端TCP同时长连接数量
2. 系统吞度量
0x1: 系统吞度量要素
一个系统的吞度量(承压能力)与很多因素(指标)紧密相关
1.资源利用率
这里所谓的资源是对于系统中的一个抽象的概念,它包括很多方面
1) reqeust对CPU消耗
单个reqeust对CPU消耗越高,外部系统接口、IO影响速度越慢,系统吞吐能力越低,反之越高
2) 内存负载
系统对系统内存、vm虚拟内存、swap交换区的使用情况
3) IO负载消耗
系统在运行中常常会涉及到大量的磁盘读写操作
磁盘有两个重要的参数: Seek time、 Rotational latency。正常的I/O计数为:1000/(Seek time+Rotational latency)*0.75
在此范围内属正常。当达到85%的I/O计数以上时则基本认为已经存在I/O瓶劲。理论情况下,磁盘的随机读计数为125、顺序读计数为225。对于数据文件而言是随机读写,日志文件是顺序读写
2.外部接口
一个系统会将系统内的功能封装成接口(RESTFUL、SOAP)的形式向外部提供,这些外部接口和内部的代码处理逻辑是强关联的
3.QPS/TPS(TPSTransactionsPerSecond)
QPS(TPS) = 并发数 / 平均响应时间
每秒钟request/事务数量,它是软件测试结果的测量单位,一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。
事务可以从客户端角度进行定义。如
1) 一个登录的POST请求可定义为一个事务
2) 一个文件上传下载的动作也可定义为一个事务
3) 一组连续的请求操作也可定义一个事务
事务也可从服务器端定义,如
1) 执行一个数据库事务
2) 执行一段存储过程
3) 执行一个服务器请求等。
理解了事务,再理解TPS,TPS需要结合性能测试场景来说明:
1) 单体测试
1.1) 本次测试只测登录这一功能,便于分析和寻找瓶颈
1.2) 也可做并发测试
TPS=总事务数/总时间(秒)
2) 混合测试
多种模块一起进行测试,更符合真实场景,便于对服务器的整体处理能力进行评估
TPS=单个事务的TPS总和。
大多数情况下,我们使用加权协函数平均方法来计算客户机的得分,测试软件就是利用客户机的这些信息使用加权协函数平均方法来计算服务器端的整体TPS得分
4.并发数
系统同时处理的request/事务数
5.响应时间
用于测量完成一个特定请求需要花费多少时间。它是一个非常重要的度量值因为它是用户体验的一个指数。尽管这样,你必须确保你理解你测量的是什么
1) 系统级的反应时间
2) 组件级的反应时间
它们是完全不同的,因为系统级包括像队列时间这样的变量是差别很大的
值得注意的是,响应时间同时也是不容易测量的度量值,因为它比其它的度量值更容易变化。因此你必需了解反应时间的分布。如果应用对你大部分用户的反应时间是2秒钟,而对10%用户的反应时间却是10秒钟,在这种情况下,你必须
知道这个反应时间的分布,才能精确地评估该问题和解决它。这就要测量它们的反应时间并且得到它们的标准偏差,理想的情况是用一个柱状图把反应时间的分布显示出来
Relevant Link:
http://www.360doc.com/content/10/1022/17/691214_63081271.shtml http://www.cnblogs.com/argb/p/3448649.html http://www.ha97.com/5095.html
3. 网络上下行数据量[带宽]
网络上下行数据量的总结可以从以下几个方面进行概述:
-
下行数据量:下行数据量主要指的是从网络服务器向用户设备发送的数据量,包括网页内容、视频流、文件下载等。随着互联网技术的发展,下行数据量呈现出快速增长的趋势。例如,5G技术的推广和应用,使得下行数据传输速度大大提高,用户可以更快地下载大型文件和流媒体内容。此外,随着高清视频和大数据应用的普及,下行数据量的需求也在不断增加。
-
上行数据量:上行数据量主要是指用户设备向网络服务器发送的数据量,包括文件上传、在线互动、视频会议等。与下行数据量相比,上行数据量的增长相对较慢,但随着远程工作、在线教育和在线娱乐等应用的普及,上行数据量的需求也在逐渐增加。例如,在线视频会议和远程教育中,参与者需要上传自己的视频流,这对上行数据量的要求较高。
-
网络基础设施的发展:随着5G、千兆光网等新型基础设施的建设和推广,网络上下行数据量的传输速度和容量得到了极大的提升。这不仅满足了用户对高速网络的需求,也为大数据、云计算等新兴技术的发展提供了坚实的基础。
-
网络安全与隐私保护:随着数据量的增加,网络安全和隐私保护也成为了重要的问题。网络服务提供商需要采取有效的安全措施,保护用户的个人信息和隐私不受侵犯。同时,政府和企业在法律法规方面也需要加强对网络安全的监管,确保网络环境的安全和稳定。
综上所述,网络上下行数据量的增长不仅反映了互联网技术的进步和应用的普及,也对网络安全、隐私保护提出了更高的要求。未来,随着更多新兴技术的应用和普及,网络上下行数据量的需求将继续增长,同时也需要更多的技术创新和政策支持来应对这些挑战。
什么是宽带上行和下行?
宽带上行和下行是指网络传输中的两个方向。上行是指从用户端向网络服务器传输数据,而下行则是指从网络服务器向用户端传输数据。
简单来说,上行就是上传,下行就是下载。
宽带上行和下行速率测算工具
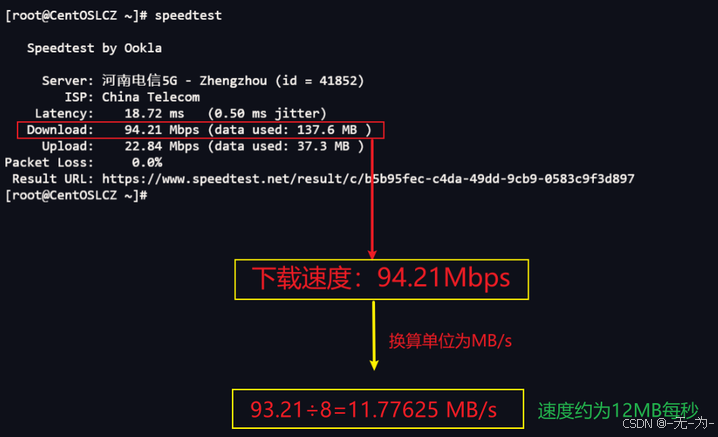
服务器测试宽带上行和下行速率的方法主要包括使用speedtest-cli命令行工具、下载测试法、Ping命令测试法、网站测试法和路由跟踪法。
-
使用speedtest-cli命令行工具:speedtest-cli是Speedtest.net提供的一个命令行版本,它可以在没有图形化桌面的环境中使用,非常适合在服务器上进行网速测试。通过安装speedtest-cli并运行相应的命令,可以测试服务器的上行和下行速率。这种方法可以提供较为准确的网速测试结果,并且操作简单方便12。
-
下载测试法:通过在服务器上放置一个大文件,然后从远程位置下载这个文件,通过测量下载速度来测试服务器的下行带宽。这种方法适用于需要大带宽支持的应用,如在线视频网站等,但需要服务商的配合3。
-
Ping命令测试法:通过ping服务商提供的IP地址,可以测试网络的稳定性,虽然这种方法主要是对带宽的估算,但它可以测试服务器的访问速度稳定性3。
-
网站测试法:利用网络上的免费网速测试网站进行测试,这些网站提供了可视化的测试过程,可以准确反映本地网络速率,无需下载安装插件或添加额外设备,使用简单方便3。
-
路由跟踪法:使用Tracert和winmtr(Windows)或traceroute和mtr(Linux)命令进行路由跟踪,这有助于诊断网络问题,但主要用于诊断网络连接问题,而不是直接测量带宽3。
综上所述,服务器测试宽带上行和下行速率的方法多样,可以根据具体需求和环境选择合适的方法进行测试。
宽带上行和下行的重要性
网络流畅度:宽带的上行和下行速率对于网络流畅度有着直接的影响。上行速率快,用户上传数据就快,反之则慢。下行速率快,用户下载数据就快,反之则慢。
视频通话:在进行视频通话时,上行速率决定了用户上传视频数据的速度,而下行速率则决定了接收方接收视频数据的速度。如果上行或下行速率不足,视频通话可能会出现卡顿、延迟等问题。
网络游戏:网络游戏需要实时传输数据,如果上行或下行速率慢,游戏体验就会受到影响。例如,如果上行速率慢,玩家在游戏中发送指令就会延迟;如果下行速率慢,玩家接收游戏画面就会卡顿。
常见问题及解决方法
问题:为什么我的宽带上行速率比下行速率慢?
解决方法:这可能是因为网络服务商对上行速率进行了限制,或者是因为你的网络设备性能不足。可以联系网络服务商或者更换更高端的网络设备来解决这个问题。
问题:我的宽带上下行速率不均衡,怎么办?
解决方法:这可能是因为网络服务商的线路设计不合理或者是因为你的网络设备性能不匹配。可以尝试联系网络服务商调整线路设置或者更换更合适的网络设备来解决问题。
问题:我的宽带上传下载速度很慢,怎么办?
解决方法:这可能是由于网络服务商提供的带宽不足或者是因为你的网络环境存在问题。可以尝试升级网络带宽或者优化网络环境来解决这个问题。同时,检查你的计算机系统是否运行正常,是否存在病毒等干扰因素。
4. 客户端-服务端TCP同时长连接数量
客户端-服务器TCP同时长连接数量远超过65535个。
首先,需要澄清的是,65535这个数字通常与TCP连接的端口号数量相关,而不是与同时可以维持的TCP连接数直接相关。
实际上,一台服务器可以同时维持的TCP连接数受到多种因素的影响,包括服务器的硬件资源(如内存)和操作系统配置(如最大文件描述符数量)。在理想情况下,服务器的最大并发TCP连接数可以通过增加内存和调整最大文件描述符数量等参数来超过10万,甚至上百万连接。
对于客户端而言,其同时建立的TCP连接数也受到限制,但这个数字远非65535。
由于TCP连接由四元组(源IP、源端口、目标IP、目标端口)唯一确定,而IP地址和端口号的组合数量极为庞大,理论上客户端可以建立的连接数非常巨大。然而,实际上由于硬件和软件的限制,这个数字并不能完全达到理论上的最大值2。
综上所述,65535这个数字通常指的是可用端口总数,而不是TCP连接数。
实际能够同时维持的TCP连接数受到多种因素的影响,包括服务器的硬件资源、操作系统配置以及客户端的能力,但远超过65535个连接。
TCP 连接状态数量统计
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
返回结果范例如下:
ESTABLISHED 1423
FIN_WAIT1 1
FIN_WAIT2 262
SYN_SENT 1
TIME_WAIT 962
1、统计某个端口的连接数【8080为例】
netstat -ant|grep -i 8080 |wc -l
2、统计某个服务的连接数【tomcat服务为例】
ps -ef| grep tomcat | wc -l
3、统计已连接上本台服务器的主机,状态为"established"的个数
netstat -na|grep ESTABLISHED|wc -l
4、查看哪些服务器连接到本机
netstat -anlp
5、查看本机那台服务器连接最多【以此可以判断连接过来的机器的异常问题,作下一步分析】
netstat -anput | grep “ESTABLISHED” | awk ‘{print $5}’| awk -F: ‘{print $1}’ | uniq | sort
6、查询正在与本机进行TCP通信的服务器IP及连接个数
netstat -an | grep “ESTABLISHED” | awk ‘{print $5}’| awk -F: ‘{print $1}’ | sort | uniq -c
7、查询本机某个端口占用的进程【以80端口为例】
netstat anlp |grep 80 #根据端口可以查询到占用这个端口的进程的pid
ps -ef|grep pid #可以根据pid查询到具体的某一个进程
8、查询本机等待关闭的连接数
nestat anlp |grep TIME_WAIT |wc -l
9、查询本机等待关闭的连接数的具体地址
netstat -anlp |grep TIME_WAIT
TIME_WAIT过多的优化方法
发现服务器存在大量TIME_WAIT状态的连接,通过调整内核参数解决:
编辑文件:vim /etc/sysctl.conf
加入或修改以下内容:
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
系统参数生效
/sbin/sysctl -p
参数说明:
net.ipv4.tcp_syncookies = 1 #表示开启SYN cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间;
5. 系统性能的指标计算
0x1: 响应时间: 对请求作出响应所需要的时间
1. 网络传输时间: N1+N2+N3+N4 2. 应用服务器处理时间: A1+A3 3. 数据库服务器处理时间: A2 4. 响应时间=N1+N2+N3+N4+A1+A3+A2
0x2: 并发用户数的计算公式
1. 系统用户数: 系统额定的用户数量,如一个OA系统,可能使用该系统的用户总数是5000个,那么这个数量,就是系统用户数
2. 同时在线用户数: 在一定的时间范围内,最大的同时在线用户数量
3. 同时在线用户数 = 每秒请求数RPS(吞吐量) + 并发连接数 + 平均用户思考时间
4. 平均并发用户数的计算: C = nL / T
1) C是平均的并发用户数
2) n是平均每天访问用户数(login session)
3) L是一天内用户从登录到退出的平均时间(login session的平均时间)
4) T是考察时间长度(一天内多长时间有用户使用系统)
5. 并发用户数峰值计算: C^约等于C + 3*根号C
其中C^是并发用户峰值,C是平均并发用户数,该公式遵循泊松分布理论
0x3: 吞吐量的计算公式
1. 从业务角度看
吞吐量可以用:
1) 请求数/秒
2) 页面数/秒
3) 人数/天或处理业务数/小时等单位来衡量
2. 从网络角度看,吞吐量可以用:
1) 字节/秒来衡量
3. 对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,他能够说明系统的负载能力
以不同方式表达的吞吐量可以说明不同层次的问题,例如
1. 以字节数/秒方式可以表示数要受网络基础设施、服务器架构、应用服务器制约等方面的瓶颈 2. 已请求数/秒的方式表示主要是受应用服务器和应用代码的制约体现出的瓶颈
0x4: 思考时间的计算公式
Think Time,从业务角度来看,这个时间指用户进行操作时每个请求之间的时间间隔,而在做新能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
在吞吐量这个公式中F=VU * R / T说明吞吐量F是VU数量、每个用户发出的请求数R和时间T的函数,而其中的R又可以用时间T和用户思考时间TS来计算:R = T / TS
下面给出一个计算思考时间的一般步骤:
1. 首先计算出系统的并发用户数 C=nL / T F=R×C 2. 统计出系统平均的吞吐量 F=VU * R / T R×C = VU * R / T 3. 统计出平均每个用户发出的请求数量 R=u*C*T/VU 4. 根据公式计算出思考时间 TS=T/R
6. IO负载
IO负载在大多数情况下指的是系统对磁盘的访问频率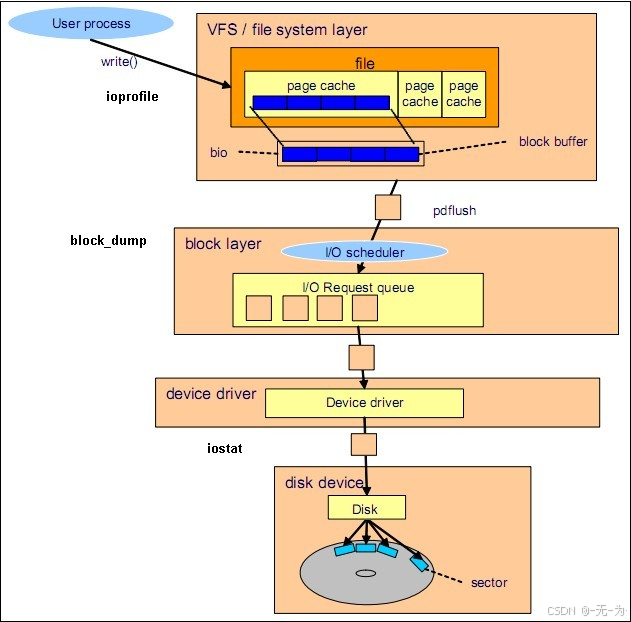
0x1: 系统级IO监控
iostat -xdm 1
1. rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s 1. wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s 3. r/s: 每秒完成的读 I/O 设备次数。即 rio/s 4. w/s: 每秒完成的写 I/O 设备次数。即 wio/s 5. rsec/s: 每秒读扇区数。即 rsect/s 6. wsec/s: 每秒写扇区数。即 wsect/s 7. rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节 8. wkB/s: 每秒写K字节数。是 wsect/s 的一半 9. avgrq-sz: 平均每次设备I/O操作的数据大小(扇区) 10. avgqu-sz: 平均I/O队列长度 11. await: 平均每次设备I/O操作的等待时间(毫秒) 12. svctm: 平均每次设备I/O操作的服务时间(毫秒) 13. %util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比
0x2: 进程级IO监控
当前系统哪些进程在占用IO?百分比是多少?占用IO的进程是在读?还是在写?读写量是多少?
iotop、pidstat
block_dump、iodump
iotop.stp
0x3: 业务级IO监控
当前进程某时间内,在业务层面读写了哪些文件(read, write)?读写次数是多少(read、write的调用次数)?读写数据量多少(read、write的byte数)?
ioprofile
0x4: 文件级IO监控
文件级IO监控可以配合/补充"业务级和进程级"IO分析。文件级IO分析,主要针对单个文件。回答当前哪些进程正在对某个文件进行读写操作
lsof、ls /proc/pid/fd、inodewatch.stp
Relevant Link:
http://www.cnblogs.com/peida/archive/2012/12/28/2837345.html http://itindex.net/detail/46239-linux-io-%E5%88%86%E6%9E%90



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











