




 博客介绍了MapReduce的由来,它是Google提出的面向大规模数据处理的并行计算模型,Doug Cutting基于Java开发了Hadoop开源框架。还阐述了Map和Reduce函数原型,最后提及Python中的并行计算,并给出相关参考。
博客介绍了MapReduce的由来,它是Google提出的面向大规模数据处理的并行计算模型,Doug Cutting基于Java开发了Hadoop开源框架。还阐述了Map和Reduce函数原型,最后提及Python中的并行计算,并给出相关参考。
MapReduce
(先挖个坑)
MapReduce由来
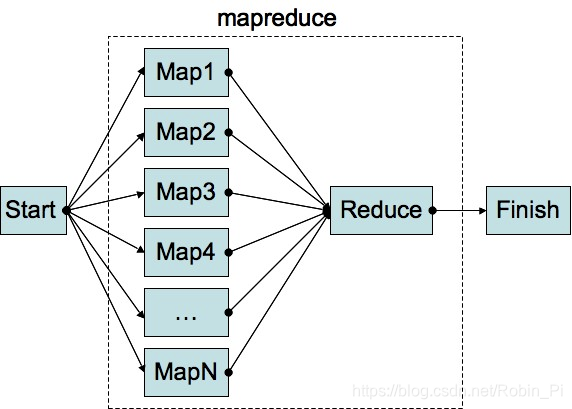
- MapReduce最早是由Google公司研究提出的一种面向大规模数据处理的并行计算模型和方法,论文地址:MapReduce: Simplified Data Processing on Large Clusters
- Doug Cutting 基于Java设计开发了一个称为Hadoop的开源MapReduce并行计算框架和系统
Map和Reduce
- Map 函数原型
map(*function*, *iterable*, *...*) -> Iterator
意思是map函数对第二个参数(或者后面更多的参数)进行迭代,将迭代的元素作为参数传递给function,function将处理过的结果是Iterator,是惰性序列(因此通过list()函数让它把整个序列都计算出来并返回一个list) - Reduce 函数原型
reduce(*function*, *iterable*[, *initializer*]) -> value
reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









