




 本文探讨了二分类问题中正例与负例的概念,解释了为何使用这种分类方式,并详细解析了混淆矩阵的四种结果:真正例、真负例、假正例和假负例,帮助读者深入理解分类算法的评估指标。
本文探讨了二分类问题中正例与负例的概念,解释了为何使用这种分类方式,并详细解析了混淆矩阵的四种结果:真正例、真负例、假正例和假负例,帮助读者深入理解分类算法的评估指标。
Why positive and negative?
一直不明白为什么二分类问题要用”正例“和”负例“来代替两中类别,这样不是太局限了么,其实类别之间本质上并没有什么”肯定“/”否定“和”阴性“/”阳性“之分(这些都只是人类主观观点).
一般来说,我们这样来进行约定:
预计会发生的事件叫做阳/正(Positive),
而把预计不会发生的事件叫做阴/负(Negative),
比如:
“狼来了”是正类别。
“没有狼”是负类别。
说白了,Positive 和 Negative 都是预测的结果。
而事件本身是可能发生也可能不发生的,经过预测和比对之后,我们可以做出一个判断——True:预测跟真实情况一致,所以叫“真”;False:预测跟真实情况相反,所以叫“假”。
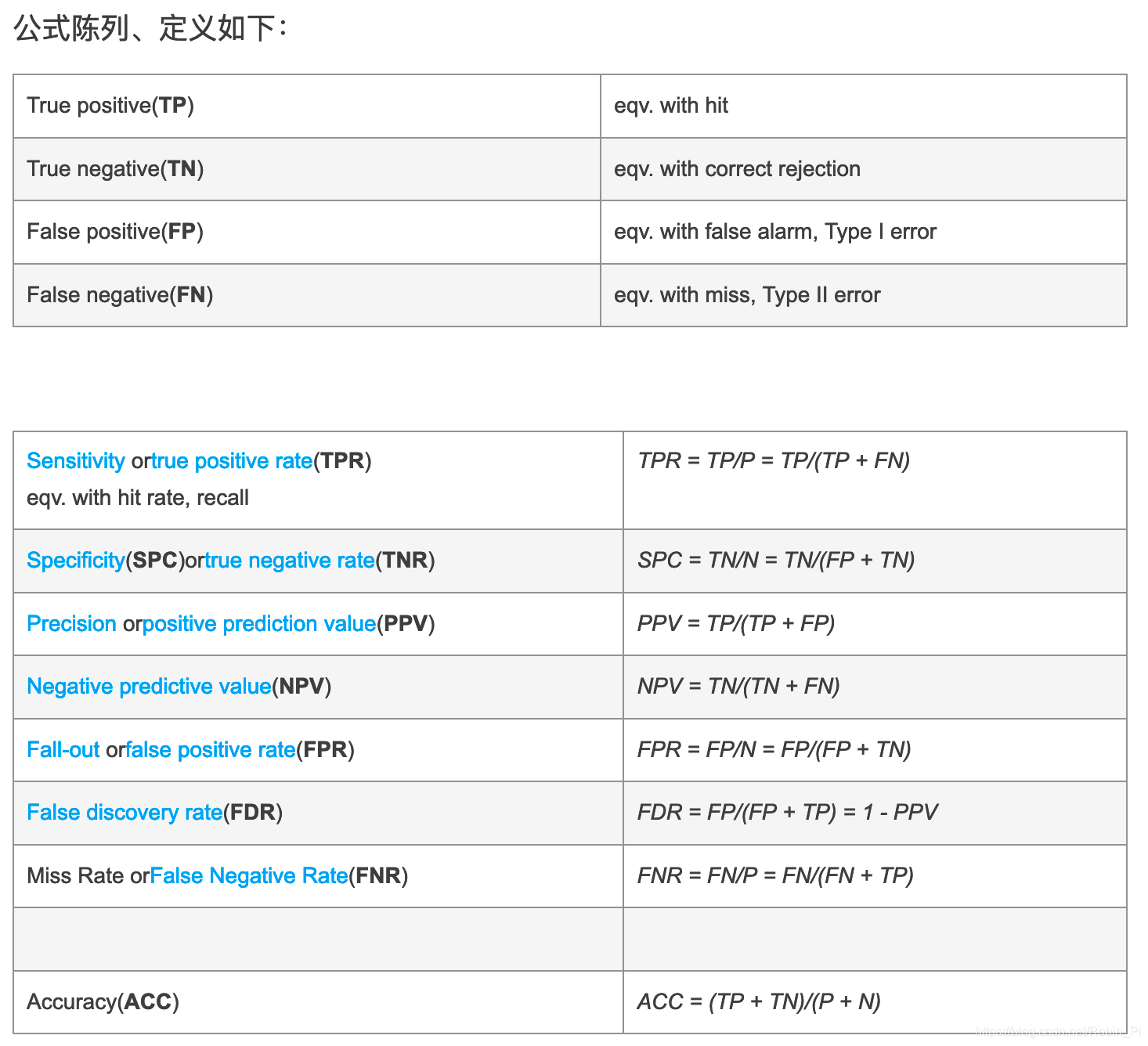
对二分类来说,四种可能的结果就是:
 真正例是指模型将正类别样本正确地预测为正类别。同样,真负例是指模型将负类别样本正确地预测为负类别。
真正例是指模型将正类别样本正确地预测为正类别。同样,真负例是指模型将负类别样本正确地预测为负类别。
假正例是指模型将负类别样本错误地预测为正类别,而假负例是指模型将正类别样本错误地预测为负类别。
- TP:
- TN:
- FP:
- FN:
假定一个实验有 P个positive实例,在某些条件下有 N 个negative实例。那么上面这四个输出可以用下面的偶然性表格(或混淆矩阵)来表示:

参考:

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









