




 本文介绍了在决策树分类中,如何利用混淆矩阵评估模型性能,重点关注精确度、召回率和F1分数。精确度衡量预测为正例的样本中实际正例的比例,召回率表示真实正例中被正确预测的比例,F1分数是精确度和召回率的调和平均数,用于平衡两者。在实际应用中,根据业务需求选择合适的评估指标。
本文介绍了在决策树分类中,如何利用混淆矩阵评估模型性能,重点关注精确度、召回率和F1分数。精确度衡量预测为正例的样本中实际正例的比例,召回率表示真实正例中被正确预测的比例,F1分数是精确度和召回率的调和平均数,用于平衡两者。在实际应用中,根据业务需求选择合适的评估指标。
问题的提出
如果决策树的目标是尽量捕获少数类,则准确率模型评估的意义不大,需要新的模型评估指标。简单来看,只需要查看模型在少数类上的准确率就好,只要能够将少数类尽量捕捉出来,就能够达到目的。
但是,新问题又出现了,对多数类判断错误后,会需要人工甄别或者更多的业务上的措施来一一排除判断错误的多数类,这往往伴随着很高的成本。比如银行在判断”一个申请信用卡的客户是否会出现违约行为“的时候,如果一个客户被判断为”会违约“,这个客户的信用卡申请就会被驳回,如果为了捕捉出”会违约“的人,大量地将”不不会违约“的客户判断为”会违约“的客户,就会有许多无辜的客户申请被驳回。信用卡对银行来说意味着利息收入,而拒绝了许多本来不会违约的客户,对银行来说就是巨大的损失。同理,大众在召回不符合欧盟标准的汽车时,如果为了找到所有不符合标准的汽车,而将一堆本来符合标准了的汽车召回,这个成本是不可估量的。
也就是说,单纯地追求捕捉出少数类,会使成本太高,而不顾及少数类,又无法达成模型的效果。所以,在现实中,往往在寻找捕获少数类的能力和将多数类判错后需要付出的成本的平衡。如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵。
混淆矩阵
混淆矩阵是二分类问题的多维衡量量指标体系,在样本不平衡时极其有用。在混淆矩阵中,我们将少数类认为是正例,多数类认为是负例。在决策树,随机森林这些普通的分类算法里,即是说少数类是1,多数类是0。在SVM里,就是说少数类是1,多数类是-1。
普通的混淆矩阵,一般使用{0,1}来表示。
混淆矩阵,阵如其名,十分容易让人混淆,在许多教材中,混淆矩阵中各种各样的名称和定义让大家难以理解和记忆。下面以一种简化的方式来显示标准二分类的混淆矩阵,如图所示:

其中,行代表预测情况,列则表示实际情况,positive表示阳性,即为真,negative则表示阴性,即为假。
因此,矩阵中四个元素分别表示:
TP(True Positive):真实为1,预测也为1
FN(False Negative):真实为1,预测为0
FP(False Positive):真实为0,预测为1
TN(True Negative):真实为0,预测也为0
基于混淆矩阵,有一系列不同的模型评估指标,这些评估指标的范围都在[0,1]之间,所有以11和00为分子的指标都是越接近1越好,所以01和10为分子的指标都是越接近0越好。对于所有的指标,用橙色表示分母,用绿色表示分子,则有:
模型整体效果:准确率
准确率Accuracy

准确率Accuracy是所有预测正确的所有样本除以总样本,通常来说越接近1越好。
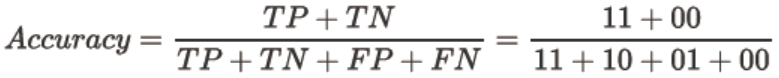
捕捉少数类的艺术:精确度,召回率和F1 score
精确度Precision

精确度Precision,又叫查准率,表示在所有预测结果为1的样例数中,实际为1的样例数所占比重。
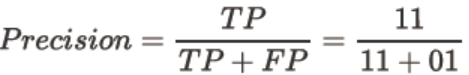
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9848
9848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









