




模型泛化
在得到模型之后,对模型进行分析~
1. 泛化性能分析
在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去改进从而使下次得到的model更加令人满意呢?
1.1 概论
-
泛化误差/预测误差
学习算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise). 在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error). -
偏差:描述模型输出结果的期望与样本真实结果的差距。
(“偏”——偏离,偏离真实的标签。) -
方差:描述模型对于给定值的输出稳定性。
(在统计学中,方差描述的是这个随机变量的离散程度,也就是该随机变量在其期望值附近的波动程度。)
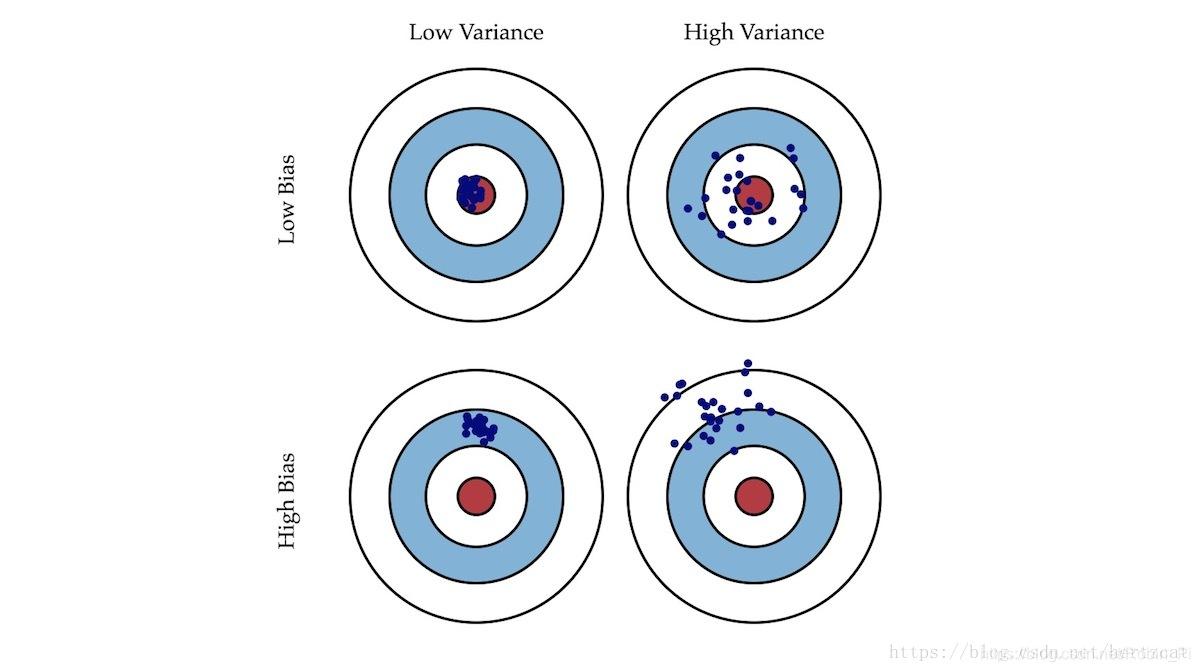
就像打靶一样,偏差描述了我们的射击总体是否偏离了我们的目标,而方差描述了射击准不准。
1.2 解释工具:”偏差-方差分解“
泛化误差 = 偏差 + 方差 + 噪声
算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise)。
在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error)。
假设:
-
测试样本:X
-
训练集:D
-
标记:yd(
有可能出现噪声使得 yd != y,即所谓的打标样本不纯) -
x 的真实标记:y
-
在训练集 D 上训练得到的模型 :f
-
模型 f 对 x 的预测输出:f(x;D)
-
模型 f 对 x 的 期望预测 输出: f ‾ \overline{f}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









