







 本文介绍了Hadoop中的两种文件存储格式:SequenceFile和MapFile。SequenceFile用于存储非排序的键值对,支持多种压缩方式。MapFile是在SequenceFile基础上增加了排序和索引功能,提高了检索效率。
本文介绍了Hadoop中的两种文件存储格式:SequenceFile和MapFile。SequenceFile用于存储非排序的键值对,支持多种压缩方式。MapFile是在SequenceFile基础上增加了排序和索引功能,提高了检索效率。
一、SquenceFile
文件中每条记录是可序列化,可持久化的键值对,提供相应的读写器和排序器,写操作根据压缩的类型分为3种。
---Write 无压缩写数据
---RecordCompressWriter记录级压缩文件,只压缩值
---BlockCompressWrite块级压缩文件,键值采用独立压缩方式
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如下图所示:
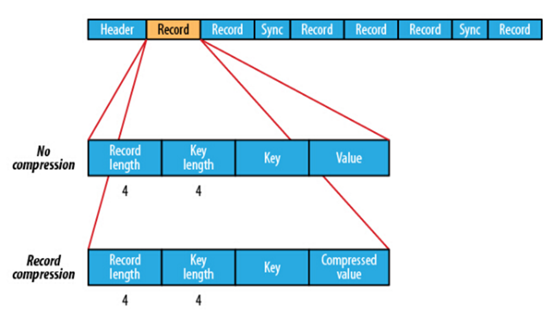
前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。
在recourds中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。
当保存的记录很多时候,可以把一串记录组织到一起同一压缩成一块。
在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
二、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
缺点:
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的
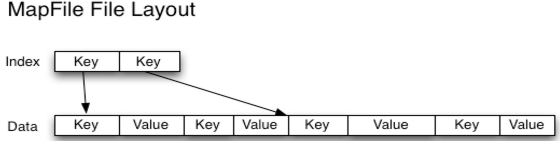
SequenceFile文件是用来存储key-value数据的,但它并不保证这些存储的key-value是有序的,而MapFile文件则可以看做是存储有序key-value的SequenceFile文件。MapFile文件保证key-value的有序(基于key)是通过每一次写入key-value时的检查机制,这种检查机制其实很简单,就是保证当前正要写入的key-value与上一个刚写入的key-value符合设定的顺序,但是,这种有序是由用户来保证的,一旦写入的key-value不符合key的非递减顺序,则会直接报错而不是自动的去对输入的key-value排序。
SequenceFile转换为MapFile
mapFile既然是排序和索引后的SequenceFile那么自然可以把SequenceFile转换为MapFile使用mapFile.fix()方法把一个SequenceFile文件转换成MapFile。

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









