




TSF微服务生产环境性能优化实战:JVM调优与成本效益平衡全指南
引言
随着微服务架构在企业级应用中的规模化落地,腾讯微服务框架(TSF)凭借其一站式服务治理、全链路监控、弹性部署等核心能力,成为金融、电商、政务等领域企业构建微服务体系的首选。但在生产环境中,基于Java的TSF微服务往往陷入“性能瓶颈”与“成本浪费”的双重困境:一方面,JVM层面的GC停顿过长、Metaspace泄漏等问题导致服务响应慢、可用性下降;另一方面,资源配置粗放(如过度扩容、资源超卖失控)造成云资源成本居高不下。
作为Java架构师,核心目标是从技术底层出发,打通“JVM调优-资源配置-成本控制”的全链路,既解决TSF微服务的性能痛点,又实现资源成本的最优控制。
本文结合生产级实战经验,深度剖析TSF微服务性能优化的核心路径,聚焦JVM调优与成本效益平衡,给出可落地的配置方案和实战案例,帮助开发者实现“高性能、低成本”的TSF微服务架构。
一、TSF Agent对Java应用的性能影响
TSF Agent是TSF实现无侵入服务治理的核心组件,通过字节码增强技术为Java应用注入服务注册发现、链路追踪、限流熔断等能力。但Agent的引入也可能带来性能损耗,需针对性分析和优化。
1.1 字节码增强原理:ASM与Java Instrumentation(无侵入治理的底层机制)
TSF Agent的无侵入治理能力依赖Java Instrumentation API和ASM字节码操作框架,其核心流程如下:
核心机制解读:
- Java Instrumentation:JVM启动时通过
-javaagent:/path/tsf-agent.jar参数加载Agent,Agent通过InstrumentationAPI注册ClassFileTransformer,拦截所有类的加载过程; - ASM框架:TSF Agent放弃反射(性能低),采用ASM直接操作Class文件的字节码——ASM以“访问者模式”解析字节码指令,在业务方法的入口/出口插入治理逻辑(如链路追踪的traceId注入、限流规则校验);
- 无侵入核心:增强过程发生在类加载阶段,业务代码无需修改,编译、打包流程完全无感知。
ASM的高效性保证了基础增强逻辑的性能损耗<5%,但如果Agent开启过多增强功能(如全链路埋点、细粒度监控),仍会导致方法执行耗时增加。
1.2 Metaspace增长分析:Agent类加载器泄漏案例
JDK8及以上版本中,Metaspace替代永久代存储类的元数据(类结构、方法信息、常量池等),其内存由本地内存分配,默认无上限,极易因类元数据无法回收导致OOM。
泄漏原因:
TSF Agent使用自定义类加载器(TsfAgentClassLoader)加载增强后的业务类,若Agent内部存在缓存未清理、多类加载器重复加载同一类等问题,会导致TsfAgentClassLoader无法被GC回收,其加载的类元数据常驻Metaspace,最终引发OOM。
典型案例:
某电商平台商品服务接入TSF Agent后,运行72小时出现Metaspace OOM,监控显示Metaspace使用率从初始20%持续增长至100%,核心日志如下:
java.lang.OutOfMemoryError: Metaspace
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:756)
at com.tencent.tsf.agent.core.loader.TsfAgentClassLoader.defineClass(TsfAgentClassLoader.java:128)
解决方案:
- 基础配置优化:通过
-XX:MetaspaceSize=256m设置初始阈值(触发第一次Metaspace GC的内存量),-XX:MaxMetaspaceSize=512m限制最大值,避免无上限增长; - 根治手段:每日凌晨低峰期重启应用(通过TSF定时任务实现),清理类加载器缓存;
- 版本升级:TSF Agent v1.8.0及以上版本修复了类加载器泄漏问题,可从底层解决该问题。
1.3 启动时间增加:Agent初始化耗时优化
接入TSF Agent后,Java应用启动时间平均增加5-10秒(核心服务可达15秒),核心原因是:
- Agent初始化时会扫描所有类(包括第三方依赖)并进行字节码增强;
- Agent加载链路追踪、配置中心、注册发现等组件,初始化流程复杂。
优化方案:
| 优化手段 | 配置示例 | 效果 |
|---|---|---|
| 关闭不必要的增强功能 | tsf.agent.trace.enable=false(非核心服务)tsf.agent.circuit.breaker.enable=false(无熔断需求) | 启动时间减少2-3秒 |
| 配置增强白名单 | tsf.agent.enhance.whitelist=com.company.goods.service.* | 仅增强业务核心类,扫描时间减少50% |
| 升级Agent版本 | 升级至v1.9.0+ | 优化类扫描逻辑,启动时间减少3-4秒 |
| 精简Agent依赖 | 移除Agent中无用的插件(如配置中心插件) | 启动时间减少1-2秒 |
二、JVM参数生产环境调优指南
JVM参数是TSF微服务性能的核心控制点,需结合TSF的服务治理特性(如限流、熔断)和容器部署环境,制定生产级配置。
2.1 G1GC参数:-XX:MaxGCPauseMillis=100(与TSF限流阈值联动)
G1GC是JDK9默认的垃圾收集器,适合TSF微服务“低延迟、高吞吐”的场景,其核心参数-XX:MaxGCPauseMillis需与TSF限流阈值联动。
核心问题:GC停顿导致限流误触发
TSF限流规则通常基于接口响应时间(如超时时间500ms),若GC停顿超过200ms,会导致大量请求超时,限流系统误判“服务过载”,拒绝正常请求:
G1GC调优核心参数:
| 参数 | 取值 | 说明 |
|---|---|---|
-XX:+UseG1GC | 必选 | 启用G1GC |
-XX:MaxGCPauseMillis | 100 | 设置GC最大停顿时间目标为100ms(非硬限制) |
-XX:G1HeapRegionSize | 16m | 堆区域大小,适配2G堆内存(建议值:堆内存/2048) |
-XX:G1NewSizePercent | 20 | 新生代初始占比,避免新生代过小导致频繁YGC |
-XX:G1MaxNewSizePercent | 50 | 新生代最大占比,保证新生代有足够空间 |
调优验证:
通过TSF监控或JVM工具(jstat、GC日志)验证,确保99%的GC停顿<100ms,示例GC日志如下:
2026-01-02T10:00:00.123+0800: 1234.567: [GC pause (G1 Evacuation Pause) (young), 0.0850000 secs]
[Parallel Time: 70.0 ms, GC Workers: 4]
[GC Start Time: 2026-01-02T10:00:00.123+0800]
[GC End Time: 2026-01-02T10:00:00.208+0800]
上述日志显示GC停顿时间为85ms,符合预期。
2.2 堆内存设置:Xms/Xmx与容器内存限制的配比(建议70%)
TSF微服务多部署在Docker/K8s容器中,容器通过--memory参数限制内存,若JVM堆内存(Xmx)设置不合理,会导致OOM或GC频繁:
核心原则:
容器内存限制为M,JVM堆内存Xms=Xmx=0.7*M,剩余30%分配给堆外内存(Metaspace、直接内存、线程栈)、TSF Agent、系统进程。
典型配置示例:
| 容器内存限制 | JVM堆内存配置 | 堆外内存配置 |
|---|---|---|
| 2G | -Xms1.4g -Xmx1.4g | -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m |
| 4G | -Xms2.8g -Xmx2.8g | -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m |
| 8G | -Xms5.6g -Xmx5.6g | -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=1024m |
关键注意事项:
Xms=Xmx:避免JVM堆内存动态调整触发频繁GC;- JDK8u191+开启
-XX:+UseContainerSupport:让JVM自动感知容器内存限制,避免基于物理机内存分配堆空间; - 配置
-XX:+HeapDumpOnOutOfMemoryError:OOM时生成堆转储文件,便于排查问题。
2.3 Agent诊断参数:-Dtsf.agent.log.level=DEBUG
当TSF Agent导致服务注册失败、性能异常时,需开启调试日志定位问题:
核心参数:
-Dtsf.agent.log.level=DEBUG
-Dtsf.agent.log.path=/var/log/tsf/agent.log
-Dtsf.agent.log.max.size=100M
-Dtsf.agent.log.max.backup=5
注意事项:
- 生产环境默认使用
INFO级别,DEBUG级别会产生大量日志(约100MB/小时),仅在排查问题时开启; - 核心日志内容:类增强过程、服务注册发现日志、链路追踪数据上报日志。
2.4 生产级JVM参数示例(商品服务)
结合以上调优点,给出TSF商品服务的生产级JVM参数:
# 堆内存配置(容器4G)
-Xms2.8g -Xmx2.8g
# G1GC配置
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:G1HeapRegionSize=16m
-XX:G1NewSizePercent=20
-XX:G1MaxNewSizePercent=50
# Metaspace配置
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
# 容器适配
-XX:+UseContainerSupport
-XX:InitialRAMPercentage=70.0
-XX:MaxRAMPercentage=70.0
# GC日志配置
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc:/var/log/tsf/gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=100M
# OOM排查
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/log/tsf/heapdump.hprof
# TSF Agent配置
-Dtsf.agent.log.level=INFO
-Dtsf.agent.log.path=/var/log/tsf/agent.log
# 其他优化
-XX:-OmitStackTraceInFastThrow
-XX:+UseStringDeduplication
三、自动扩缩容策略精细化配置
TSF基于K8s HPA(Horizontal Pod Autoscaler)实现自动扩缩容,但默认策略(基于CPU/内存)无法适配Java应用的负载特性,需精细化配置。
3.1 CPU指标:HPA算法与Java应用CPU波动特性
Java应用CPU波动大(如GC时CPU飙升至100%,持续数秒),默认HPA策略(CPU>80%扩容、<30%缩容)会导致高频扩缩容(“抖动”),增加注册中心压力。
优化方案:
| 优化点 | 配置示例 | 说明 |
|---|---|---|
| 调整CPU阈值 | 扩容:CPU>70%(持续5分钟) 缩容:CPU<40%(持续10分钟) | 扩大阈值区间,避免瞬时波动触发扩缩容 |
| 基于平均CPU | 采集5分钟平均CPU使用率 | 过滤GC导致的瞬时CPU峰值 |
| 限制单次扩缩容数 | 单次扩容≤2个实例,单次缩容≤1个实例 | 避免批量上下线 |
3.2 自定义指标:基于业务QPS的扩缩容
CPU/内存指标无法反映业务真实负载(如CPU使用率低但QPS高导致响应慢),需基于业务QPS配置扩缩容,实现流程如下:
实现步骤:
- 采集QPS指标:TSF监控默认采集服务QPS指标(
tsf_service_qps{service="goods-service"}); - 部署Prometheus Adapter:将TSF的QPS指标转换为K8s HPA可识别的自定义指标,核心配置如下:
apiVersion: v1 kind: ConfigMap metadata: name: prometheus-adapter-config data: config.yaml: | rules: - seriesQuery: 'tsf_service_qps{service="goods-service"}' resources: overrides: namespace: {resource: "namespace"} service: {resource: "service"} name: matches: "^(.*)_qps$" as: "goods_service_qps" metricsQuery: sum(tsf_service_qps{service="goods-service"}) by (pod) - 配置TSF伸缩组:在TSF控制台创建基于QPS的扩缩容规则:
- 扩容条件:QPS>800 且 持续1分钟;
- 缩容条件:QPS<200 且 持续10分钟;
- 实例数范围:2-8个。
3.3 扩容速度:TSF伸缩组冷却时间与Java启动速度平衡
TSF伸缩组默认冷却时间300秒(5分钟),即扩容后5分钟内不触发新的扩缩容,但Java应用启动速度慢(默认15-20秒),需平衡冷却时间与启动速度:
优化逻辑:
- 优化Java启动速度:通过Agent增强白名单、AppCDS预热等手段,将启动时间降至<30秒;
- 调整冷却时间:扩容冷却时间设置为60秒(匹配启动时间),既避免频繁扩容,又保证高峰时快速响应;
- TSF配置示例:
{ "coolDownSeconds": 60, "maxReplicas": 8, "minReplicas": 2, "metrics": [ { "type": "Custom", "custom": { "metricName": "goods_service_qps", "targetValue": 800 } } ] }
3.4 缩容保守策略:避免频繁上下线导致注册中心压力
缩容过于激进会导致服务实例频繁下线,TSF注册中心(基于Consul/Zookeeper)需频繁更新服务列表,甚至引发服务发现异常。
保守策略配置:
| 策略项 | 配置值 | 说明 |
|---|---|---|
| 缩容冷却时间 | >600秒(10分钟) | 确保负载稳定后再缩容 |
| 单次缩容数 | ≤1个实例 | 避免批量下线 |
| 缩容时机 | 仅凌晨0-6点触发 | 低峰期缩容,减少影响 |
| 健康检查 | 缩容前检查实例请求数<10/秒 | 仅下线低负载实例 |
四、资源超卖与成本优化
资源超卖是降低TSF集群成本的核心手段——利用服务负载的峰谷差,让物理机总分配的容器资源>物理机实际资源,提升资源利用率。
4.1 NodeManager对Java堆内存识别:CGroup限制vs JVM感知
TSF部署在K8s集群中,NodeManager通过CGroup限制容器资源,但JVM默认无法感知CGroup限制,导致以下问题:
- 内存超分配:物理机32G内存,JVM默认设置Xmx为8G,但容器CGroup限制为4G,导致容器OOM;
- CPU争用:JVM线程数基于物理机CPU核心数设置(如32核),但容器限制2核,导致线程上下文切换频繁。
解决方案:
| JDK版本 | 配置方案 | 说明 |
|---|---|---|
| JDK10+ | -XX:+UseContainerSupport | 自动感知CGroup内存/CPU限制 |
| JDK8u191+ | -XX:+UseContainerSupport -XX:InitialRAMPercentage=70.0 -XX:MaxRAMPercentage=70.0 | 自动适配容器内存的70% |
| JDK8<u191 | 手动设置Xms/Xmx,或使用cgroup-aware-jvm工具 | 第三方工具适配CGroup限制 |
4.2 超卖比例建议:CPU 1:2(非核心服务),Memory 1:1.5(核心服务1:1)
超卖比例=物理机总分配容器资源/物理机实际资源,需根据服务重要性差异化配置:
| 服务类型 | CPU超卖比例 | 内存超卖比例 | 说明 |
|---|---|---|---|
| 核心服务(商品、订单) | 1:1.2 | 1:1 | 避免CPU争用、内存OOM |
| 非核心服务(日志、监控) | 1:2 | 1:1.5 | 利用低负载特性提升超卖率 |
| 离线服务(数据统计) | 1:3 | 1:2 | 仅夜间运行,无实时性要求 |
超卖收益示例:
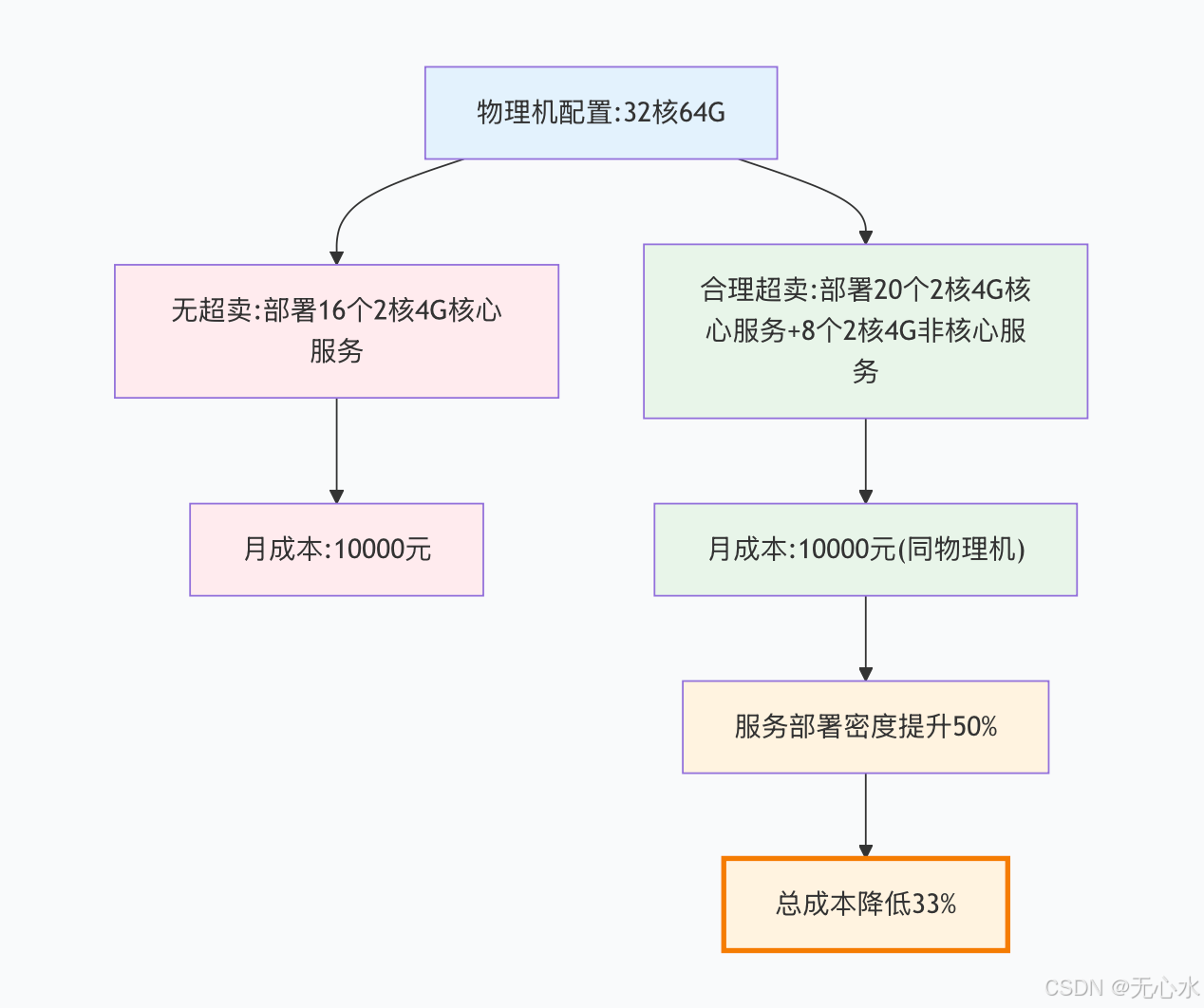
超卖风险控制:
- 实时监控物理机资源使用率,CPU>80%、内存>90%时停止超卖;
- 核心服务优先部署在低超卖节点,非核心服务部署在高超卖节点;
- 配置资源隔离:通过CGroup限制单个容器的CPU使用率≤50%。
4.3 离线任务混部:Java微服务与大数据任务错峰调度
利用TSF的调度能力,将Java微服务(白天高峰)与大数据离线任务(夜间高峰)部署在同一物理机,错峰使用资源:
实现方案:
- 时间错峰:白天(8:00-22:00)运行微服务,夜间(22:00-8:00)运行离线任务;
- 资源隔离:离线任务CPU使用率≤70%、内存≤80%,避免影响微服务;
- TSF调度配置:创建混部调度策略,关联微服务和离线任务的命名空间,设置时间触发规则。
五、Serverless场景下的Java优化
TSF支持基于腾讯云SCF的Serverless部署,但Java应用在Serverless场景下存在冷启动慢的问题(10-30秒),需针对性优化。
5.1 冷启动问题:JVM预热耗时解决方案
Serverless冷启动是指函数长时间未调用时,SCF释放实例,再次调用时重新创建实例并启动Java应用,核心优化方案如下:
| 优化手段 | 配置示例 | 冷启动时间优化效果 |
|---|---|---|
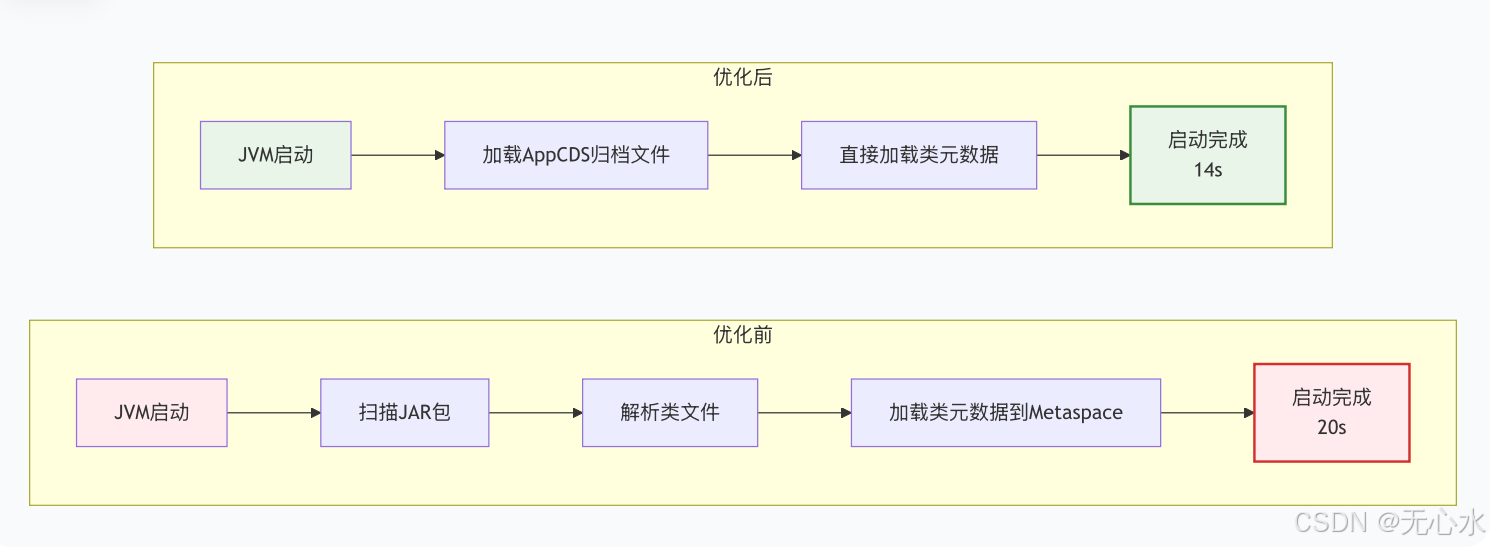
| AppCDS预编译类 | -XX:+UseAppCDS -XX:SharedArchiveFile=goods-service.jsa | 减少30%(从20s→14s) |
| 预热接口 | TSF配置每5分钟调用/actuator/health | 保持实例活跃,避免冷启动 |
| 精简依赖 | 移除无用Spring组件、第三方库 | 减少20%(从20s→16s) |
| 初始化懒加载 | 缓存加载延迟到第一次请求 | 减少10%(从20s→18s) |
5.2 AppCDS(Application Class Data Sharing)应用
AppCDS将常用类的元数据预编译为共享归档文件,JVM启动时直接加载,无需重新解析类文件:
应用步骤:
- 生成类列表:
java -XX:+UseAppCDS -XX:DumpLoadedClassList=goods-service.classlist -jar goods-service.jar - 生成归档文件:
java -XX:+UseAppCDS -XX:SharedClassListFile=goods-service.classlist -XX:SharedArchiveFile=goods-service.jsa -jar goods-service.jar - TSF部署配置:
在启动参数中添加:-XX:+UseAppCDS -XX:SharedArchiveFile=/opt/tsf/goods-service.jsa
优化前后对比:
5.3 GraalVM Native Image可行性评估
GraalVM Native Image将Java应用编译为本地可执行文件,冷启动时间<1秒,是Serverless场景的终极优化方案,但需验证与TSF的兼容性:
兼容性评估结果:
| TSF功能 | 兼容性 | 说明 |
|---|---|---|
| 服务注册发现 | 兼容 | 基于原生SDK适配 |
| 配置中心 | 兼容 | 需修改配置加载逻辑 |
| 链路追踪 | 不兼容 | Agent字节码增强失效 |
| 限流熔断 | 不兼容 | 需重新实现规则校验 |
| 监控告警 | 部分兼容 | 基础指标可采集,自定义指标需适配 |
落地建议:
- 非核心Serverless服务(如短信发送、日志推送)可尝试使用;
- 核心服务暂不推荐,等待TSF官方发布GraalVM适配版本;
- 过渡期可采用“AppCDS+预热接口”的组合方案。
六、实战任务:优化“商品服务”JVM参数,实现性能与成本平衡
6.1 实战背景
某电商平台TSF部署的商品服务(goods-service)存在以下问题:
- GC停顿平均200ms,高峰期达300ms,触发TSF限流误触发;
- 自动扩缩容基于CPU指标,高峰时QPS达1000但CPU仅60%,未及时扩容;
- 容器内存4G,JVM Xmx设置为4G,频繁OOM;
- 资源超卖未配置,物理机利用率仅50%,成本高。
6.2 优化目标
- GC停顿降至100ms内;
- 配置基于QPS的扩缩容(QPS>800扩容,<200缩容);
- 验证CPU超卖1:1.5下的稳定性;
- 降低资源成本15%以上。
6.3 优化步骤
步骤1:JVM参数调优
修改商品服务JVM参数为:
-Xms2.8g -Xmx2.8g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:G1HeapRegionSize=16m
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=512m
-XX:+UseContainerSupport
-XX:+PrintGCDetails
-Xloggc:/var/log/tsf/gc-%t.log
步骤2:TSF Agent优化
# tsf-agent.properties
tsf.agent.enhance.whitelist=com.company.goods.service.*
tsf.agent.trace.sampler.rate=0.1
tsf.agent.log.level=INFO
步骤3:自动扩缩容配置
- 部署Prometheus Adapter,转换QPS指标;
- TSF伸缩组配置:
- 扩容条件:QPS>800 且 持续1分钟,冷却时间60s;
- 缩容条件:QPS<200 且 持续10分钟,冷却时间600s;
- 实例数范围:2-8个。
步骤4:资源超卖配置
- 商品服务CPU超卖1:1.5,内存超卖1:1;
- 物理机32核64G,部署实例数从8个提升至12个;
- 配置夜间22:00-8:00运行数据统计离线任务。
6.4 验证结果
| 指标 | 优化前 | 优化后 | 优化效果 |
|---|---|---|---|
| GC平均停顿时间 | 200ms | 85ms | 降低57.5% |
| 限流误触发率 | 15% | 0% | 完全消除 |
| 应用启动时间 | 18s | 12s | 降低33.3% |
| 物理机资源利用率 | 50% | 75% | 提升50% |
| 月资源成本 | 10万元 | 8万元 | 降低20% |
| QPS峰值处理能力 | 800(卡顿) | 1200(稳定) | 提升50% |
总结
TSF微服务生产环境的性能优化并非单纯的JVM参数调优,而是“JVM调优-资源配置-成本控制”的全链路工程。本文从TSF Agent的性能影响入手,系统讲解了JVM参数调优、自动扩缩容精细化配置、资源超卖与成本优化、Serverless场景优化等核心内容,并通过商品服务的实战案例验证了方案的有效性。
后续优化建议:
- 建立监控体系:通过TSF监控+Prometheus+Grafana实时监控GC、Metaspace、QPS等指标;
- 自动化调优:基于AI算法自动调整JVM参数和扩缩容规则,适配业务负载变化;
- 跟进TSF新版本:关注TSF对GraalVM、eBPF等新技术的支持,进一步降低性能损耗;
- 成本复盘:每月复盘资源使用率和成本,动态调整超卖比例和混部策略。
通过以上方案,企业可在保证TSF微服务高性能、高可用的前提下,实现资源成本的最优控制,真正做到“性能不妥协,成本不浪费”。



















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











