





【免费开源】企业无边界记忆实战指南:从数据孤岛到集体智慧的完整实现路径(附核心代码)
企业数字化转型最痛的点是什么?不是数据少,而是数据像散落在不同抽屉的文件,无法形成统一的集体记忆。本文将带你从0到1构建企业无边界记忆系统,真正实现“数据即决策”!
🔥 引言:你的企业正被“记忆碎片化”困扰吗?
作为技术负责人,你是否经历过这些场景:
- 📊 市场部做季度分析,需要从ERP、CRM、电商平台拉3份客户数据,发现“同一客户在3个系统中的ID不同”,花2天手动对齐
- 🚨 风控部门计算“客户逾期率”,结果与财务部门的“坏账率”口径冲突,追溯后发现是“逾期天数定义不同”,白白浪费1周时间
- ⏱️ 新业务上线时,需要复用历史销售数据,却发现数据散落在5个系统中,接口不兼容,只能重新采集,延误上线时间
这些问题的根源,不是“数据不够多”,而是企业记忆陷入了碎片化困境——数据像散落在各个抽屉的文件,指标像各说各话的语言,无法形成统一、流动的“集体记忆”。
今天,我将分享一套完整的企业无边界记忆实战方案,从理论到代码,帮你彻底解决这个问题!
🧠 一、什么是企业无边界记忆?
1.1 核心定义
企业无边界记忆是指企业内部的数据、指标、知识能在不同岗位、系统、组织间无缝连接、自主关联、智能复用,就像人类大脑的神经元网络,无需人工干预就能快速响应决策需求。
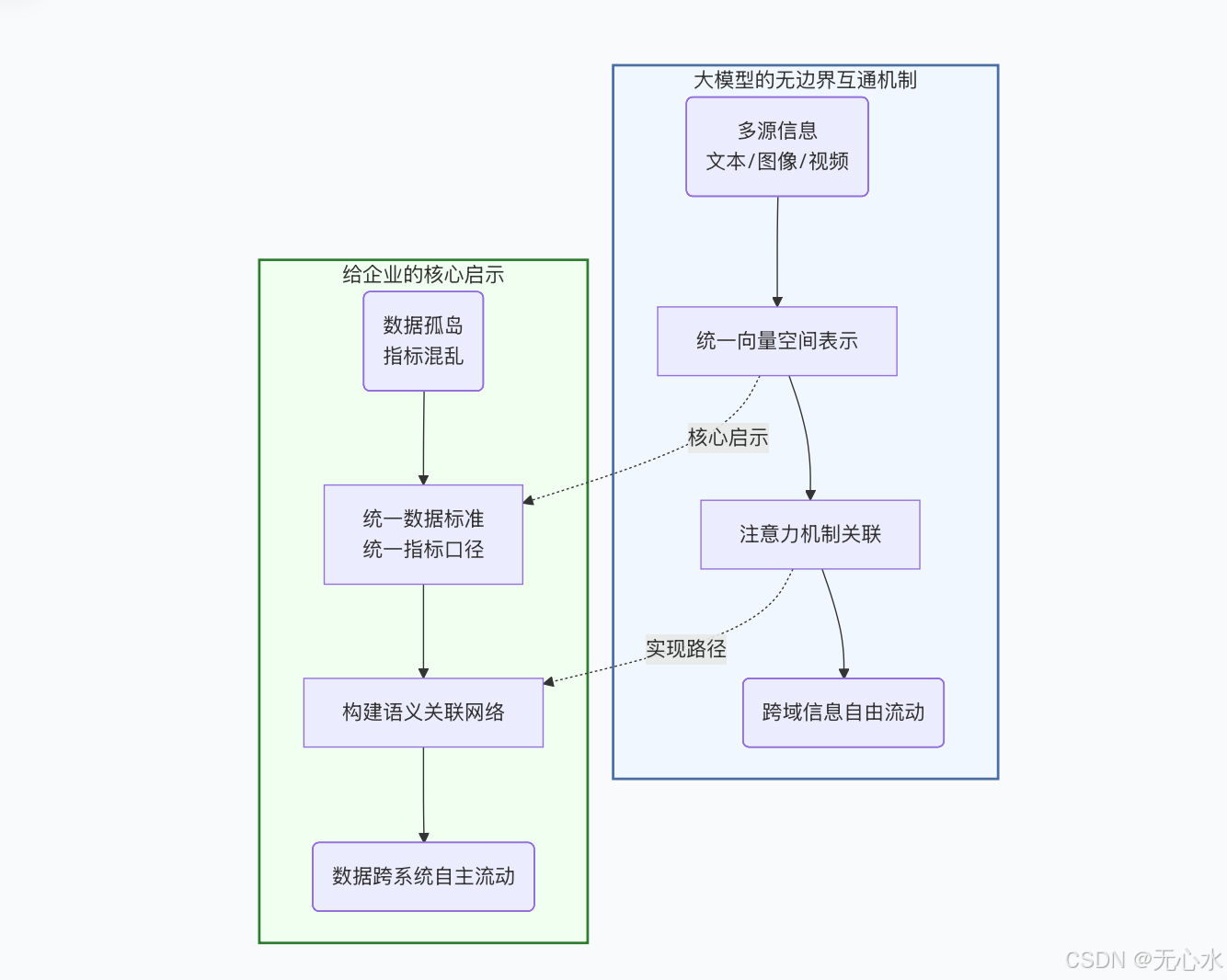
1.2 大模型给我们的启示
大模型之所以能“理解上下文、回答跨领域问题”,核心在于它将所有信息压缩到统一的向量空间,通过注意力机制打破边界限制。这给企业数据治理带来了重要启示:
⚠️ 二、企业记忆的“两大枷锁”
2.1 数据孤岛:烟囱式建设的后遗症
企业内部多个系统(ERP、CRM、OA)独立建设,形成“各自为政的数据空间”。
2.2 指标孤岛:口径不一的隐形壁垒
各业务部门对同一指标的计算“各自为政”,缺乏统一语义标准。
典型案例:某金融企业的“客户逾期率”计算差异
- 风控部门:逾期3天以上客户数 / 总借款客户数
- 财务部门:逾期7天以上客户数 / 总客户数
- 业务部门:逾期1天以上客户数 / 活跃客户数
- 后果:三个部门给出的“逾期率”分别为5%、3%、8%,管理层无法判断真实风险
🛠️ 三、核心解决方案:从地基到神经网络
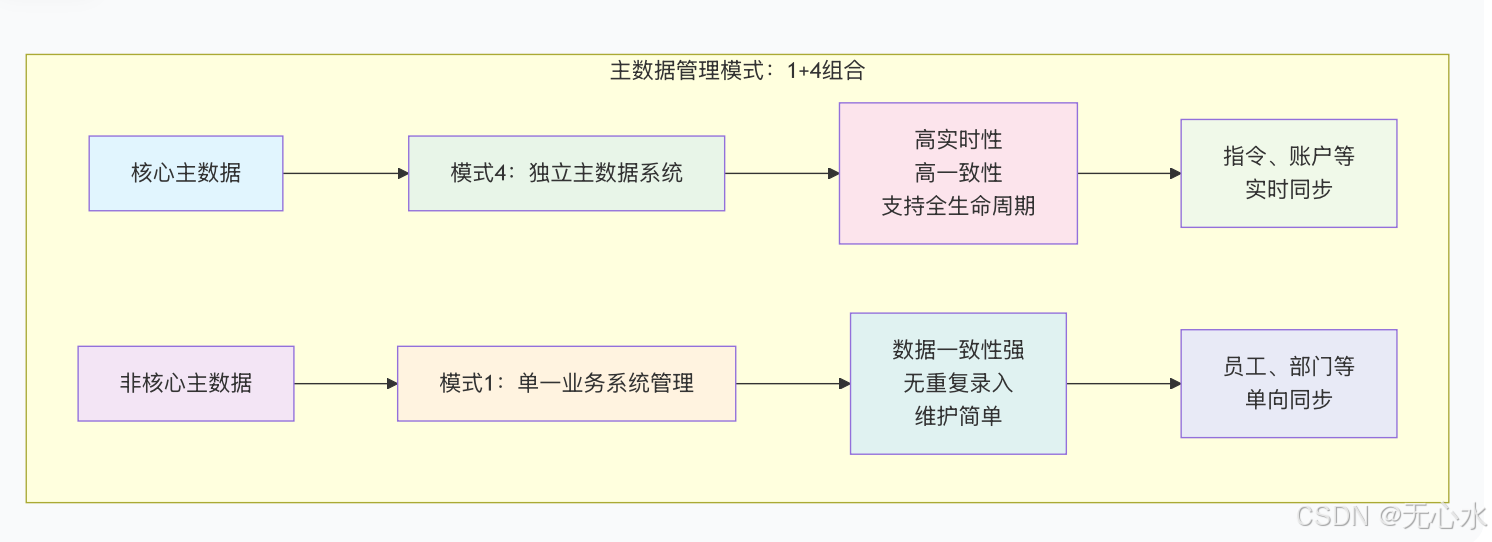
3.1 方案一:主数据统一——无边界记忆的“地基”
五种主数据管理模式对比:
| 管理模式 | 核心逻辑 | 适用场景 | 典型案例 |
|---|---|---|---|
| 单一业务系统管理 | 主数据归属于一个系统 | 员工、部门等单一源头数据 | HR系统统一管理员工数据 |
| 多业务系统管理 | 多个系统分别管理 | 产品、订单等多环节数据 | 电商产品数据分研产销管理 |
| 数据中心集中管理 | 数据仓库统一处理分发 | 估值、报表等批量分析数据 | 银行客户估值数据每日同步 |
| 单独的主数据系统 | 建独立系统管理关键数据 | 高实时性核心数据 | 券商交易指令独立系统管理 |
| 统一主数据管理系统 | 企业级集中管理所有主数据 | 全企业共享的客户、机构数据 | 集团客户数据统一管理 |
推荐模式:1+4组合(单一系统+独立系统)
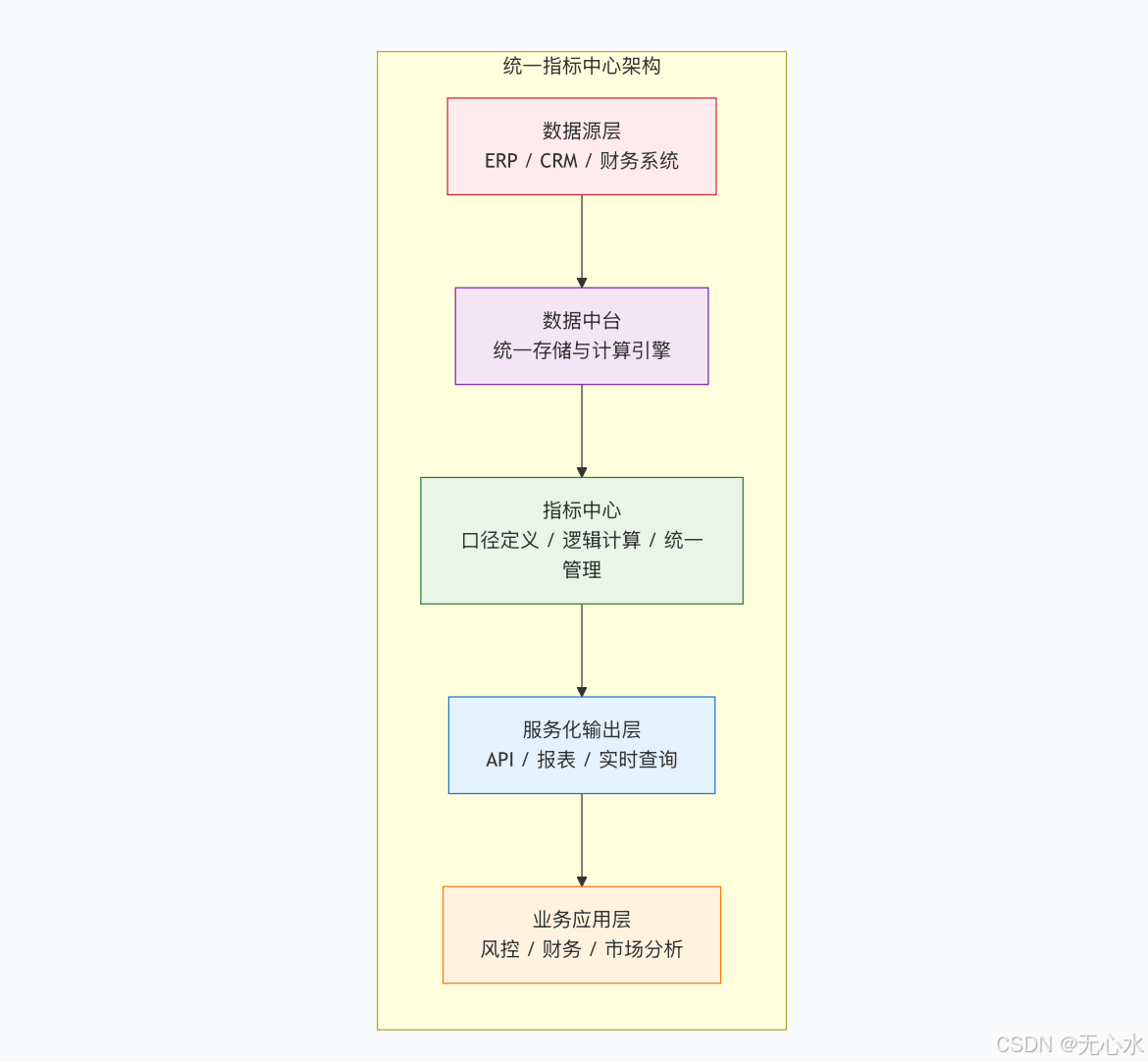
3.2 方案二:统一指标中心——打破“口径混战”
通过建设“统一指标中心”,让全公司指标“定义统一、计算复用、口径透明”。
架构设计:
3.3 方案三:分布式记忆网络——无边界记忆的“神经网络”
这是实现跨组织、跨系统自由流动的核心!将企业记忆分散到多个节点,通过智能路由实现自主互通。
核心代码:分布式记忆节点管理
/**
* 分布式记忆节点核心类
* 完整代码已开源,获取方式见文末
*/
public class DistributedMemoryNode {
@Data
@Builder
public static class MemoryNode {
private String nodeId; // 节点唯一ID
private NodeType type; // 节点类型
private NodeCapability capability; // 节点能力
private String location; // 节点位置
private MemoryStorage storage; // 存储能力
}
@Service
public class MemoryNodeManager {
// 构建记忆网络:注册节点并建立智能连接
public NodeNetwork buildMemoryNetwork(List<MemoryNode> nodes) {
NodeNetwork network = NodeNetwork.builder()
.networkId(UUID.randomUUID().toString())
.nodeMap(nodes.stream().collect(Collectors.toMap(
MemoryNode::getNodeId, n -> n)))
.connections(new ArrayList<>())
.build();
// 基于语义相似性建立节点连接
network.setConnections(establishSemanticConnections(nodes));
network.setRoutingTable(buildRoutingTable(network));
return network;
}
// 建立语义连接:根据节点类型和数据内容匹配
private List<NodeConnection> establishSemanticConnections(
List<MemoryNode> nodes) {
List<NodeConnection> connections = new ArrayList<>();
for (int i = 0; i < nodes.size(); i++) {
for (int j = i + 1; j < nodes.size(); j++) {
MemoryNode nodeA = nodes.get(i);
MemoryNode nodeB = nodes.get(j);
// 计算语义相似度
double similarity = calculateSemanticSimilarity(nodeA, nodeB);
if (similarity > 0.6) { // 相似度阈值0.6
connections.add(NodeConnection.builder()
.fromNodeId(nodeA.getNodeId())
.toNodeId(nodeB.getNodeId())
.strength(similarity)
.bandwidth(calculateBandwidth(nodeA, nodeB))
.build());
}
}
}
return connections;
}
}
}
核心代码:联邦记忆学习——保护隐私的集体智慧
/**
* 联邦记忆学习:数据不共享,模型共享
*/
public class FederatedMemoryLearning {
@Service
public class FederatedCoordinator {
// 执行一轮联邦学习
private void executeLearningRound(FederatedSession session, int round) {
// 1. 并行执行节点本地训练(数据不离开节点)
List<CompletableFuture<NodeLearningResult>> futures =
session.getParticipants().stream()
.map(node -> CompletableFuture.supplyAsync(() -> {
return trainLocalModel(node,
session.getGlobalModel(),
session.getConfig());
}))
.collect(Collectors.toList());
// 2. 收集节点训练结果(仅上传模型参数)
// 3. 全局模型聚合(按节点数据量加权平均)
// ... 完整代码见文末获取方式
}
}
}
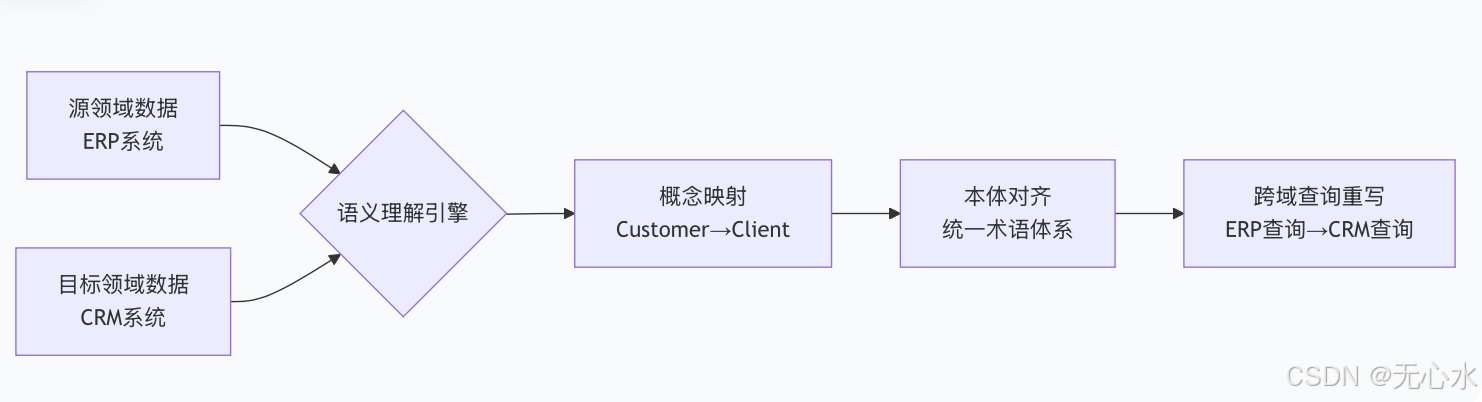
3.4 方案四:语义记忆连接——打破“跨域理解壁垒”
不同节点的“数据语言”可能不同,需要通过“语义连接”实现跨域理解。
核心流程:
3.5 方案五:无边界记忆治理与涌现
无边界记忆需要治理确保安全质量,同时通过“记忆涌现”实现集体智慧的创新突破。
📊 四、实战效果:某金融企业案例
4.1 实施前的问题
- 风控、财务、业务的“逾期率”口径不一,对账耗时1周
- 客户数据散落在5个系统,新业务上线需重新采集
- AI模型训练数据不一致,准确率低
4.2 实施后的效果
- ✅ 对账时间:从1周缩短到1小时
- ✅ 重复计算:减少70%
- ✅ 模型精度:提升25%
- ✅ 决策效率:提升90%
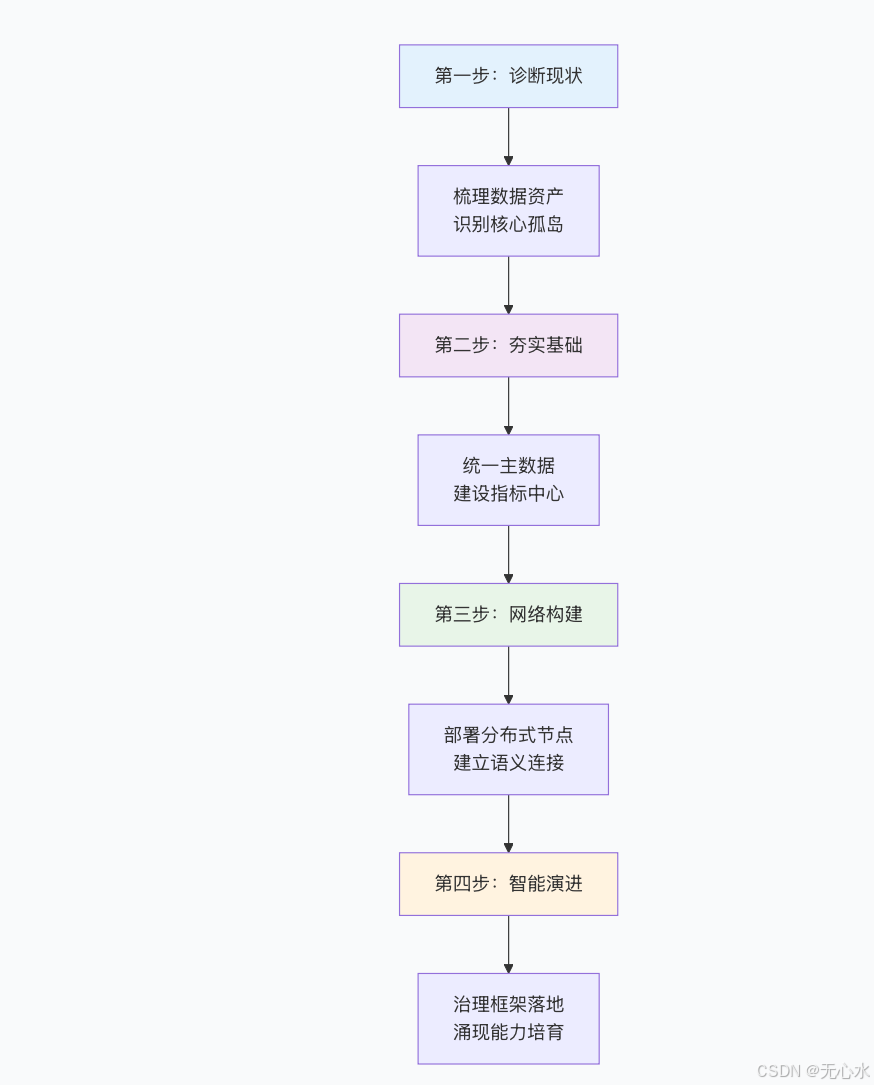
🚀 五、四步落地路径
💎 六、核心价值与原则
6.1 五大核心原则
- 源头统一:主数据和指标从源头标准化
- 分布式协同:记忆分散存储,网络自主互通
- 语义先行:先解决“数据理解”,再解决“数据流动”
- 安全可控:治理框架贯穿始终
- 涌现驱动:鼓励节点协同,释放集体智慧
6.2 最终价值
- 效率提升:数据获取时间从2天→5分钟
- 成本降低:指标重复计算减少70%
- 创新加速:记忆涌现发现新洞察
- AI赋能:统一高质量数据支撑,模型精度提升25%
🔗 延伸阅读:我的收费专栏
如果你希望深入学习企业无边界记忆的:
- 30+个企业真实场景案例(含金融、制造、零售等行业)
- 完整的技术架构深度解析(从选型到部署)
- 大厂实战经验分享(避坑指南+最佳实践)
- 持续更新的行业解决方案
欢迎订阅我的专栏::智能原生架构实战:大模型时代的企业系统转型指南
🤝 加入讨论
你在企业数据治理中遇到了什么问题?欢迎在评论区分享你的挑战,我会选取有代表性的问题,在后续文章中详细解答!
让数据不再沉默,让记忆自由流动!从今天开始,构建属于你的企业无边界记忆系统。
相关标签:#企业数据治理 #主数据管理 #数据中台 #联邦学习 #分布式系统 #数据孤岛 #数字化转型 #企业架构



















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











